
- 1【论文精读】CLIP_country211数据集
- 2python爬虫基础:使用lxml库进行HTML解析和数据提取的实践指南_python lxml解析html
- 3两个入门级例题了解动态规划(自用版,python)
- 4SQL条件语句(IF, CASE WHEN, IF NULL)
- 5【UIE模型-傻瓜式教程】飞桨AI Studio中fork实体抽取任务(打车、快递单)并运行教程_uie抽取实体
- 6「VUE架构」VUE2.0 Axios深入浅出_vue2 支持axio 版本
- 7从零开始学Spring Boot系列-集成Kafka(1)_springoot实用kafak
- 8【Array】arr.forEach()(跳出循环)_array.foreach
- 9Flink 中的Window_datastream[(string, int)].process
- 10MySQL数据库与其管理工具Navicat_数据库连接工具
ML connectors 入门指南已到,来 OpenSearch 开启文本向量化功能!
赞
踩

背景
OpenSearch 是一款开源的分布式搜索和分析套件。Amazon OpenSearch Service 是一项托管服务,可让您轻松部署、操作和扩展 OpenSearch 集群,并安全地实时搜索、监控和分析业务和运营数据,适合应用程序监控、日志分析、可观察性和网站搜索等使用场景。
ML Commons 是一个 OpenSearch 插件,它通过传输和 REST API 调用集群外部一组通用机器学习 (ML) 算法。基于这个插件您可以将 Amazon OpenSearch Service ML 连接器与亚马逊云科技服务结合使用,可以设置连接器以使用 Amazon SageMaker 和 Amazon Bedrock 在内的亚马逊云科技服务。同样的,您也可将 Amazon OpenSearch Service ML 连接器与外部其他的模型相结合,可设置连接器以包括 Cohere等外部基础模型服务。
OpenSearch Ingest Pipelines 是 OpenSearch 一种数据预处理机制,允许在数据被索引到 OpenSearch 之前对其进行转换和丰富。它由一系列处理器组成,这些处理器按顺序执行,对传入的文档执行各种操作。Ingest Pipelines 提供的处理器包含:数据转换、数据丰富、数据安全、数据规范化、数据分析等。本文中,我们可以在 Ingest Pipelines 中使用 processors type:text_embedding 并调用集群外部基础模型对插入的数据自动化 Embedding。
ML Connectors 插件配置
使用 Amazon OpenSearch Service 创建 v2.9 及以上版本的 OpenSearch 集群,并且启用精细访问控制的 Amazon OpenSearch Service 域,都提供了对 ML Commons 插件的支持。接下来,我们演示安装配置 ML Commons 插件和连接器的步骤。
1)首先,在控制台上进入到 Integrations 页面,选择一个要集成的模型。本示例中,选择 Amazon Titan Text Embeddings model,并且选择连接到域的方式采用的是 VPC domain,如下图所示。
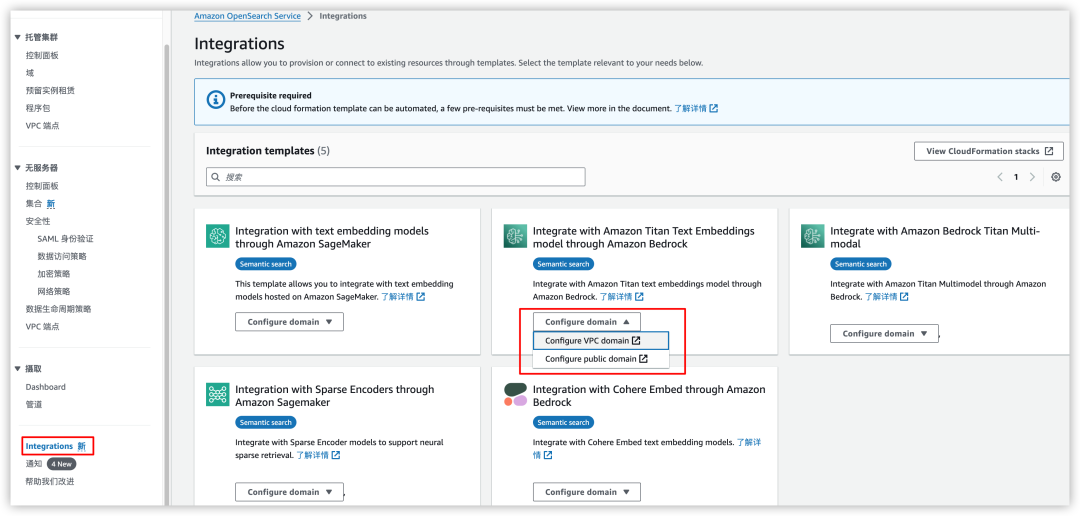
2)接下来,进入“CloudFormation”参数页面配置,参数配置中除了默认生成的,主要配置参数包含:(1)集群 Endpoint,用于连接集群的连接端点;(2)Embedding 基础模型及所在区域,示例中选择 amazon.titan-embed-text-v1 和 us-west-2;(3)安全组和 vpc 子网,这里的配置与 Amazon OpenSearch Service 域中配置的安全组和子网保持一致。如下图所示。
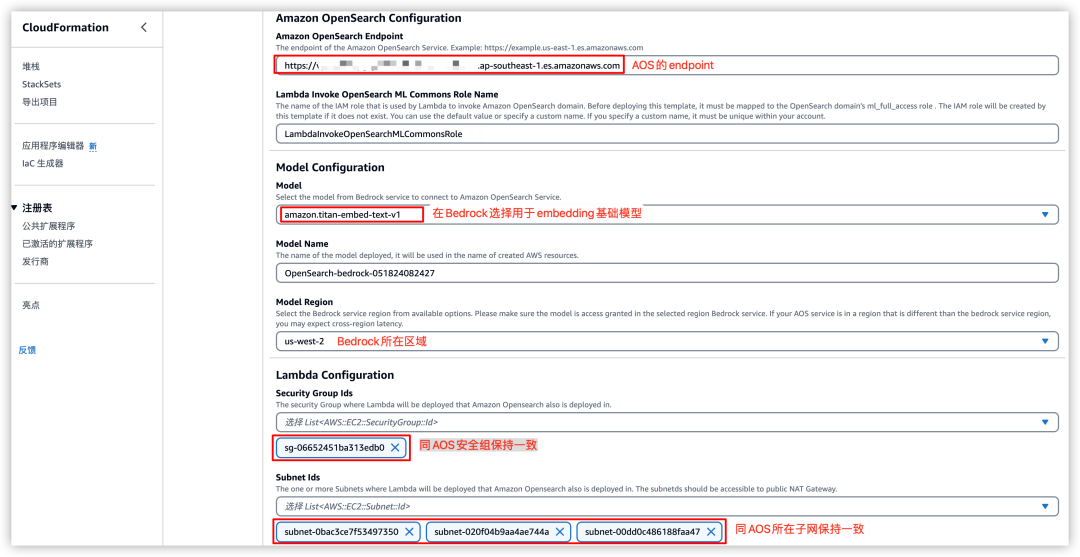
以上配置参数确认后开始创建堆栈。使用 CloudFormation 将为您快速配置 ML Commons 插件、IAM 角色及权限、Domain 中连接器及模型注册。创建成功后,将输出 Bedrock Endpoint、在 Domian 中为您创建 ML Commons 连接器 ID 和模型 ID,如下图所示:
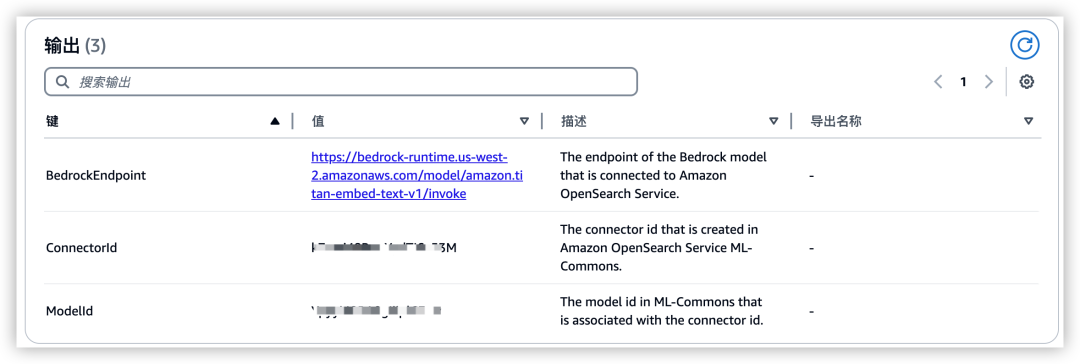
3)再接下来,我们还需要配置 OpenSearch ml_full_access 角色映射到 Lambda IAM 角色(角色是 CloudFormation 模板创建,使用默认名称 LambdaInvokeOpenSearchMLCommonsRole)。
导航到您的 OpenSearch Service 域的 OpenSearch 控制台上。您可以在 OpenSearch Service 控制台的域控制面板上找到 Dashboards 终端节点,如下图所示:
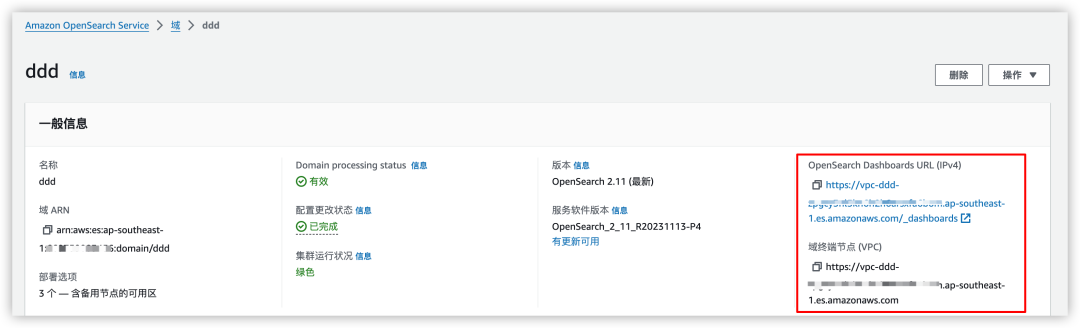
在打开的 OpenSearch Dashboards 上进入“Home” – “Security”- “Roles”。
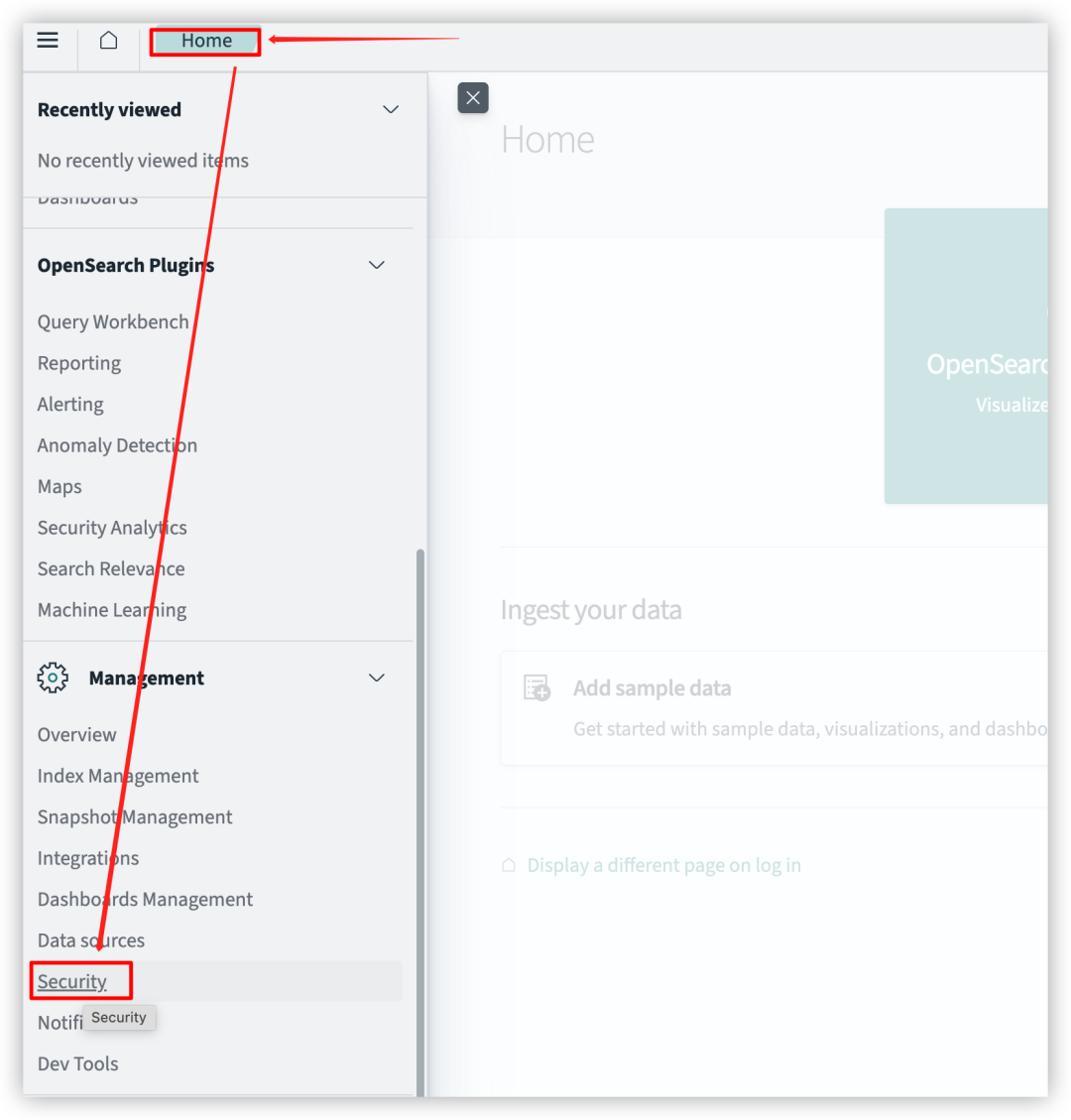
选择角色“ml_full_access”配置外部角色映射,配置映射后,让内部角色“ml_full_access”或得外部角色所拥有的权限。
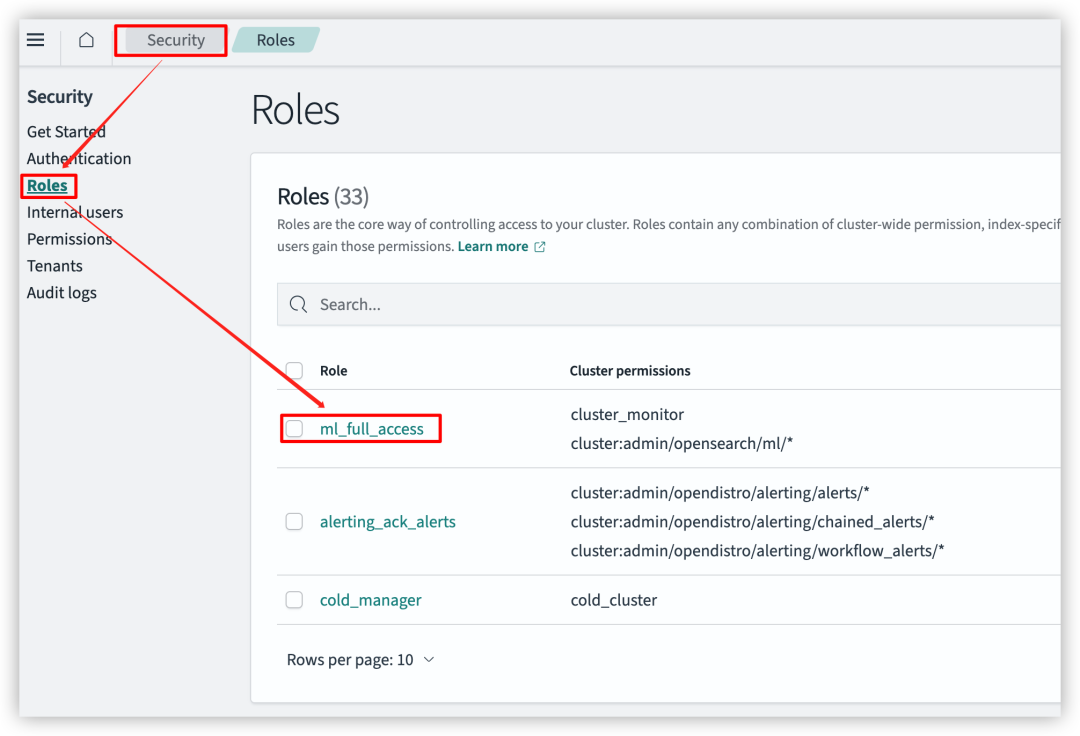
再依次选择 “Mapped users” – “Manage mapping” – “Map users”。
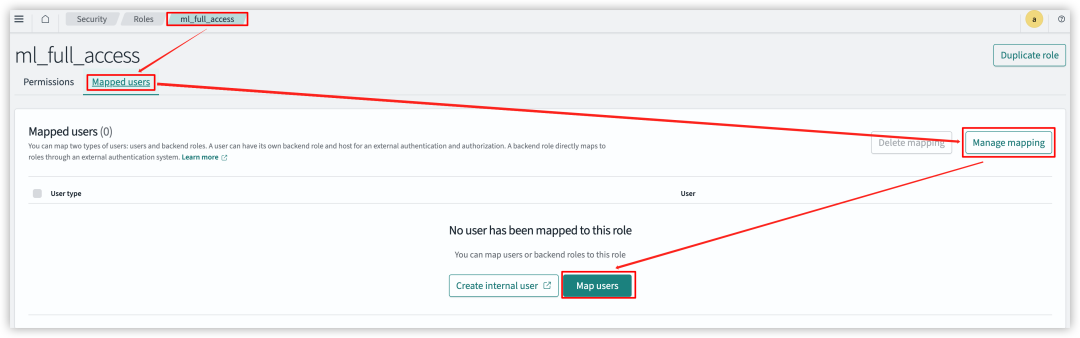
在 “Backend roles” 下,添加 IAM 角色的 ARN,例如:
arn:aws:iam::123456789098:role/LambdaInvokeOpenSearchMLCommonsRole。
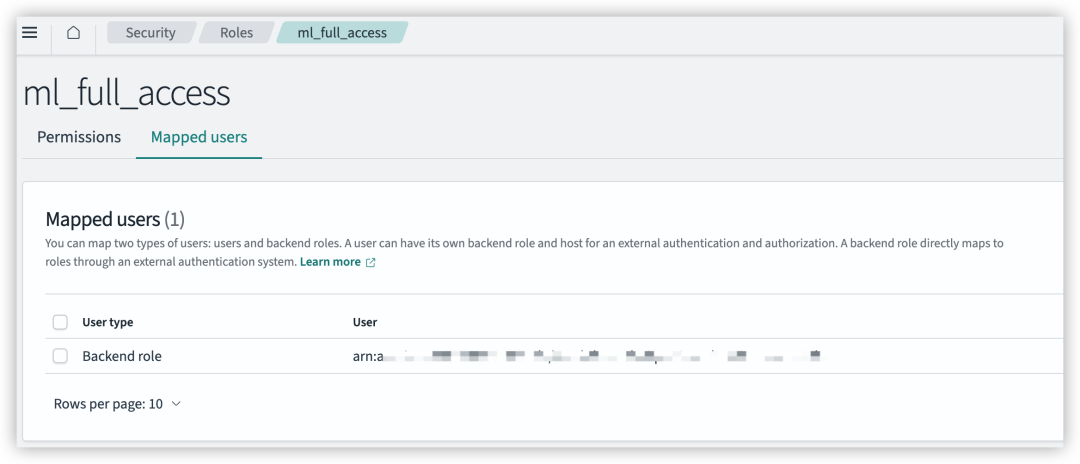
至此,完成 ML Commons 插件、IAM 角色及权限、Domain 中连接器及模型注册等配置工作。
ML Commons 插件应用
插件生效验证
1)进入 OpenSearch Dashboards,打开“Dev Tools”工具
在控制台下查看当前连接器和模型(connectors ID 和 models ID 可以在上面的 CloudFormation 输出获取)
输入命令:
- GET /_plugins/_ml/connectors/{ConnectorId} // 替换成ML-Commons ConnectorId
-
-
- GET /_plugins/_ml/models/{mode_id} // 替换为注册的 model id
左右滑动查看更多
输出结果:
- //ML-Commons 连接器内容(截取部分返回结果)
- {
- "name": "Bedrock Connector: embedding",
- "version": "1",
- "description": "The connector to bedrock embedding model",
- "protocol": "aws_sigv4",
- "parameters": {
- "service_name": "bedrock",
- "region": "us-west-2"
- },
- "actions": [
- {
- "action_type": "PREDICT",
- "method": "POST",
- "url": "https://bedrock-runtime.us-west-2.amazonaws.com/model/amazon.titan-embed-text-v1/invoke",
- "headers": {
- "x-amz-content-sha256": "required",
- "content-type": "application/json"
- },
- "request_body": """{ "inputText": "${parameters.inputText}" }""",
- "pre_process_function": """
- .......
- .......
- .......
-
- //已注册的模型内容
- {
- "name": "OpenSearch-bedrock-051824082427",
- "model_group_id": "lLmyi48BpqYydTI6AJ3K",
- "algorithm": "REMOTE",
- "model_version": "1",
- "description": "Bedrock Model for connector k7mxi48BpqYydTI6_53M",
- "model_state": "PARTIALLY_DEPLOYED",
- "created_time": 1716035651292,
- "last_updated_time": 1716259365962,
- "last_deployed_time": 1716259365962,
- "planning_worker_node_count": 3,
- "current_worker_node_count": 2,
- "planning_worker_nodes": [
- "SBYaIdcvTzKvM-yta773BQ",
- "mhceysEzQQaznoKbOkQT2Q",
- "AZ6HjgYAQWuQLhJ5fD_V5g"
- ],
- "deploy_to_all_nodes": true,
- "connector_id": "k7mxi48BpqYydTI6_53M"
- }

左右滑动查看更多
2)进一步验证模型工作状态
输入命令:
- // 验证模型
- POST /_plugins/_ml/models/{mode_id}/_predict // 替换为注册的 model id
- {
- "parameters": {
- "inputText": "What is the meaning of life?"
- }
输出结果:
- // 验证成功会返回 1536 维的向量编码(截取部分返回结果)
- {
- "inference_results": [
- {
- "output": [
- {
- "name": "sentence_embedding",
- "data_type": "FLOAT32",
- "shape": [
- 1536
- ],
- "data": [
- 0.41992188,
- -0.7265625,
- -0.080078125,
- 0.41210938,
- -0.056640625,
- 0.37890625,
- -0.059570312,
- ......
- ]
- }
- ],
- "status_code": 200
- }
- ]
- }
左右滑动查看更多
插件简单使用
1)创建一个命名为“movies”的索引。在索引里定义一个向量类型的字段(overview_vector),还设置索引支持 knn 算法(”index.knn”: true)以及默认的 pipeline( “default_pipeline”: “imdb-top-en-nlp-ingest-pipeline”)
输入命令:
- //创建新索引
- PUT /movies
- {
- "aliases": {},
- "settings": {
- "index.knn": true,
- "default_pipeline": "imdb-top-en-nlp-ingest-pipeline"
- },
- "mappings": {
- "properties": {
- "title": {
- "type": "text",
- "store": true
- },
- "year": {
- "type": "text",
- "store": true
- },
- "rating": {
- "type": "text",
- "store": true
- },
- "runtime": {
- "type": "text",
- "store": true
- },
- "genres": {
- "type": "text",
- "store": true
- },
- "imdb_rating": {
- "type": "text",
- "store": true
- },
- "overview": {
- "type": "text",
- "store": true
- },
- "overview_vector": {
- "type": "knn_vector",
- "dimension": 1536,
- "method": {
- "name": "hnsw",
- "space_type": "cosinesimil",
- "engine": "nmslib"
- }
- }
- }
- }
- }
左右滑动查看更多
输出结果:
- {
- "acknowledged": true,
- "shards_acknowledged": true,
- "index": "movies"
- }
2)创建 OpenSearch Ingest Pipelines。用于自动化调用 ML Models 对字段“overview”向量化后赋值给“overview_vector”
输入命令:
- //创建pipline
- PUT _ingest/pipeline/imdb-top-en-nlp-ingest-pipeline //pipline名称将被用在上面的创建索引时引用
- {
- "description": "Text embedding pipeline",
- "processors": [
- {
- "text_embedding": {
- "model_id": "{mode_id}",// {model id}替换为注册的 model id
- "field_map": {
- "overview": "overview_vector"
- }
- }
- }
- ]
- }
左右滑动查看更多
输出结果:
- {
- "acknowledged": true
- }
3)向索引插入数据
输入命令:
- //向索引插入一笔数据
- post /movies/_doc/
- {
- "title": "The Shawshank Redemption",
- "year": "1994",
- "rating": "R",
- "runtime": "142 min",
- "genres": "Drama",
- "imdb_rating": "9.3",
- "overview": "Two imprisoned men bond over a number of years, finding solace and eventual redemption through acts of common decency."
- }
左右滑动查看更多
输出结果:
- {
- "_index": "movies",
- "_id": "ZpwxmY8BA8gIiipl0ky-",
- "_version": 1,
- "result": "created",
- "_shards": {
- "total": 3,
- "successful": 3,
- "failed": 0
- },
- "_seq_no": 1,
- "_primary_term": 1
- }
4)验证结果,查询“movies”索引。预期的结果是字段“overview_vector”存储着已向量化后的“overview”。
输入命令:
- //查询刚插入的数据
- GET /movies/_search
- {
- "query": {
- "match": {
- "overview": "redemption"
- }
- }
- }
输出结果:
- // 验证成功会返回 1536 维的向量编码(截取部分返回结果)
- {
- "took": 3,
- "timed_out": false,
- "_shards": {
- "total": 5,
- "successful": 5,
- "skipped": 0,
- "failed": 0
- },
- "hits": {
- "total": {
- "value": 1,
- "relation": "eq"
- },
- "max_score": 0.2876821,
- "hits": [
- {
- "_index": "movies",
- "_id": "Z5w3mY8BA8gIiipl-UzI",
- "_score": 0.2876821,
- "_source": {
- "overview": "Two imprisoned men bond over a number of years, finding solace and eventual redemption through acts of common decency.",
- "overview_vector": [
- 0.091796875,
- -0.103515625,
- 0.9375,
- 0.18359375,
- -0.3359375,
- ......
- ],
- "year": "1994",
- "genres": "Drama",
- "rating": "R",
- "runtime": "142 min",
- "title": "The Shawshank Redemption",
- "imdb_rating": "9.3"
- }
- }
- ]
- }
- }
左右滑动查看更多
至此,验证完毕。
总结
本文作为 ML connectors 插件的入门指南,介绍了如何在 Amazon OpenSearch Service 中配置和使用 ML Commons 插件以及 Amazon Bedrock 文本向量化模型。通过集成 ML Commons 插件和基础模型服务(如 Amazon Bedrock),可以在 OpenSearch 中方便地使用预训练的机器学习模型进行文本向量化、语义搜索等高级功能,极大扩展了 OpenSearch 的应用场景。同时,Ingest Pipeline 机制使得在数据索引前就可以自动完成文本向量化等预处理,提高了效率和可扩展性。
本篇作者

柯俊雄
亚马逊云科技解决方案架构师,专注于数据分析和容器化领域。

张盼富
亚马逊云科技解决方案架构师,从业十三年,先后经过历云计算、供应链金融、电商等多个行业,担任过高级开发、架构师、产品经理、开发总监等多种角色,有丰富的大数据应用与数据治理经验。加入亚马逊云科技后,致力于通过大数据+AI 技术,帮助企业加速数字化转型。

庄颖勤
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案架构设计、咨询、实施等工作。在 DevOps、CI/CD 和容器等领域拥有丰富的技术和支持经验,致力于帮助客户实现技术创新和业务发展。

孟祥智
亚马逊云科技解决方案架构师。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客,获得更详细内容

