
热门标签
热门文章
- 1vrrp小实验_s31与s32实现vrrp负载均衡;s31为vlan10和vlan30的根桥和主网关,s32为vla
- 2Linux 系统中 NumPy (Python 2) 编程环境
- 3rikibot机器人调参
- 4神器来袭,手把手教你使用 Milvus_cli
- 5CentOS 6&7 升级GCC版本(GCC4.8,GCC4.9,GCC5.3,GCC6.2)_centos7升级gcc4.8.5到gcc4.9.0
- 6基于matlab的相干信号的doa 估计,基于空间平滑MUSIC算法的相干信号DOA估计(1)
- 7Vue学习笔记(二)_const actiondialogref = ref
- 8在线少儿编程系统源码带本地搭建教程_少儿编程源码
- 9脑启发遥感解译:一个全面的调查_john hopfield在1983年提出一种用于联想记忆的神经网络(hopfield网络),在旅行
- 10Stable Diffusion WebUI安装合成面部说话插件SadTalker_webui安装sadtalker
当前位置: article > 正文
Transformer的前世今生 day01(预训练、统计语言模型)
作者:我家自动化 | 2024-03-30 06:06:16
赞
踩
Transformer的前世今生 day01(预训练、统计语言模型)
预训练
- 在相似任务中,由于神经网络模型的浅层是通用的,如下图:

- 所以当我们的数据集不够大,不能产生性能良好的模型时,可以尝试让模型B在用模型A的浅层基础上,深层的部分自己生成参数,减小数据集的压力
- 使用模型A的浅层来实现任务B,由两种方式:
- 冻结(frozen):浅层参数不变
- 微调(Fine-Tuning):浅层参数会跟着任务B的训练而改变
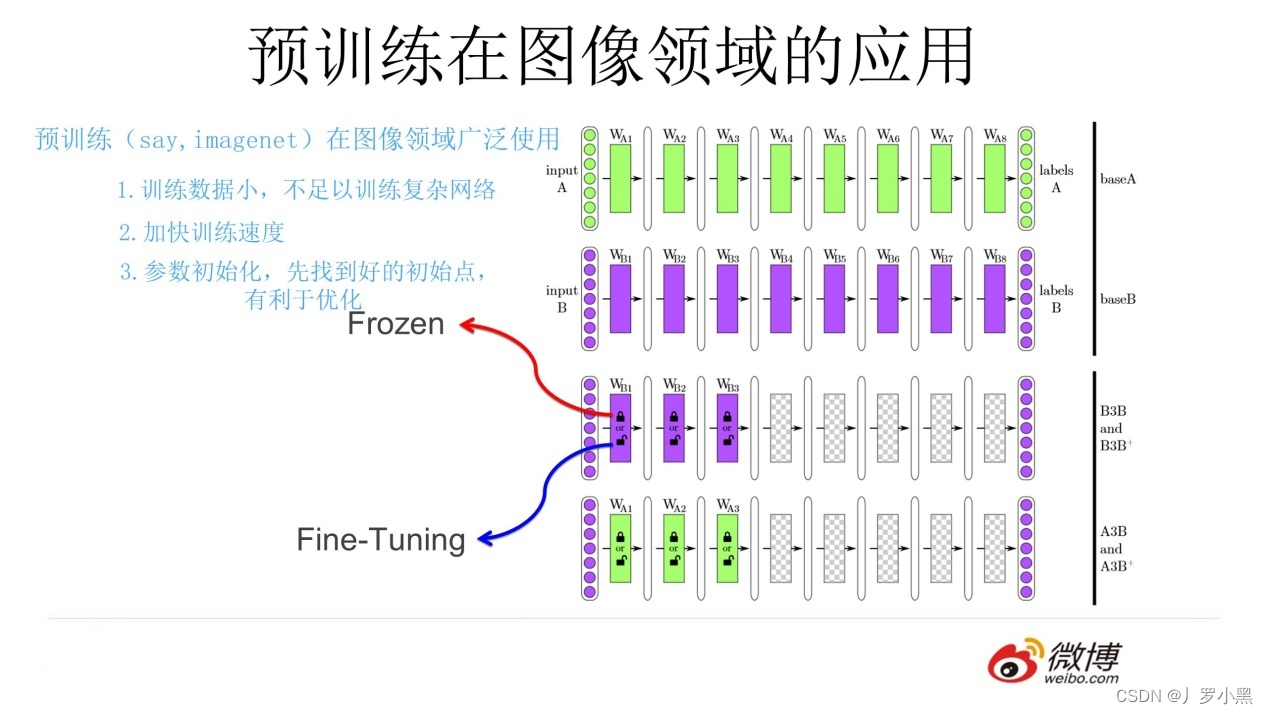
- 总结:一个任务A,一个任务B,两者极其相似,任务A已经通过大数据集训练出一个模型A,使用模型A的浅层参数去训练任务B,得到模型B。
- 使用的特性为:CNN浅层参数通用
- 任务B也可以是大数据,我们仍可以使用模型A的浅层参数,这样在训练模型B的时候,能节省训练时间,节省成本
统计语言模型
- 语言模型:通常是通过模型来完成两个任务
- 判断这两句话,哪一个的概率大:P(“判断这个词的词性”),P("判断这个词的磁性“)
- 选择在这句话的后面填什么词比较好:“判断这个词的__”
- 统计语言模型:用统计的方法解决以上两个问题
- 统计的方法:条件概率的链式法则
- 解决第一个问题:
- 首先对一句话进行分词操作,如:“判断”,“这个”,“词”,“的”,“词性”
- 那求这句话出现的概率就变成了,求这些词按顺序出现的概率,即W1出现的概率 * (W1出现时,W2出现的概率) *…
- 公式如下:
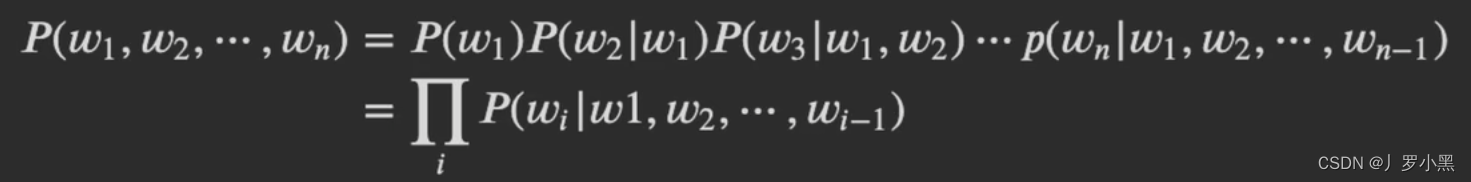
- 解决第二个问题:
- 首先,还是对这句话进行分词操作
- 那求划线处填什么,就变成了求词库中的所有词,哪一个放在这个句子中的概率最大,即求P(W_next | “判断”,“这个”,“词”,“的”)的最大值,即 (Wnext,判断,这个,词,的)出现的个数除以(判断,这个,词,的)出现的个数,公式如下:
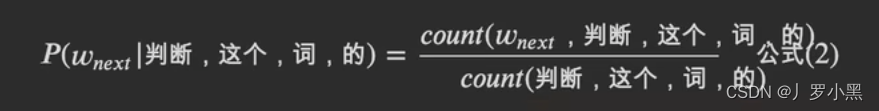
- 词库:就像一个新华字典,把所有词都装进了词库(集合V)中,例如:

- n元统计语言模型
- 统计语言模型的缺陷:如果n特别大,即(W1,W2,W3…Wn)有很多,那么我们算条件概率的计算量很大
- n元统计语言模型:如果可以把n个词在不影响结果的情况下,改为取更少量的词,这样可以减小计算量,如下:

- 实际计算步骤:
- 假设词库如下:
"判断单词的词性”
"磁性很强的磁铁”
”北京的词性是名词"
- 1
- 2
- 3
- 那P(词性 | 的)的结果如下:
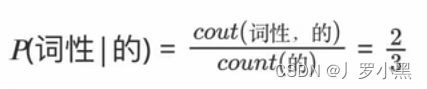
- 平滑策略
- 如果在词库V中求,不存在的词出现的概率,即选词填空问题中,无法从词典中选择一个词填入,那容易出现 0 0 \frac{0}{0} 00的情况,如P(策略 | 平滑)
- 于是为了避免这种情况,会在分子和分母中都加入一个非0正数,如下:
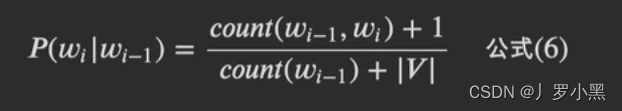
- 总结:
- 语言模型统计两个问题:计算一句话的概率,计算下一个词可能是什么
- 统计语言模型:统计的方法去解决语言模型的问题(条件概率)
- n元统计语言模型:只取n个词
- 平滑策略:避免出现 0 0 \frac{0}{0} 00的情况
参考文献
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/339381
推荐阅读
相关标签

