
- 1文件后缀大全_bpccnv
- 2数据结构初阶 —— 常见排序_数据结构排序
- 3极市平台|100+深度学习各方向数据集资源大盘点_csiq数据集 百度网盘
- 4pynput实现自动化_python pynput库
- 5【Unity地编】地形系统搭建入门详解_unity地编教程
- 6STM32学习记录——烟雾传感器的使用_stm32烟雾传感器
- 7重测序专题(二)| 不断完善的参考基因组_基因组重测序得到的是片段吗
- 8决策树模型学习笔记(案例分析、推算过程、python代码)_决策树简单案例
- 9InterSystems IRIS使用python pyodbc连接 linux环境,odbc驱动安装,DSN配置,数据源配置,linux中文不展示问题
- 10【微信支付】【java】Springboot对接开发微信支付_wechatpay-java
学习遥感大模型(1)
赞
踩
借着课程作业的机会学习了一些遥感大模型相关的工作,现总结一下
根据非盈利组织忧思科学家联盟(The Union of Concerned Scientists),截止2023年1月,全球对地观测卫星在轨数目已超过1000颗。大量的对地观测卫星很大程度解决遥感数据匮乏的困境,随之而生的问题是海量遥感大数据需要更加智能的自动分析算法。近年来,人工智能技术,特别是深度学习,极大地赋能遥感智能解译,广泛应用于建筑物提取、道路提取、土地利用制图等任务。此类数据驱动的方法在精度和速度方面证明了优越性,但往往被诟病弱泛化性和需要人工标注大量样本训练。随着人工智能领域发生巨大变革,大数据催生大模型,ChatGPT、SAM的涌现为遥感智能解译领域带来新的启发,能否基于海量遥感数据无监督地训练一个参数量巨大的强泛化性模型作为底座,通过极低成本的适配来服务于各个下游任务?
本文将总结领域内部分现有的工作,分别介绍生成式自监督学习、对比式自监督学习这两种遥感大模型的构建方式。
为什么要自监督学习?
大模型技术很大程度受益于标度律(Scaling Law),即模型架构不变下,一定范围内增加训练数据规模,模型表现和数据规模成幂律关系。因此如果想要训练出强力的遥感大模型,其预训练方法大概率是无监督的,因为如果采取监督学习的范式,需要更加海量标注遥感数据集,这是非常困难的。
事实上,也正如计算机视觉和自然语言处理领域里所发生的一样,许多遥感大模型采用无监督学习中的一派方法——自监督学习,即它利用数据本身的内在结构或特征进行训练,而无需人工标记的监督信号。与传统的监督学习不同,自监督学习从无标签的数据中自动学习特征表征,然后利用这些表征来解决其他任务。
基于生成式自监督学习的遥感大模型
1)掩码图像重建
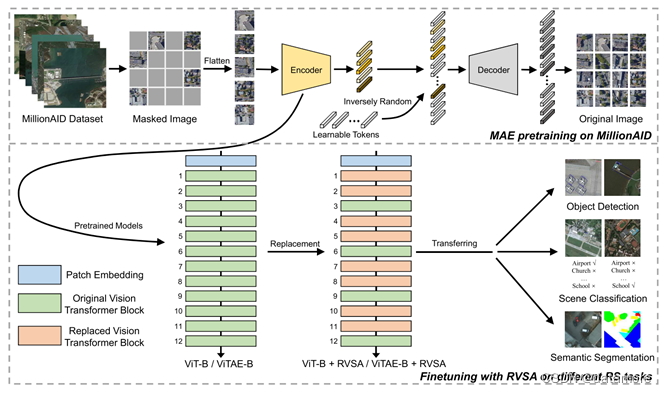
受计算机视觉领域中的掩码图像建模MIM(Masked Image Modeling)启发,如图1所示,[1]对输入图像进行掩码操作。掩码操作是将图像的一部分区域遮挡或隐藏起来,使得模型只能观察到部分图像信息。在进行掩码设置后,模型需要根据观察到的部分图像信息来预测掩码区域的特征。在预测掩码区域的特征后,模型使用损失函数来衡量预测结果与真实值之间的差异,利用误差反向传播更新模型,这样可以学习到图像的有用特征表示。这些特征表示可以在下游任务中进行迁移学习,例如图像分类、目标检测或语义分割等任务。
此外,[1]在ViT(Vision Transformer)基础上引入了一个可学习的旋转机制,用于学习具有不同方向角度的可变尺寸窗口,并在这些窗口内计算注意力。这一设计适用于处理遥感影像中的各种各样朝向的物体,使得从生成的窗口中提取丰富的上下文信息,并学习更好的特征表示。
基于提出的设计,[1]在数据集MillionAID上训练参数上亿的遥感大模型,并通过实验显现了对下游任务的迁移能力,分为场景分类、语义分割、目标检测。其出色的迁移能力体现在微调时相比其他模型使用更少的数据取得更好的表现和同等条件的微调完成后更优秀的模型表现。
2)不完全掩码图像重建
相比自然图像,遥感影像由于特殊的成像机制,背景更加复杂且存在许多小目标。如果直接采用计算机视觉领域的掩码图像建模方法,很可能会丢失小目标的信息,导致重建图像过程中缺乏关键的信息,增大了难度。为此,[2]提出了一种更加适用于遥感大模型训练的掩码策略,如图2左侧所示,他们不完全遮盖图像,而是随机保留一些像素在被遮盖的图像块中。[2]通过这种遮盖策略,从而有效地保留一些小目标的像素信息。
![图2:RingMo[2]提出一种不完全遮盖策略](https://img-blog.csdnimg.cn/9e890190a4d0460581908c7673c653fb.png)
3)时序影像&多光谱影像的掩码图像重建
随着传感器技术升级和卫星数量增多,多光谱影像或是同一地点的不同时间影像也有了充足的积累。针对这一条件,[3]在MAE[4]基础上进行改进,提出了SatMAE训练方法,如图3。
在日常视频数据中,帧与帧之间通常是等间隔的。然而,在遥感领域,卫星图像时间序列是在不规则的时间点上拍摄给定位置的多个快照或版本组合形成的。这些卫星图像序列的长度和采样频率在不同年份以及不同地区差异巨大。为充分利用时序信息,[3]对时间序列中的提出时序位置编码,同时对每一张卫星图像进行独立遮盖使得模型学习到时间维度上的关联,最后时序位置编码、空间位置编码、图像块三者一同送入自编码器训练。
自然图像通常只有RGB三个波段。然而,卫星数据通常可以具有多个光谱波段。例如,Sentinel-2卫星图像具有13个波段,分别具有10米、20米和60米的空间分辨率,并且每个波段具有不同的波长。如果简单堆叠光谱送入网络,单个特征提取器无法充分捕捉具有不同波长和空间分辨率的多个波段中存在的细粒度信息。因此,SatMAE采用了分组光谱编码的策略,基于先验知识,划分多个组(例如根据波长划分3组:RGB+NIR,SWIR,红边),针对不同分组采用不同的特征提取器。此外,他们还引入了一个光谱分组位置编码,最后光谱分组位置编码、空间位置编码、图像块三者一同送入自编码器训练。

基于对比式自监督学习的遥感大模型
简单来说,对比式自监督学习是基于对比学习技术,通过判断一对图像是相似还是不同这一代理任务优化模型表征能力。在对比学习中,相似的图像对被称为正样本对,不同的图像对被称为负样本对。通常地,正样本对是通过对同一图像应用不同的人工增强构成的,而负样本对是两张不同的图像构成的。在获取正负样本对之后,使用精心设计的损失函数来训练模型,最小化正样本对之间的距离,并最大化负样本对之间的距离。
1)针对季节变化构建正负样本对
基于对比式自监督学习的遥感大模型需要基于遥感领域特色,构建正负样本对。针对卫星重访这一特性,SeCo[5]认为时序维度提供了一种自然变化的额外来源,与图像的人工增强相互补充。例如,任何形式的人工增强都无法展示雪山顶在雪融化后的样子,或者作物在不同季节的不同阶段如何变化。

如图4所示,SeCo将同一地点不同时间的卫星图像q,k2,以及对q进行常见的增强处理(如色彩抖动,高斯模糊等)得到的k2,又不同时间又增强处理的k1,使用一个共享权重的特征提取器f抽取特征,随后将其投影到不同的嵌入子空间中,这些子空间内对时间具有变化或不变性。在不同优化不同嵌入子空间时,特征提取器f获得的共享特征将被引导学习到包含时间变化和不变的特征,这些特征将有效地传递到遥感下游任务中,无论它们是否涉及时序变化。同时,如果具备下游任务的先验知识,例如已知模型要迁移到变化检测任务中,而变化检测常常会被影像因季节变化导致的差异所干扰,则可使用具有时间不变性的嵌入子空间的特征。
2)针对SAR-光学不同模态构建正负样本对
针对遥感传感器成像机理多样这一特性,[6]设计了一种多模态(SAR-光学)对比学习范式,如图5所示。多模态对比学习使网络能够从不同的模态中学习互补信息,也就是说,它允许每个模态学习在其他模态中更明显可区分的特征,同时保留原始模态的特征。

3)针对可见光影像-Caption构建正负样本对
如图6,受到CLIP模型[8]启发,RemoteCLIP[9]基于现有的遥感数据集生成与每张遥感影像匹配的文本,基于海量遥感影像-文本对训练CLIP模型,学习稳健视觉特征的同时学习与视觉特征对齐的文本特征,从而使学习到的对齐视觉-语言表示可以无缝应用于不同的下游任务和领域,展现出色的零样本能力。

小结
遥感大模型的构建过程中是期望做到下游任务无关的,这保证了泛化性和迁移到各类下游任务的能力。人工智能技术的飞速发展驱动遥感大模型技术不断升级,作为变化检测、地物分类等下游任务的公共底座,理想的遥感大模型还应该具备以下特性:
1)处理来自不同传感器的遥感影像(不同的空间或光谱分辨率);
2)考虑到影像的地理位置和拍摄时间;
3)在不同的地貌和天气下良好工作,进行鲁棒的特征提取。
参考文献
- Wang D, Zhang Q, Xu Y, et al. Advancing plain vision transformer toward remote sensing foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 61: 1-15.
- Sun X, Wang P, Lu W, et al. RingMo: A remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022
- Cong Y, Khanna S, Meng C, et al. Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery[J]. Advances in Neural Information Processing Systems, 2022, 35: 197-211.
- He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 16000-16009.
- Manas O, Lacoste A, Giró-i-Nieto X, et al. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 9414-9423.
- Jain U, Wilson A, Gulshan V. Multimodal contrastive learning for remote sensing tasks[J]. arXiv preprint arXiv:2209.02329, 2022.
- Liu F, Chen D, Guan Z, et al. RemoteCLIP: A Vision Language Foundation Model for Remote Sensing[J]. arXiv preprint arXiv:2306.11029, 2023.
- Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PMLR, 2021: 8748-8763.
- Liu F, Chen D, Guan Z, et al. RemoteCLIP: A Vision Language Foundation Model for Remote Sensing[J]. arXiv preprint arXiv:2306.11029, 2023.
- Chen K, Liu C, Chen H, et al. RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model[J]. arXiv preprint arXiv:2306.16269, 2023.
- Kirillov A, Mintun E, Ravi N, et al. Segment anything[J]. arXiv preprint arXiv:2304.02643, 2023.
安利:Awesome-Remote-Sensing-Foundation-Models
GitHub - Jack-bo1220/Awesome-Remote-Sensing-Foundation-Models

