
- 1文心一言降重效果 快码论文_文心一言降重诀窍
- 2java计算机毕业设计(附源码)学生信息管理系统(ssm+mysql+maven+LW文档)
- 3Kafka怎么保证消息发送不丢失_kafka 生产者和消费者怎么保证不丢消息
- 4国密算法SM3
- 5常见开源许可证_弱著佐权类许可证
- 6pyglet python播放视频有声音_播放器播放rtsp混合流正常,python代码播放有杂音
- 7Prim算法:最小生成树的构建_prim算法怎么构建最小生成树
- 8paddleocr - 数据集制作_paddleocr数据集格式
- 9阿里、腾讯、字节、京东、美团、百度......薪资职级大比拼
- 10【xml解析】的学习_xml语言 sph
昇思25天学习打卡营第20天|Vision Transformer图像分类
赞
踩
今天是参加昇思25天学习打卡营的第20天,今天打卡的课程是“Vision Transformer图像分类”,这里做一个简单的分享。
1.简介
今天学习一种新的图像分类的模型–Vision Transformer图像分类模型。
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。
ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
2.模型架构
- 模型特点
ViT模型主要应用于图像分类领域。因此,其模型结构相较于传统的Transformer有以下几个特点:
数据集的原图像被划分为多个patch(图像块)后,将二维patch(不考虑channel)转换为一维向量,再加上类别向量与位置向量作为模型输入。
模型主体的Block结构是基于Transformer的Encoder结构,但是调整了Normalization的位置,其中,最主要的结构依然是Multi-head Attention结构。
模型在Blocks堆叠后接全连接层,接受类别向量的输出作为输入并用于分类。通常情况下,我们将最后的全连接层称为Head,Transformer Encoder部分为backbone。
- VIT模型结构
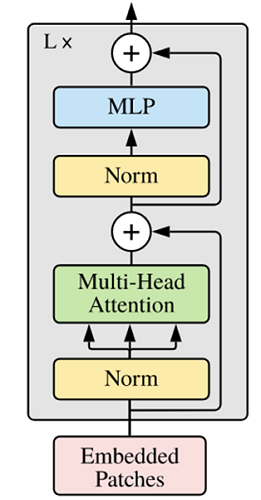
ViT模型中的基础结构与标准Transformer有所不同,主要在于Normalization的位置是放在Self-Attention和Feed Forward之前,其他结构如Residual Connection,Feed Forward,Normalization都如Transformer中所设计。
- ViT模型中的基础结构与标准Transformer有所不同,主要在于Normalization的位置是放在Self-Attention和Feed Forward之前,其他结构如Residual Connection,Feed Forward,Normalization都如Transformer中所设计。
- 从Transformer结构的图片可以发现,多个子encoder的堆叠就完成了模型编码器的构建,在ViT模型中,依然沿用这个思路,通过配置超参数num_layers,就可以确定堆叠层数。
- Residual Connection,Normalization的结构可以保证模型有很强的扩展性(保证信息经过深层处理不会出现退化的现象,这是Residual Connection的作用),Normalization和dropout的应用可以增强模型泛化能力。
从Transformer结构的图片可以发现,多个子encoder的堆叠就完成了模型编码器的构建,在ViT模型中,依然沿用这个思路,通过配置超参数num_layers,就可以确定堆叠层数。
Residual Connection,Normalization的结构可以保证模型有很强的扩展性(保证信息经过深层处理不会出现退化的现象,这是Residual Connection的作用),Normalization和dropout的应用可以增强模型泛化能力。
- ViT模型的输入
传统的Transformer结构主要用于处理自然语言领域的词向量(Word Embedding or Word Vector),词向量与传统图像数据的主要区别在于,词向量通常是一维向量进行堆叠,而图片则是二维矩阵的堆叠,多头注意力机制在处理一维词向量的堆叠时会提取词向量之间的联系也就是上下文语义,这使得Transformer在自然语言处理领域非常好用,而二维图片矩阵如何与一维词向量进行转化就成为了Transformer进军图像处理领域的一个小门槛。
在ViT模型中:
- 通过将输入图像在每个channel上划分为16*16个patch,这一步是通过卷积操作来完成的,当然也可以人工进行划分,但卷积操作也可以达到目的同时还可以进行一次而外的数据处理;例如一幅输入224 x 224的图像,首先经过卷积处理得到16 x 16个patch,那么每一个patch的大小就是14 x 14。
- 再将每一个patch的矩阵拉伸成为一个一维向量,从而获得了近似词向量堆叠的效果。上一步得到的14 x 14的patch就转换为长度为196的向量。
输入图像在划分为patch之后,会经过pos_embedding 和 class_embedding两个过程。
- class_embedding主要借鉴了BERT模型的用于文本分类时的思想,在每一个word vector之前增加一个类别值,通常是加在向量的第一位,上一步得到的196维的向量加上class_embedding后变为197维。
- 增加的class_embedding是一个可以学习的参数,经过网络的不断训练,最终以输出向量的第一个维度的输出来决定最后的输出类别;由于输入是16 x 16个patch,所以输出进行分类时是取 16 x 16个class_embedding进行分类。
- pos_embedding也是一组可以学习的参数,会被加入到经过处理的patch矩阵中。
- 由于pos_embedding也是可以学习的参数,所以它的加入类似于全链接网络和卷积的bias。这一步就是创造一个长度维197的可训练向量加入到经过class_embedding的向量中。
实际上,pos_embedding总共有4种方案。但是经过作者的论证,只有加上pos_embedding和不加pos_embedding有明显影响,至于pos_embedding是一维还是二维对分类结果影响不大,所以,在我们的代码中,也是采用了一维的pos_embedding,由于class_embedding是加在pos_embedding之前,所以pos_embedding的维度会比patch拉伸后的维度加1。
总的而言,ViT模型还是利用了Transformer模型在处理上下文语义时的优势,将图像转换为一种“变种词向量”然后进行处理,而这样转换的意义在于,多个patch之间本身具有空间联系,这类似于一种“空间语义”,从而获得了比较好的处理效果。
VIT完整模型代码示例:
from mindspore.common.initializer import Normal from mindspore.common.initializer import initializer from mindspore import Parameter def init(init_type, shape, dtype, name, requires_grad): """Init.""" initial = initializer(init_type, shape, dtype).init_data() return Parameter(initial, name=name, requires_grad=requires_grad) class ViT(nn.Cell): def __init__(self, image_size: int = 224, input_channels: int = 3, patch_size: int = 16, embed_dim: int = 768, num_layers: int = 12, num_heads: int = 12, mlp_dim: int = 3072, keep_prob: float = 1.0, attention_keep_prob: float = 1.0, drop_path_keep_prob: float = 1.0, activation: nn.Cell = nn.GELU, norm: Optional[nn.Cell] = nn.LayerNorm, pool: str = 'cls') -> None: super(ViT, self).__init__() self.patch_embedding = PatchEmbedding(image_size=image_size, patch_size=patch_size, embed_dim=embed_dim, input_channels=input_channels) num_patches = self.patch_embedding.num_patches self.cls_token = init(init_type=Normal(sigma=1.0), shape=(1, 1, embed_dim), dtype=ms.float32, name='cls', requires_grad=True) self.pos_embedding = init(init_type=Normal(sigma=1.0), shape=(1, num_patches + 1, embed_dim), dtype=ms.float32, name='pos_embedding', requires_grad=True) self.pool = pool self.pos_dropout = nn.Dropout(p=1.0-keep_prob) self.norm = norm((embed_dim,)) self.transformer = TransformerEncoder(dim=embed_dim, num_layers=num_layers, num_heads=num_heads, mlp_dim=mlp_dim, keep_prob=keep_prob, attention_keep_prob=attention_keep_prob, drop_path_keep_prob=drop_path_keep_prob, activation=activation, norm=norm) self.dropout = nn.Dropout(p=1.0-keep_prob) self.dense = nn.Dense(embed_dim, num_classes) def construct(self, x): """ViT construct.""" x = self.patch_embedding(x) cls_tokens = ops.tile(self.cls_token.astype(x.dtype), (x.shape[0], 1, 1)) x = ops.concat((cls_tokens, x), axis=1) x += self.pos_embedding x = self.pos_dropout(x) x = self.transformer(x) x = self.norm(x) x = x[:, 0] if self.training: x = self.dropout(x) x = self.dense(x) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
3.小结
VIT模型基于Transformer架构来实现图像分类的,可以视为Transformer架构在计算机视觉上的扩展,这也是说明transformer架构在多模态任务的适应性。通过今天学习,主要收获有以下几个方面:一是了解和学习了tansformer架构中的注意力机制等原理,二是学习了基于vit如何如何Transformer架构进行改造以适应图像的分类计算,三是对于Mindspore下实现vit模块的代码进行深度的学习和实战。
以上是第20天的学习内容,附上今日打卡记录:


