
- 1大数据知识点总结_大数据总结
- 2小生意赚钱小妙招,包括自媒体如何出爆款!_微商怎么做
- 3在 CentOS 7 上安装 Docker 并安装和部署 .NET Core 3.1_centos7安装docker
- 4LangChain 工程架构解析_langchain框架解析
- 5windows 显示苹果分区_让你的联想电脑也可以用上苹果系统
- 6python turtle绕原点旋转_「加德老师与小朋友们的编程之旅」Python海龟作图(上)
- 7数据分析软件之SPSS、Stata、Matlab_spss和stata
- 8测试用例编写规范
- 9python语言与c语言编写的程序文件的后缀名分别是什么_C语言中的源程序文件和目标文件的扩展名分别是...
- 10【在FastAPI应用中嵌入Gradio界面的实现方法】如何在有一个Fastapi应用的基础上,新加一个gradio程序_gradio fastapi
一文告诉你如何做数据库技术选型_数据库选型方案
赞
踩
目录
一、对象的本质——内存中
二、对象的本质——关系数据库中
三、NoSQL数据库
四、业界主流的两种数据库实现模式
五、补充思考
六、扩展
前言
灵感和理论支持来自于《NoSql精粹》
《NoSQL精粹》介绍
《NoSQL精粹》一书由著名软件开发专家Martin Fowler所著,其最为人熟知的作品包括《重构:改善既有代码的设计》和《UML精粹》。该书前半部分详细阐述了NoSQL数据库的兴起背景及其设计原理,并对不同类型的NoSQL数据库进行了概述。后半部分则深入探讨了各类NoSQL数据库的基本操作方法,以及如何实现包括一致性、事务处理、可用性、查询功能和可扩展性在内的关键特性。此书适合作为科普性质的入门读物,有助于读者在选择数据库类型时形成初步见解。
在接下来的讨论中,我将结合书中的理论知识与个人实践经验,深入探讨数据库技术选型的本质问题。
一、对象的本质 —— 内存中
一个对象的本质是什么,比如Java的一个POJO类,
它的实例是不是可以视为一个固定key值的Map,
public class Order {
private int orderId;
private String orderName;
}
Order order = new Order();
order.setOrdreId(1);
order.setOrderName("订单A");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
那么我们不妨大胆一点,如果key值也不固定,key的数量也不固定他会变成什么,一个纯粹的Map键值对。
Map<String, Object> orde = new HashMap<>();
order.put("orderId", 1);
order.put("orderName", "订单A");
- 1
- 2
- 3
内存的键值对最合适的文本描述是json文件
{
"orderId": 1,
"orderName": "订单A"
}
- 1
- 2
- 3
- 4
那么是不是可以直接用json表示对象实例呢,答案是有的,NoSql数据库中的文档型数据库是这么实现的。
不用事先修改结构定义,自由添加字段,处理不规则的数据。
二、对象的本质——关系型数据库中
阻抗失谐
内存中对象的本质中举的例子,在对象的值都是基础类型的状态下,内存对象表现简洁而优雅。
但是在对象有嵌套关系下,其表现则显得不那么适宜,这种差异就叫阻抗失谐。
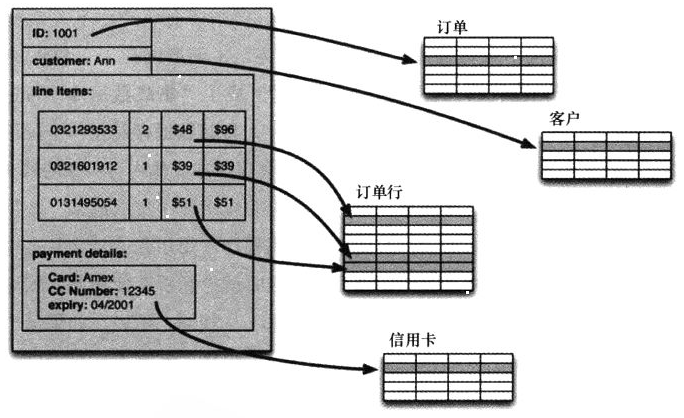
ORM对象-关系映射框架,比如著名的Hibernate和Mybatis,可以部分解决阻抗失谐问题,但是在对响应时间敏感的场景,过于依赖ORM查询性能会下降。
三、NoSQL数据库
技术背景
集群迁移导致的问题
随着大型企业向集群迁移,产生了一个新的问题,关系型数据库并不是设计给集群使用的。
哪怕是支持集群的Oracle RAC或者SQL Server这种适用于集群的关系数据库,依赖一种名为"共享磁盘子系统(shareddisk subsystem)"的概念才能运行,本质上这两个数据库可以视为是一个大磁盘上部署的单机关系型数据库。
NoSQL数据库天生支持分布式的优势
NoSql(除了图数据库)之外,天生支持分布式。而且和《内存中对象的本质》提到的例子一样,
不用事先修改结构定义,自由添加字段,处理不规则的数据。
对比
E-R图、传统的关系型数据库,存储结构更像关系表。
nosql存储结构更像内存模型中实际状态。
优势
可以说都是基于关系型数据库在分布式时代的缺陷针对设计的。
- 灵活的数据模型:如上文对象的本质所说,NoSQL数据库结构非常灵活,可以适应快速变化的业务需求和不断演进的数据结构。
- 高可扩展性:NoSQL数据库的聚合数据采用分布式架构和水平扩展的设计能够满足业务的快速增长需求。
- 高性能:NoSQL数据库通常采用内存存储和索引技术,以及并行计算和分布式计算技术,提供高性能的数据存储和查询能力。在对数据进行读取和写入操作时,NoSQL数据库可以快速响应,提供低延迟的数据访问。
- 高可用性和容错性:许多NoSQL系统采用冗余复制和自动故障转移机制,确保即使在部分节点失效的情况下也能保持服务的高可用性和数据安全性。这使得NoSQL数据库在处理大规模数据和关键业务时具有更高的可靠性和稳定性。
- 实时大数据处理:在大数据应用中,NoSQL数据库由于其高效的批量处理能力和流式处理能力而受到青睐。它们能够快速处理和检索大量数据,满足实时分析和处理的需求。
劣势
因为选择了对关系型数据库的弱项针对性设计,那么在关系数据库原本的阵地,nosql表现就不那么好。不过关系型数据库和nosql数据库并不对立,我们可以在恰当的业务场景选择合适的技术,甚至组合在一起做混合存储。
- 强一致性与事务:NoSQL数据库通常采用最终一致性模型,这意味着数据在不同节点之间的同步可能存在延迟,从而导致数据不一致的情况。在一些对数据一致性要求较高的场景,如金融系统或事务处理系统,NoSQL数据库可能不适用。
- 缺乏标准化:NoSQL数据库种类繁多,各自采用不同的数据模型和查询语言,缺乏统一的标准化。这使得在使用和管理NoSQL数据库时需要额外的学习成本,并增加了系统的复杂性和维护成本。同时,由于缺乏标准化,NoSQL数据库之间的数据迁移和集成也可能面临困难。
NoSQL数据库分类与适用场景
关系型数据库相信有一定开发经验读者已经有了自己的一些心得。这里仅讨论需要NoSql做扩展的场景。
面向聚合
这就是提到的天生支持分布式的NoSQL数据库类别
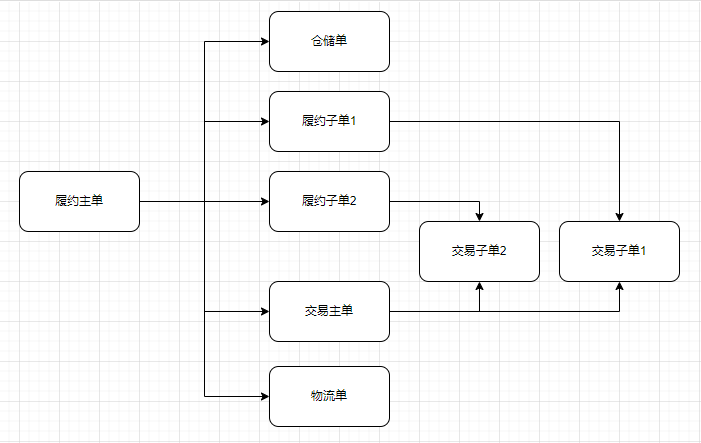
聚合是“[[DDD领域驱动设计]]”中的概念。
意为把一组相互关联的对象视为一个整体单元来操作,这个单元就叫聚合。
比如通过购物车下了一个电商订单,其中包含了主单(购物车),子单列表(每一个商品),交易单,交易子单,仓储单,物流单等。我们会通过操作主单来完成对主单子项的所有操作。在nosql中是以一个聚合为最小单位保持原子性。
NoSQL不适用的场景
1.要求强一致性
2.需要实时事务处理,如交易场景
K-V数据库
代表是老朋友redis了,**被广泛用于缓存,cookie存储,配置读取。
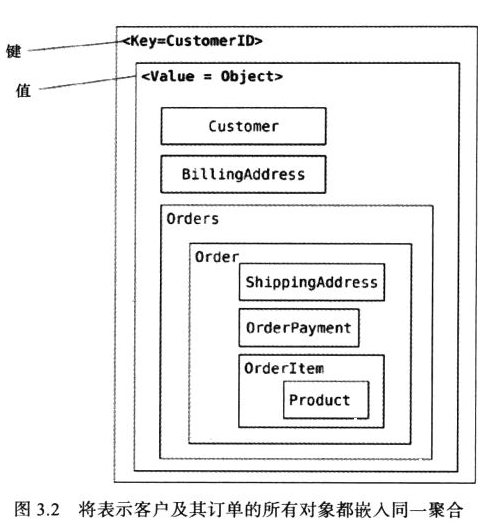
K-V存储不提供复杂的查询功能,例如JOIN操作、范围查询、全文搜索等。
虽然K-V存储允许存储任何类型的数据作为值,但它不强制或支持任何特定的数据结构。如果你的应用需要严格定义的数据结构,例如具有多个字段的记录或文档,那么文档数据库(如MongoDB)可能更合适。
KV数据库中不适用的查询场景如下,对象很大,每次只需要取出一部分的值进行运算,要根据多个字段去查找数据,而不是单一的K值。因为每次v都是被全量取出。
文档数据库
代表是ElasticSearch,MongoDB
适用场景
一般是当搜索引擎用,但其实他也是一种NoSQL数据库。适用场景非常广泛,所有非强事务ACID要求的场景都能满足。
查询领域,在全文检索,日志检索。
监控领域Elasticsearch由于其倒排索引核心算法,也是支持时序数据场景的,性能也是相当不错的,在功能性上完全压住时序数据库。
可以做一些简单的基于日志的全链路追踪
地理信息系统领域,可以做各种坐标形状范围内数据的检索,比如六边形区域内早上八点到晚上六点经过的所有车牌号。
不适用于频繁小数据量的快速查询
频繁更新的数据,由于ElasticSearch在数据更新时需要重新索引,因此在数据需要频繁更新的场景中,使用ElasticSearch可能会导致性能下降。
列式数据库
代表是clickhouse
字节,腾讯都有在用。
适用于数仓,数据分析,大量读取、少量更新和查询的场景。
业务初期,数据量少,数据库表还没完全固定,不适合列式数据库,在关系型数据库中,数据模式的修改成本很高,而这却降低了查询模式的修改成本。列式数据库则与之相反,改变其查询模式要比改变其数据模式代价更高。
不适用于高并发频繁写入修改删除的场景。
OLAP与传统的OLTP对比
OLTP
传统的OLTP(On-line Transaction Processing联机事务处理)可以狭义的理解为MySql。具有ACID(原子性、一致性、隔离性、持久性)的特性。
重点
重点在于实时处理,快速响应。
使用场景
比如银行的在线服务,强调准确、低时延、高并发。
OLAP
OLAP可以狭义的理解为clickhouse

重点
OLTP可以处理比OLAP处理规模大几个数量级的数据,能够处理涉及聚合、排序、分组和计算等复杂分析查询。
使用场景
数仓系统。
综合场景
ERP(企业资源规划)在功能上与这两者都有关联。
在数据处理方面选用OLTP
ERP系统需要处理大量的日常业务数据,包括订单处理、库存管理、财务记账等。这些处理过程通常具有事务性质,需要即时响应和准确性,因此ERP系统需要支持OLTP(联机事务处理)功能。
决策和数据分析选用OLAP
然而,除了日常业务处理外,ERP系统还需要支持管理决策和数据分析。这时,OLAP(联机分析处理)技术就显得尤为重要。OLAP技术可以对ERP系统中的数据进行多维度的分析和查询,包括销售额、销售数量、产品类型、地区、时间等维度的数据。帮助企业管理层了解业务情况,以洞察销售趋势改进产品、识别畅销产品提前备货、发现地区差异,实行差异化定价和促销策略等,从而为决策提供支持。
小结
OLAP处理数据,OLTP分析数据。
非聚合
图数据库
它是细分领域的最优解。
适用场景:社交网络,产品偏好,个性化推荐。
不适用于需要集群部署。适用场景以外的其他所有场景。
代表是Neo4J
之前提到的NoSql数据库是为了解决关系型数据库的阻抗失谐,扩展困难而设计的。
图数据库是为了解决关系型数据库的另外一项缺陷设计的——对象间关系复杂。
比如记录如图3.1的这样关系比较复杂的一组记录。特点是节点都很简单,但是节点的结构十分丰富。比如可以查询,找出数据库方面的书,作者必须是我的某个朋友喜欢的。
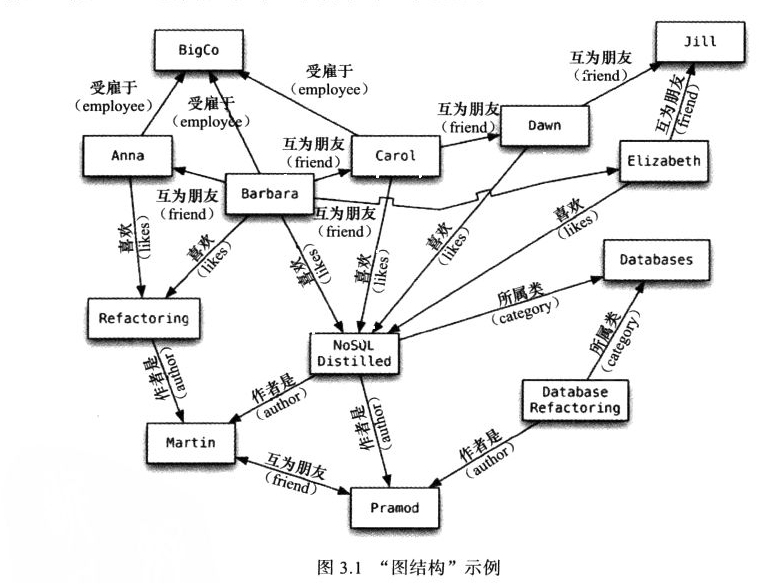
Neo4J可以用无模式的方式将Java对象作为属性,附加到节点与边之中;Infinite
Graph“可以把 Java对象作为其内建类型的子类对象,存储成节点与边。
以节点与边把图结构搭建好之后,就可以用专门为“图”而设计的查询操作来搜
寻图数据库的网络了。这就是图数据库和关系型数据库的重要差别。尽管关系型数据
库也可以通过外键来实现这种关系,但是在各种关系中导览所需的JOIN语句非常耗
时。
因为图数据库会多花一些时间用于插入关系数据,以此来缩短遍历关系时所需的时间。
适用于查询频繁插入较少的场景。
四、业界主流的两种数据库实现模式
集成数据库
多个应用程序共用同一份数据库底表其优势在于提高数据通讯效率,能确保所有应用操作的持久化数据保持一致性。
代价是数据库设计的带来更多的复杂性,更多的并发问题,以及数据库单点问题——性能问题会波及所有应用,故障会“团灭”所有应用。
即便解决了上述所有问题,若应用A对底表M进行DDL操作,同样用底表M的应用B就会受到牵连,这种相互掣肘的场景在团队开发中也难以避免。
本质思想是通过SQL共享数据库
本质矛盾是把维护数据完整性的职责交给数据库,但是多应用会破坏数据完整性。
鉴于此,就有了第二个解决方案——应用程序数据库。
应用程序数据库
简单说就是专门设计一个用于访问数据库的应用,假设叫DBApp,把维护数据库完整性的工作放在应用程序代码中,
其他应用程序统一拿DBApp中内存状态的标准领域模型,在DDD领域驱动设计中也叫做聚合根。
本质思想是通过程序接口共享数据库
选取这种形式,内部外部通讯得以解耦,数据库选型的自由度就很高了。
因为需要的是分布式事务的一致性,事务可以交由DBApp以分布式事务(TCC或者SAGA)的方式去控制。
而非狭义的以关系型数据库的事务控制,所以在选择数据库技术时,我们也可以把目光投向非关系型数据库,甚至于可以用囊括关系型非关系型的多种数据库,组合成最终的内存模型,最终通过应用程序数据库提供数据访问能力(即混合持久化)。
传统关系型数据库中怎么用NoSql的特性
可以采用关系型对象,携带一个extendMap的值作为扩展字段,把这个extendMap当做一个NoSql的kv对象使用,这样就能给原来的对象增加可扩展性。
案例
比如在阿里供应链履约订单,实际操作场景中,就使用了应用程序数据库。
五、补充思考
数据库本质都是分享数据,都要用到网络协议。那么数据库技术用到了哪些网络协议,这些网络协议除了运用在数据库的数据传输,还用在了哪些技术上?
拿最耳熟能详的TCP/IP协议说,所处网络层级关系如下
| TCP协议 | 传输层 |
|---|---|
| IP协议 | 网络层 |
| OSI 七层模型 | TCP/IP 四层模型 | 功能 | 典型协议 |
|---|---|---|---|
| 应用层 (Application Layer) | 应用层 (Application Layer) | 文件传输,电子邮件,文件服务,虚拟终端 | TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet |
| 表示层 (Presentation Layer) | 数据格式化,代码转换,数据加密 | 无 | |
| 会话层 (Session Layer) | 解除或建立与别的接点的联系 | 无 | |
| 传输层 (Transport Layer) | 传输层 (Transport Layer) | 提供端对端的接口 | TCP,UDP |
| 网络层 (Network Layer) | 网络层 (Internet Layer) | 为数据包选择路由 | IP,ICMP,RIP,OSPF,BCP,ICMP |
| 数据链路层 (Data Link Layer) | 链路层 (Link Layer) | 传输有地址的帧以及错误检测功能 | SLIP,CSLIP,PPP,ARP,RARP,MTU |
| 物理层 (Physical Layer) | 物理层 (Physical Layer) | 以二进制数据形式在物理媒体上传输数据 | ISO2110,IEEE8031EEE802接术社区 |
MySQL协议使用TCP/IP进行数据传输,可以在加密的SSL连接上使用。
Dubbo 框架提供了自定义的高性能RPC 通信协议:基于HTTP/2 的Triple 协议和基于TCP 的Dubbo2 协议。
小结
应用层数据访问通常是基于应用层(HTTP)协议的,数据库通常是基于传输层和网络层(TCP/IP的。不同层级的数据通过相应网络协议表示到前端。数据库只是一种手段,目的是把数据从存储介质传输到前端即可。就像事务是保持一致性的一种手段,在水平分库分表场景下,一致性基于编码实现也可以。
六、扩展
在关系型数据库中进行分库分表后,通常会面临跨库、跨表的事务问题。下面介绍一些常见的解决方案:
- 垂直分库分表: 在垂直分库分表中,每个库或表负责不同的业务功能或数据类型。这种情况下,事务可以被限制在单个库或表中,事务的保证和传统的单库事务一样,不需要额外的处理。
- 水平分库分表:
- 分布式事务管理器: 可以使用分布式事务管理器来跨库管理事务,如Atomikos、Bitronix等。这些工具可以协调不同数据库的事务,保证分布式事务的原子性、一致性、隔离性和持久性(ACID)。
- 两阶段提交(2PC): 2PC 是一种常见的分布式事务协议,通过协调器协调参与者提交事务的过程,实现跨数据库的事务一致性。但是,2PC 在实践中可能会存在性能、可靠性和复杂性等问题,因此并不是最佳选择。
- 补偿事务(TCC): TCC 是一种基于补偿的分布式事务解决方案。在 TCC 中,事务被分解为 Try、Confirm 和 Cancel 三个阶段,通过执行预处理和补偿操作来保证事务的最终一致性。
- 最大努力通知(Best Effort Delivery): 最大努力通知是一种简单的分布式事务方案,参与者在事务提交后异步通知协调者,而协调者则处理参与者的通知结果。虽然无法保证严格的一致性,但是可以提供满足应用需求的最终一致性。
- SAGA 事务:原本提出 SAGA 的目的,是为了避免大事务长时间锁定数据库的资源,后来才逐渐发展成将一个分布式环境中的大事务,分解为一系列本地事务的设计模式。SAGA 由两部分操作组成。一部分是把大事务拆分成若干个小事务,将整个分布式事务 T 分解为 n 个子事务,我们命名为 T1,T2,…,Ti,…,Tn。每个子事务都应该、或者能被看作是原子行为。如果分布式事务 T 能够正常提交,那么它对数据的影响(最终一致性)就应该与连续按顺序成功提交子事务 Ti 等价。另一部分是为每一个子事务设计对应的补偿动作。
阅读推荐:分布式事务之TCC与SAGA

