
- 1【Tableau 设计提示9.0】工具提示中的可视化的 10 个技巧(上)_tableau
- 2python参数输入(input&argv)_py input()和argc
- 3Codeium在IDEA里的3个坑_idea里codeium登入不了
- 4自己搭建的GPT4中转API国内免费使用_gpt实现中转
- 5蓝桥杯-python-常用库归纳
- 6杭州超清智能|银行押宝“元宇宙”,金融元宇宙要来了?
- 7【Python+OpenCV】识别颜色方块并提取轮廓_opencv识别蓝色方块
- 8AI for Science:OpenVINO+英特尔独立显卡解薛定谔方程_pinn求解薛定谔方程
- 9美创科技获浙江省网络空间安全协会多项荣誉认可
- 10对抗性攻击和防御竞争(Adversarial Attacks and Defences Competition)的通俗解读
多模态融合 fusion 的各种操作_multi-method feature fusion
赞
踩
文章转载:
作者丨小奚每天都要学习@知乎
来源丨https://zhuanlan.zhihu.com/p/152234745
Zhang, C., Yang, Z., He, X., \& Deng, L. (2020). Multimodal intelligence: Representation learning, information fusion, and applications.IEEE Journal of Selected Topics in Signal Processing.
一、简介
从2010年开始,深度学习方法为语音识别,图像识别和自然语言处理领域带来了巨大的变革。这些领域中的任务都只涉及单模态的输入,但是最近更多的应用都需要涉及到多种模态的智慧。多模态深度学习主要包含三个方面:多模态学习表征,多模态信号融合以及多模态应用,而本文主要关注计算机视觉和自然语言处理的相关融合方法,包括网络结构设计和模态融合方法(对于特定任务而言)。
二、多模态融合办法
多模态融合是多模态研究中非常关键的研究点,它将抽取自不同模态的信息整合成一个稳定的多模态表征。多模态融合和表征有着明显的联系,如果一个过程是专注于使用某种架构来整合不同单模态的表征,那么就被归类于fusion类。而fusion方法又可以根据他们出现的不同位置而分为late和early fusion。因为早期和晚期融合会抑制模内或者模间的交互作用,所以现在的研究主要集中于intermediate的融合方法,让这些fusion操作可以放置于深度学习模型的多个层之中。而融合文本和图像的方法主要有三种:基于简单操作的,基于注意力的,基于张量的方法。
a) 简单操作融合办法
来自不同的模态的特征向量可以通过简单地操作来实现整合,比如拼接和加权求和。这样的简单操作使得参数之间的联系几乎没有,但是后续的网络层会自动对这种操作进行自适应。
l Concatenation拼接操作可以用来把低层的输入特征[1][2][3]或者高层的特征(通过预训练模型提取出来的特征)[3][4][5]之间相互结合起来。
l Weighted sum 对于权重为标量的加权求和方法,这种迭代的办法要求预训练模型产生的向量要有确定的维度,并且要按一定顺序排列并适合element-wise 加法[6]。为了满足这种要求可以使用全连接层来控制维度和对每一维度进行重新排序。
最近的一项研究[7]采用渐进探索的神经结构搜索[8][9][10]来为fusion找到合适的设置。根据要融合的层以及是使用连接还是加权和作为融合操作来配置每个融合功能。
b) 基于注意力机制的融合办法
很多的注意力机制已经被应用于融合操作了。注意力机制通常指的是一组“注意”模型在每个时间步动态生成的一组标量权重向量的加权和[11][12]。这组注意力的多个输出头可以动态产生求和时候要用到的权重,因此最终在拼接时候可以保存额外的权重信息。在将注意机制应用于图像时,对不同区域的图像特征向量进行不同的加权,得到一个最终整体的图像向量。
l 图注意力机制
扩展了用于文本问题处理的LSTM模型,加入了基于先前LSTM隐藏状态的图像注意模型,输入为当前嵌入的单词和参与的图像特征的拼接[13]。最终LSTM的隐藏状态就被用于一种多模态的融合的表征,从而被应用于VQA问题之中。 这种基于RNN的encoder-decoder模型被用来给图像特征分配权重从而做image caption任务[14]。此外,对于VQA视觉问答任务,attention模型还能通过文本query来找到图像对应得位置[15]。同样,堆叠注意力网络(SANs)也被提出使用多层注意力模型对图像进行多次查询,逐步推断出答案,模拟了一个多步骤的推理过程[16]。通过多次迭代实现图像区域的Attention。首先根据图像特征和文本特征生成一个特征注意分布,根据这个分布得到图像每个区域权重和Vi,根据u=Vi+Vq得到一个refine query向量。将这个过程
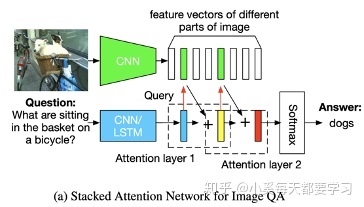
多次迭代最终注意到问题相关区域。当然和san很像的还有[17]。
一种动态记忆网络也被升级了并用来分别编码问题和图像。这种网络则使用了基于attention的GRUs来更新情景记忆和检索所需信息[18]。
自底向上和自顶向下的注意方法(Up-Down),顾名思义,通过结合两种视觉注意机制来模拟人类的视觉系统[19].自下而上的注意力机制是通过使用目标检测算法(如faster rcnn)来首先挑选出一些列的图像候选区域,而自上而下的注意力机制则是要把视觉信息和语义特征拼接从而生成一个带有注意力的图像特征向量,最终服务于图像描述和VQA任务。同时,带有注意力的图像特征向量还可以和文本向量进行点乘。来自不同模型(resnet和faster rcnn)的互补图像特征也可以被用于多种图像注意力机制[20]。更进一步,图像注意力机制的逆反应用,可以从输入的图像+文本来生成文本特征,还可以用于文本生成图像的任务[21]。

l 图和文本的对称注意力机制
与上述图像注意机制不同,共注意机制使用对称注意力结构生成attended图像特征向量和attended语言向量[22]。平行共注意力机制采用联合表示的方法模拟推导出图像和语言的注意分布。交替共同注意力机制具有级联结构,首先使用语言特征生成含有注意力的图像向量,然后使用含有注意力的图像向量生成出含注意力的语言向量。

和平行共注意力机制类似,双注意力网络(DAN)同时估计图像和文本的注意力分布从而获得最后的注意力特征向量[23]。这种注意模型以特征和与相关模式相关的记忆向量为条件。与共同注意相比,这是一个关键的区别,因为记忆向量可以使用重复的DAN结构在每个推理步骤中迭代更新。
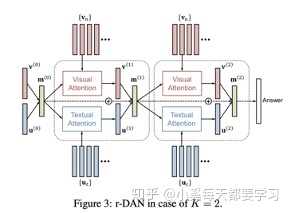
堆叠的latent attention (SLA)改进了SAN,它把图像的原始特征和网络浅层的向量连接,以保存中间推理阶段的潜在信息[24]。当然还包括一种类似双流的并行共注意结构,用于同时注意图像和语言特征,这便于使用多个SLA层进行迭代推理。双递归注意单元利用文本和图像的LSTM模型实现了一个并行的共注意结构,在使用CNN层堆栈卷积图像特征得到的表示中为每个输入位置分配注意权值[25]。为了模拟两种数据模式之间的高阶交互作用,可以将两种数据模式之间的高阶相关性作为两种特征向量的内积来计算,从而得到两种模式的交互的注意力特征向量[26]。
l 双模的transformer的注意力机制
这部分主要是基于BERT的变体,采用双流输入embedding方法,然后再后续的共注意力层中进行交互。
l 其他类似注意力的机制
门控多模态单元是一种基于门控的方法,可以看作是为图像和文本分配注意权重[27]。该方法是基于门控机制动态生成的维度特定标量权重,计算视觉特征向量和文本特征向量的加权和。类似的,向量按位乘法可以用于融合视觉和文本表达。然后将这些融合的表示方法用于构建基于深度残差学习的多模态残差网络[27]。还有就是动态参数预测网络,它采用动态权值矩阵来变换视觉特征向量,其参数由文本特征向量哈希动态生成[28]。
c) 基于双线性池化的融合办法
双线性池化主要用于融合视觉特征向量和文本特征向量来获得一个联合表征空间,方法是计算他们俩的外积,这种办法可以利用这俩向量元素的所有的交互作用,也被称作second-order pooling[30]。和简单地向量组合操作(假设每个模态的特征向量有n个元素)不一样的是,简单操作(如加权求和,按位操作,拼接)都会生成一个n或者2n维度的表征向量,而双线性池化则会产生一个n平方维度的表征。通过将外积生成的矩阵线性化成一个向量表示,这意味着这种方法更有表现力。双线性表示方法常常通过一个二维权重矩阵来转化为相应的输出向量,也等价于使用一个三维的tensor来融合两个输入向量。在计算外积时,每个特征向量可以加一个1,以在双线性表示中保持单模态输入特征[32]。然而,基于它的高维数(通常是几十万到几百万维的数量级),双线性池通常需要对权值张量进行分解,才可以适当和有效地训练相关的模型。
l 双线性池化的因式分解
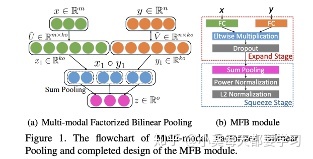
由于双线性出来的表征与多项式核密切相关,因此可以利用各种低维近似来获得紧的双线性表示[32]。Count sketch和卷积能够用来近似多项式核[33][34],从而催生出了多模态紧凑双线性池化multimodal compact bilinear pooling MCB[35]。或者,通过对权值张量施加低秩控制,多模态低秩双线性池(MLB)将双线性池的三维权值张量分解为三个二维权值矩阵[36]。具体的来说,视觉和文字特征向量通过两个输入因子矩阵线性投影到低维矩阵上。然后使用按元素的乘法将这些因子融合,然后使用第三个矩阵对输出因子进行线性投影。多模态因子分解双线性池化Multimodal factorized bilinear pooling (MFB)对MLB进行了修改,通过对每个非重叠的一维窗口内的值求和,将元素间的乘法结果集合在一起[37]。多个MFB模型可以级联来建模输入特性之间的高阶交互,这被称为多模态因数化高阶池(MFH)[38]。
MUTAN是一种基于多模态张量的Tucker decomposition方法,使用Tucker分解[39]将原始的三维权量张量算子分解为低维核心张量和MLB使用的三个二维权量矩阵[40]。核心张量对不同形式的相互作用进行建模。MCB可以看作是一个具有固定对角输入因子矩阵和稀疏固定核张量的MUTAN, MLB可以看作是一个核张量为单位张量的MUTAN。
而最新的AAAI2019提出了BLOCK,是一个基于块的超对角阵的融合框架[41],是为了块项的消解和合成[42]。BLOCK将MUTAN泛化为多个MUTAN模型的总和,为模式之间的交互提供更丰富的建模。此外,双线性池化可以推广到两种以上的modality,例如使用外积来建模视频、音频和语言表示之间的交互[43]。
l 双线性池化和注意力机制
双线性池化和注意力机制也可以进行结合。MCB/MLB融合的双模态表示可以作为注意力模型的输入特征,得到含有注意力的图像特征向量,然后再使用MCB/MLB与文本特征向量融合,形成最终的联合表示[44][45]。MFB/MFH可用于交替的共同注意学习联合表示[46][47]。
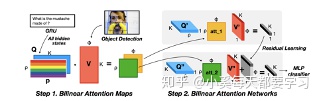
双线性注意网络(BAN)利用MLB融合图像和文本,生成表示注意力分布的双线性注意图,并将其作为权重张量进行双线性pooling,再次融合图像和文本特征[48]。
三、总结
近年来最主要的多模态融合办法就是基于attention的和基于双线性池化的方法。其中双线性池化的数学有效性方面还可以有很大的提升空间。
四、引用
[1] B. Nojavanasghari, D. Gopinath, J. Koushik, B. T., and L.-P. Morency, “Deep multimodal fusion for persuasiveness prediction,” in Proc. ICMI, 2016
[2] H. Wang, A. Meghawat, L.-P. Morency, and E. Xing, “Select-additive learning: Improving generalization in multimodal sentiment analysis,” in Proc. ICME, 2017.
[3] A. Anastasopoulos, S. Kumar, and H. Liao, “Neural language modeling with visual features,” in arXiv:1903.02930, 2019.
[4] V. Vielzeuf, A. Lechervy, S. Pateux, and F. Jurie, “CentralNet: A multilayer approach for multimodal fusion,” in Proc. ECCV, 2018.
[5] B. Zhou, Y. Tian, S. Sukhbaatar, A. Szlam, and R. Fergus, “Simple baseline for visual question answering,” in arXiv:1512.02167, 2015.
[6] J.-M. Pe ́rez-Ru ́a, V. Vielzeuf, S. Pateux, M. Baccouche, and F. Jurie, “MFAS: Multimodal fusion architecture search,” in Proc. CVPR, 2019.
[7] B. Zoph and Q. Le, “Neural architecture search with reinforcement learning,” in Proc. ICLR, 2017.
[8] C. Liu, B. Zoph, M. Neumann, J. Shlens, W. Hua, L.-J. Li, F.-F. Li, A. Yuille, J. Huang, and K. Murphy, “Progressive neural architecture search,” in Proc. ECCV, 2018.
[9] J.-M. Pe ́rez-Ru ́a, M. Baccouche, and S. Pateux, “Efficient progressive neural architecture search,” in Proc. BMVC, 2019.
[10] X. Yang, P. Molchanov, and J. Kautz, “Multilayer and multimodal fusion of deep neural networks for video classification,” in Proc. ACM MM, 2016.
[11] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in Proc. ICLR, 2015.
[12] A. Graves, G. Wayne, and I. Danihelka, “Neural turing machines,” in arXiv:1410.5401, 2014.
[13] Y. Zhu, O. Groth, M. Bernstein, and F.-F. Li, “Visual7W: Grounded question answering in images,” in Proc. CVPR, 2016.
[14] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhutdinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in Proc. ICML, 2015.
[15] K. Shih, S. Singh, and D. Hoiem, “Where to look: Focus regions for visual question answering,” in Proc. CVPR, 2016.
[16] Z. Yang, X. He, J. Gao, L. Deng, and A. Smola, “Stacked attention networks for image question answering,” in Proc. CVPR, 2016.
[17] H. Xu and K. Saenko, “Ask, attend and answer: Exploring question-guided spatial attention for visual question answering,” in Proc. ECCV, 2016.
[18] C. Xiong, S. Merity, and R. Socher, “Dynamic memory networks for visual and textual question answering,” in Proc. ICML, 2016.
[19] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang, “Bottom-up and top-down attention for image captioning and visual question answering,” in Proc. CVPR, 2018.
[20] P. Lu, H. Li, W. Zhang, J. Wang, and X. Wang, “Co-attending free- form regions and detections with multi-modal multiplicative feature embedding for visual question answering,” in Proc. AAAI, 2018.
[21] W. Li, P. Zhang, L. Zhang, Q. Huang, X. He, S. Lyu, and J. Gao, “Object-driven text-to-image synthesis via adversarial training,” in Proc. CVPR, 2019.
[22] J. Lu, J. Yang, D. Batra, and D. Parikh, “Hierarchical question-image co-attention for visual question answering,” in Proc. NIPS, 2016.
[23] H. Nam, J.-W. Ha, and J. Kim, “Dual attention networks for multimodal reasoning and matching,” in Proc. CVPR, 2017.
[24] H. Fan and J. Zhou, “Stacked latent attention for multimodal reasoning,” in Proc. CVPR, 2018.
[25] A. Osman and W. Samek, “DRAU: Dual recurrent attention units for visual question answering,” Computer Vision and Image Understanding, vol. 185, pp. 24–30, 2019.
[26] I. Schwartz, A. Schwing, and T. Hazan, “High-order attention models for visual question answering,” in Proc. NIPS, 2017.
[27] J. Arevalo, T. Solorio, M. Montes-y Go ́mez, and F. Gonza ́lez, “Gated multimodal units for information fusion,” in Proc. ICLR, 2017.
[28] J.-H. Kim, S.-W. Lee, D.-H. Kwak, M.-O. Heo, J. Kim, J.-W. Ha, and B.-T. Zhang, “Multimodal residual learning for visual QA,” in Proc. NIPS, 2016.
[29] H. Noh, P. Seo, and B. Han, “Image question answering using convolutional neural network with dynamic parameter prediction,” in Proc. CVPR, 2016.
[30] J. Tenenbaum and W. Freeman, “Separating style and content with bilinear models,” Neural Computing, vol. 12, pp. 1247–1283, 2000.
[31] A. Zadeh, M. Chen, S. Poria, E. Cambria, and L.-P. Morency, “Tensor fusion network for multimodal sentiment analysis,” in Proc. EMNLP, 2017.
[32] Y. Gao, O. Beijbom, N. Zhang, and T. Darrell, “Compact bilinear pooling,” in Proc. CVPR, 2016.
[33] M. Charikar, K. Chen, and M. Farach-Colton, “Finding frequent items in data streams,” in Proc. ICALP, 2012.
[34] N. Pham and R. Pagh, “Fast and scalable polynomial kernels via explicit feature maps,” in Proc. SIGKDD, 2013.
[35] A. Fukui, D. Park, D. Yang, A. Rohrbach, T. Darrell, and M. Rohrbach, “Multimodal compact bilinear pooling for visual question answering and visual grounding,” in Proc. EMNLP, 2016.
[36] J.-H. Kim, K.-W. On, W. Lim, J. Kim, J.-W. Ha, and B.-T. Zhang, “Hadamard product for low-rank bilinear pooling,” in Proc. ICLR, 2017.
[37] Z. Yu, J. Yu, J. Fan, and D. Tao, “Multi-modal factorized bilinear pooling with co-attention learning for visual question answering,” in Proc. ICCV, 2017.
[38] Z. Yu, J. Yu, C. Xiang, J. Fan, and D. Tao, “Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, pp. 5947–5959, 2018.
[39] L. Tucker, “Some mathematical notes on three-mode factor analy,” Psychometrika, vol. 31, pp. 279–311, 1966.
[40] H. Ben-younes, R. Cadene, M. Cord, and N. Thome, “MUTAN: Multimodal tucker fusion for visual question answering,” in Proc. ICCV, 2017.
[41] L. Lathauwer, “Decompositions of a higher-order tensor in block termspart II: Definitions and uniqueness,” SIAM Journal on Matrix Analysis and Applications, vol. 30, pp. 1033–1066, 2008.
[42] H. Ben-younes, R. Cadene, N. Thome, and M. Cord, “BLOCK: Bilinear superdiagonal fusion for visual question answering and visual relationship detection,” in Proc. AAAI, 2019.
[43] Z. Liu, Y. Shen, V. Lakshminarasimhan, P. Liang, A. Zadeh, and L.-P. Morency, “Efficient low-rank multimodal fusion with modality-specific factors,” in Proc. ACL, 2018.
[44] A. Fukui, D. Park, D. Yang, A. Rohrbach, T. Darrell, and M. Rohrbach, “Multimodal compact bilinear pooling for visual question answering and visual grounding,” in Proc. EMNLP, 2016.
[45] J.-H. Kim, K.-W. On, W. Lim, J. Kim, J.-W. Ha, and B.-T. Zhang, “Hadamard product for low-rank bilinear pooling,” in Proc. ICLR, 2017.
[46] Z. Yu, J. Yu, J. Fan, and D. Tao, “Multi-modal factorized bilinear pooling with co-attention learning for visual question answering,” in Proc. ICCV, 2017.
[47] L. Tucker, “Some mathematical notes on three-mode factor analy,” Psychometrika, vol. 31, pp. 279–311, 1966.
[48] J.-H. Kim, J. Jun, and B.-T. Zhang, “Bilinear attention networks,” in Proc. NeurIPS, 2018.

