
- 1百度智能云正式上线Python SDK版本并全面开源!_bce-python-sdk库
- 2币区块结构解析
- 3数据处理领域有OLTP和OLAP两大类型_oltp数据库有哪些
- 4大数据基础hadoop / hive / hbase_hadoop hive hbase
- 5结构体(struct)继承——[C++语言中]_结构体继承
- 6Unity PackageManager无法下载github包的问题_unity 下载git报错
- 7Hadoop启动正常,能ping通,无法打开hadoop102:9870_hadoop9870打不开
- 8《系统架构设计师教程(第2版)》第3章-信息系统基础知识-05-专家系统(ES)_es专家系统
- 9No module named _sqlite3解决方案_no module named'sqlite3
- 10【数据结构】队列的应用(详解)
文心一言用户达3亿!文心大模型4.0 Turbo发布,支持API,真GPT-4 Turbo国产来了!_文心一言4tur
赞
踩
文心一言用户规模达到3亿了!
这是笔者在今天的百度Wave Summit 2024大会上的看到的数字。需要强调的是,文心一言的用户规模是在去年12月破亿的。这意味着,仅仅隔了6个月,文心一言用户数量在亿这个级别的数字上竟然直接翻了三倍。
近几年,大家常说,数亿规模的C端AI产品机会不多了,而百度,则是第一个拿到大型AI ToC端应用船票的公司。
看到这里你可能想问,凭什么呢?
这个答案并不复杂。
今天Wave Summit上笔者看到百度CTO王海峰讲述了历代工业革命的特征。他表示,纵观前三次工业革命,其核心驱动力量机械技术、电气技术和信息技术都有很强的通用性,会应用于各行各业,当它们呈现出标准化、自动化和模块化的工业大生产特征,核心技术就进入工业大生产阶段。
王海峰认为,人工智能基于深度学习及大模型工程平台,包括算法、数据、模型、工具等,也已经具备了非常强的通用性,并具备了标准化、模块化和自动化的特征,推动人工智能进入到了工业大生产阶段,通用人工智能将加速到来。
这种技术上的强大通用性也是迎来产业进入爆发期的技术支撑。
从笔者的视角来看,百度显然是在AI生态中构建护城河最深的玩家,从自研的深度学习框架、海量多样的互联网数据积累到深厚的AI算法和工程积累,加之搜索引擎从诞生那一天起就在为理解和满足国内数亿网民的需求而持续迭代,因此文心一言成为国内最早破圈到如今如此大体量用户的AI应用,也就很好理解了。
而要支撑起文心一言3亿用户的盘子,效果+效率是两个要同时达到的条件。
效果层面不必多说了,文心4.0大模型是国内最早能力比肩GPT-4的国产模型。
而今天,Wave Summit上则直接发布了一个在效果+效率“双杀”的基础上,大幅强化检索能力的文心大模型——文心大模型4.0 Turbo!

这个文心大模型4.0 Turbo,不仅可以通过文心一言的网页端和APP端使用,它还一如既往的面向开发者提供了API支持!企业用户现在就能使用了,登录百度智能云千帆大模型平台使用就能体验啦。
笔者也是第一时间体验到了文心4.0 Turbo版——
值得强调的是,文心4.0Turbo模型大幅强化了检索能力,这意味着大模型幻觉的问题,在文心4.0Turbo面前能大大的缓解,模型回答的可信度会好很多。
笔者体验了一下文心4.0Turbo后,第一感受是生成速度明显快太多了!
来,放个gif(无加速)你们感受下:

如果你用过其他同类产品,你一定会像我一样惊呼“wok!”
市面上大部分同类产品,光在背后生成搜索词、完整初始的搜索结果的富集,往往就需要数秒时间;
之后,分析搜索结果又是数秒;再将处理结果加工成大模型的输入信息传给大模型,等大模型返回第一个字,往往又是秒级。
而你们看文心4.0 Turbo的速度,全网搜索、分析资料、等待大模型回复这三步几乎一气呵成,笔者自己通过对比几轮下来,感觉每一步都是一个10倍+的效率提升。而在正文的输出速度上也要明显快于上一代文心4.0模型。
对于效率党,这个体验加分。
如果你跟笔者一样,是技术背景出身,你一定能从这感受到这背后是百度技术团队领先业界的工程能力。
而你如果要问,它怎么做到这么快的?
我想,从Wave Summit上马艳军老师的分享中可以窥见一二——
我们知道,驱动大模型推理速度提升的,不止是显卡的好坏,更重要的是底层的深度学习技术框架。
而国内的大模型厂商中,唯有百度拥有自研的深度学习框架——飞桨,而且是深度学习框架中的“国货之光”,在性能上丝毫不输PyTorch和TensorFlow等国外深度学习框架。
如今,飞桨承担起了给文心一言提供强大底层框架支撑的使命,并且已经在引领大模型推理框架方面的底层技术创新了。

例如,仅Wave Summit上公布的飞桨编译器自动融合算子的技术,就能将生成式模型的推理性能直接提升30%。
除此之外,飞桨在Wave Summit上公开的黑科技实在太多了,例如飞桨还提出了训推一体的统一表示,这种中间表示不仅有利于推理优化,而且能大幅降低大模型的开发成本,比使用PyTorch等国外主流深度学习框架要高效的多,实现大模型更快的迭代。
扒完了文心4.0 Turbo模型为什么速度这么快,再来聊聊文心4.0 Turbo的效果。
先说结论,文心4.0 Turbo不仅速度比文心4.0快,而且效果也更好。
贴个case感受下:
文心4.0 Turbo的结果和文心4.0的结果分别如下:


如果你要问为啥速度快了,效果还能更好。我觉得终极答案还是要归因到百度的技术基因上。
而拆开来看的,一方面数据决定模型的效果上限,数据的规模和质量同步提升是一定的,在此基础上,SFT、RLHF等大模型训练策略也在持续调优,这些是比较常规的优化。
而笔者自己用下来,我感觉这里的“检索增强”是文心4.0Turbo体感上最明显的提升,对于这个提升笔者也不意外。毕竟你要问搜索引擎的核心技术哪家最强,我想这个答案是不必多说的。
除此之外,文心4.0 Turbo在智能体方面的能力也得到了强化。而提到智能体,我必须要给你们share一个在Wave Summit现场听到的非常有社会意义的一个智能体——“农民院士”智能体。

这个智能体是中国工程院朱有勇院士团队与百度共同打造的,学习了朱院士的研究成果和农业知识,可以为农民解答生产生活中的问题,有效地打破了农民获取农业知识的信息差。
智能体是生成式人工智能非常重要的发展方向。如果类比为互联网时代的网站,当时网站做出来的路径是,通过浏览器看到源代码,稍微改改就能再做出1个以及更多网站。现在,基于大模型作为能力底座,智能体开发的过程也会像网站一般简单。智能体是AI时代的网站,将会有几百万、甚至大量的智能体出现,形成生态。
而这数百万智能体将在千行百业里诞生,这个“农业院士”智能体就是其中之一,亦是农业行业的智能体代表。从这个角度来说,智能体确实很像AI时代的”网站”,能用极低的成本来更好的满足大众的需求。而像这样的“网站”,在文心生态里已经达到了恐怖的55万个。

百度Comate发布中文名,条条切中程序员的痛点——文心快码来了
最后,还得分享给你们一个Wave Summit上的彩蛋——
你们关心的智能代吗助手comate有了中文名字,并且成功加入到了文心家族中——新名字是,“文心快码”。

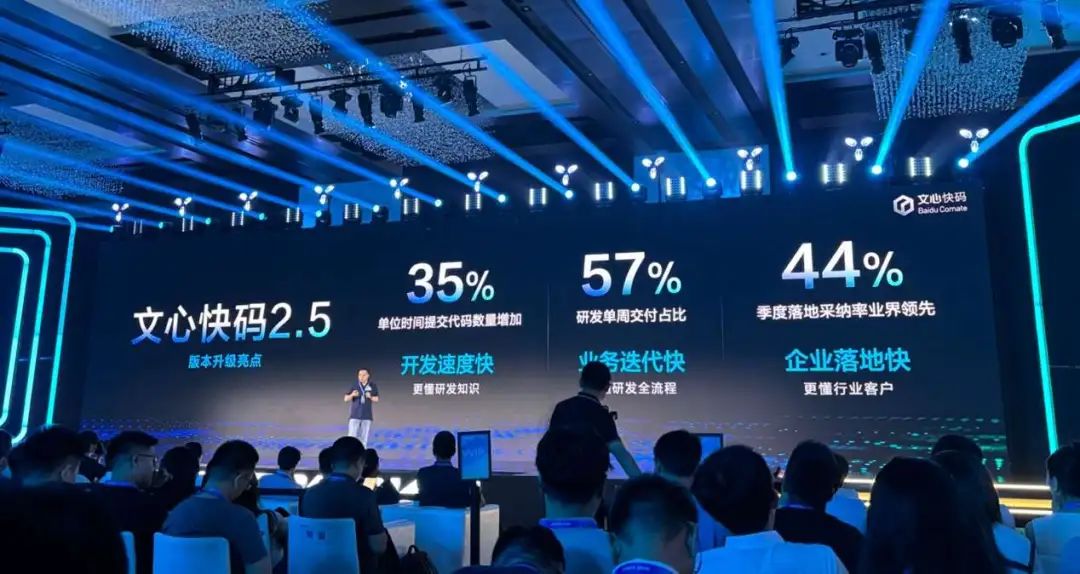
当然,除了新增中文名外,更重要的是,这次的Comate助手还重磅发布了全新的2.5版本。
给你们划个重点:
-
可以深度地解读代码库,是整个代码库,不是代码的片段
-
可以关联权威的公域和私域代码知识(根据笔者的理解,类似于检索增强),并据此生成全新的代码
-
生成的代码更加安全,并且在coding的过程中可以智能检测安全漏洞,提供智能修复的建议、一键修复漏洞
-
从研发需求调研、设计、编码、测试、部署等开发全流程赋能,不止是开发环节。
可以说,条条切中程序员的痛点啊,文心快码的这些优势也是单一的AI大模型所难以实现或实现效率很低的,像编程这样垂直、门槛高的领域,不如直接使用专业的大模型智能编程工具更为省心。
根据百度官方提供的数据,使用文心快码后,研发的各个环节都有显著的提效,整体端到端研发效率可以提升14%。不要小看这14%,你乘以每天的8小时来说,这意味着我们就能多出来一小时的时间摸鱼(不是,思考复盘研发任务)。
最后感叹一下。
作为一个每年Wave Summit必蹭的百度粉,笔者深刻的感受到今年跟去年很不一样了。
如果说2023年大家都在比拼“国产大模型底座谁的能力更接近GPT-4”,那么2024,显然牛逼的大模型厂商已经不满足于追赶OpenAI、卷大模型榜单了,而是在持续迭代基础模型技术能力的基础上,不断做大落地规模,而且已经悄然构建起了AI生态护城河,走出来自己的路。


