
- 1torch分布式训练报错_valueerror: error initializing torch.distributed u
- 2阿里7B多模态文档理解大模型拿下新SOTA|开源
- 3安装libasound.so.2的命令
- 4Resource 'taggers/averaged_perceptron_tagger/averaged_perceptron _tagger.pickle' not found.
- 5Python外星人入侵完整代码和注释(四)_pta拯救外星人
- 6【nlp自然语言处理实战】案例---FastText模型文本分类_使用faxttext模型进行文本分类训练
- 7unity切换场景,物体不销毁_不能销毁当前场景
- 8jieBa analyse.extract_tags_jieba.analyse.extract_tags
- 9Bash相关
- 10C语言课程设计||学生管理系统(简单版,超详细,看这一篇就够了)_c语言系统课
开源AI引擎|信息抽取与文本分类项目案例:提升12345政务投诉处理效率
赞
踩
一、实际案例介绍
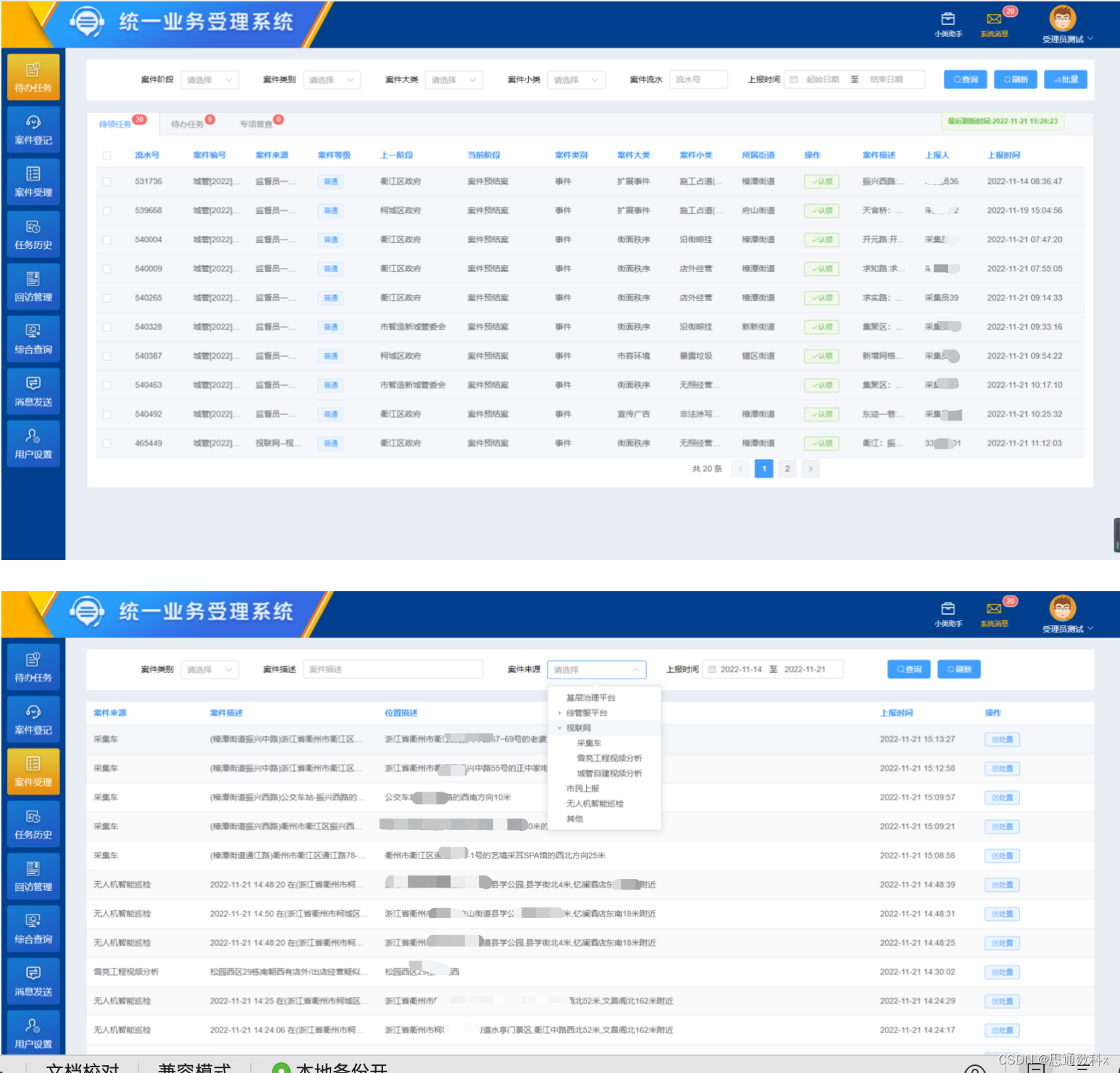
采集员案件上报流程是城市管理和问题解决的关键环节,涉及对案件类别的选择、案件来源的记录、详细案件描述的填写以及现场图片的上传。这一流程要求采集员准确、详细地提供案件信息,以便系统能够自动解析关键数据并填写相关内容,从而提高处理效率和准确性。
系统对采集员上报的信息进行自动解析后,将推荐合适的处理流程和责任部门,确保案件得到及时有效的处理。同时,采集员将收到案件处理的反馈,了解进展情况,这一闭环流程有助于提升城市管理的质量和效率,同时保障问题能够得到妥善解决。
传统的人工处理投诉方式不仅耗时耗力,而且容易受到主观判断的影响,导致处理结果的不准确和不一致。为了解决这一问题,自动信息抽取和文本分类技术应运而生,成为提升投诉处理效率和准确性的关键技术。
二、开源项目介绍
思通数科研发了一款多模态AI能力引擎,专注于提供自然语言处理(NLP)、情感分析、实体识别、图像识别与分类、OCR识别和语音识别等接口服务。该平台功能强大,支持本地化部署,并鼓励用户体验和开发者共同完善,以实现开源共享。
三、开源项目地址
AI多模态能力平台编辑https://gitee.com/stonedtx/free-nlp-api![]() https://gitee.com/stonedtx/free-nlp-api免费的自然语言处理、情感分析、实体识别、图像识别与分类、OCR识别、语音识别接口,功能强大,欢迎体验。
https://gitee.com/stonedtx/free-nlp-api免费的自然语言处理、情感分析、实体识别、图像识别与分类、OCR识别、语音识别接口,功能强大,欢迎体验。
四、在线体验地址
微信扫码登录,立刻体验 语音视频&文本图片多模态AI能力引擎平台编辑https://nlp.stonedt.com/![]() https://nlp.stonedt.com/
https://nlp.stonedt.com/
五、信息抽取技术
自动信息抽取(Automatic Information Extraction)技术是指利用自然语言处理(NLP)技术,从非结构化的文本数据中自动识别和提取出结构化信息的过程。这项技术能够从消费者投诉文本中抽取出关键信息,如消费者诉求、经营者未履行义务的原因、投诉和举报问题类别等,从而为后续的处理流程提供数据支持。
技术实现
实体抽取通常被视为一个序列标注问题,即将文本中的每个词分配一个标签,以表示该词是否为实体的一部分,以及它是何种类型的实体。这个过程通常包括以下几个步骤:
1.预处理:包括分词、词性标注等,为实体识别做好准备。
2.特征提取:利用词性、上下文、词形等信息作为实体识别的特征。
3.模型训练:使用有监督学习方法,如条件随机场(CRF)、隐马尔可夫模型(HMM)等,训练实体识别模型。
4.实体识别:模型对新的文本数据进行处理,识别出其中的实体。
六、文本分类技术
文本分类(Text Classification)技术则进一步将抽取出的信息按照预定义的类别进行分类。例如,系统可以根据投诉内容将投诉划分为质量类、服务类、价格类等不同类别,从而帮助企业快速识别问题所在,并采取针对性的解决措施。
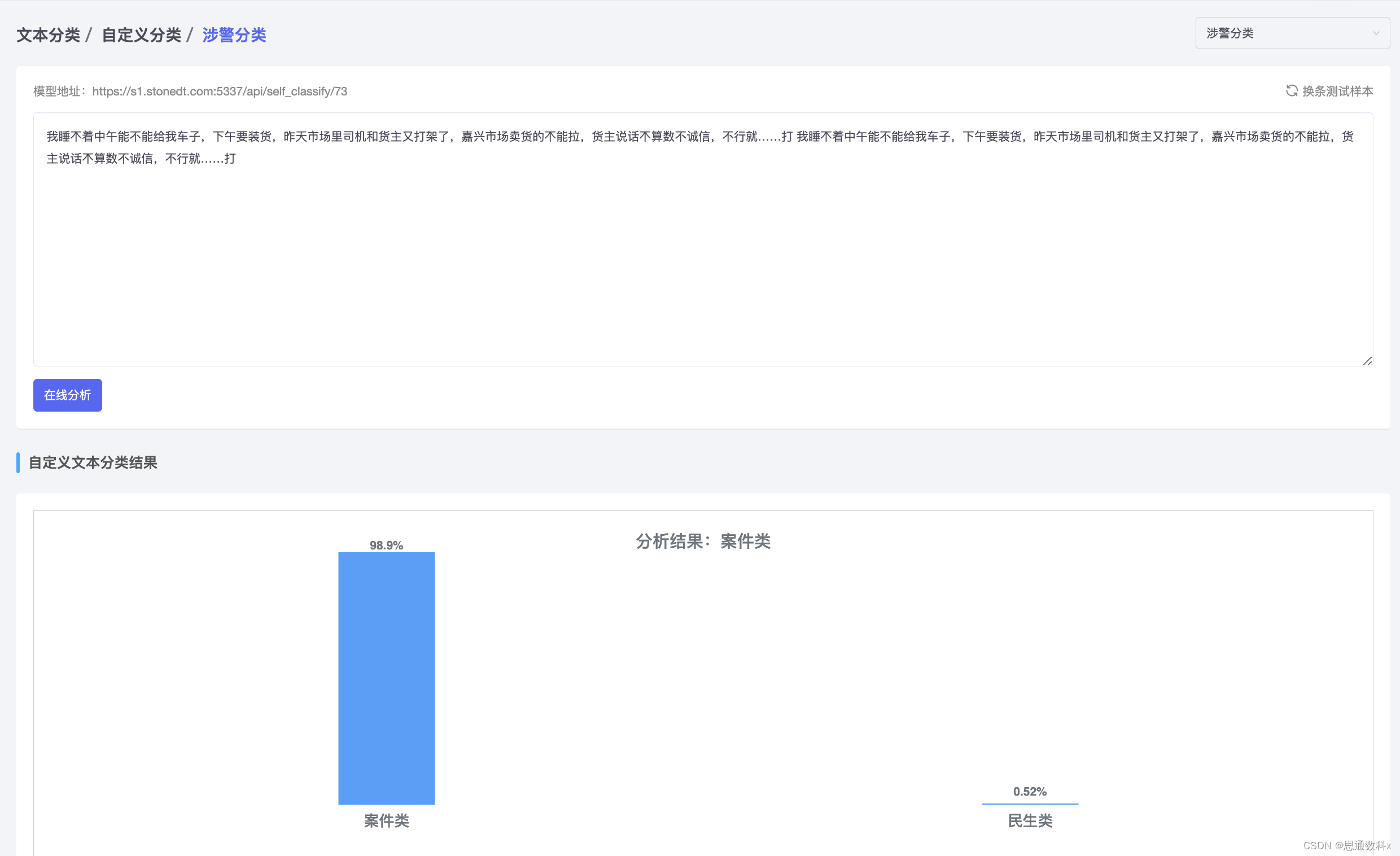
技术实现
实现自动信息抽取和文本分类的技术路径通常包括以下几个步骤:
1. 数据预处理:对原始投诉文本进行清洗、分词、去除停用词等操作,以便后续处理。
2. 特征提取:利用NLP技术提取文本特征,如词频、TF-IDF、词向量等。
3. 模型训练:选择合适的机器学习或深度学习模型进行训练,如支持向量机(SVM)、随机森林、神经网络等。
4. 模型应用与评估:将训练好的模型应用于新的投诉文本,进行信息抽取和分类,并不断通过反馈进行优化。
自动信息抽取和文本分类技术的发展,不仅提升了投诉处理的效率和准确性,也为企业提供了一个更加科学、客观的市场反馈分析工具。随着技术的不断成熟和应用,我们有理由相信,这一技术将为企业和消费者之间搭建起更加顺畅的沟通桥梁。

