
- 1UGUI系列——Canvas_ugui的canvas
- 2一些elementui table常用的样式调整~_element table样式调整实例
- 352个值得收藏的无代码AI平台【2024】
- 4电脑没有声音是怎么回事?几招快速解决
- 5UnityAndroid开发(1) 打包和使用Sqlite数据库_sqlite unity打包
- 6如何用Visual Studio自带工具分析内存泄漏?_vs诊断工具查内存
- 7element table组件实现show-overflow-tooltip效果,解决一些自带show-overflow-tooltip不能实现的效果。
- 8idea的Java窗体可视化工具Swing UI Designer的简单使用(一)_idea swing可视化
- 9维纳滤波-python实现_维纳滤波的python实现
- 10python毕设选题 - 大数据二手房数据爬取与分析可视化 -python 数据分析 可视化_基于python的房产大数据采集与可视化系统的设计与实现的毕业论文好写吗
LORA模型原理详解+分层控制使用
赞
踩

一、前言
LoRA模型全称是:Low-Rank Adaptation of Large Language Models,可以理解为Stable-Diffusion中的一个插件,仅需要少量的数据就可以进行训练的一种模型。在生成图片时,LoRA模型会与大模型结合使用,从而实现对输出图片结果的调整。假如一张图片是由背景,服饰,脸型,躯干,姿态等等组成,我们可以训练LORA模型对这些进行微调,在大模型的基础上微调成自己想要的图片。
简单理解就是大模型基础上额外增加一些训练层,在冻住大模型的基础上,训练lora模型。
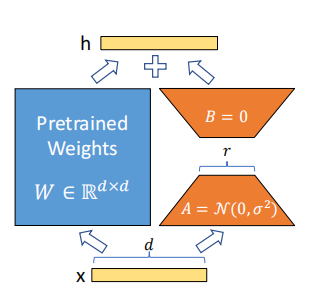
尽其实LoRA最开始是为大型语言模型提出的,但这种技术也可以应用在其他地方。在Stable Diffusion微调的情况下,LoRA可以应用于与描述它们的提示相关的图像表示之间的交叉注意力层。LoRA微调的优点包括:(论文)
- 训练速度更快
- 计算需求更低
- 训练权重更小,因为原始模型被冻结,我们注入新的可训练层,可以将新层的权重保存为一个约3MB大小的文件,比UNet模型的原始大小小了近一千倍。
现在的LORA模型根据网络层数不同一般为144M,72M,36M
二、使用(lora分层控制)
1.安装插件
https://github.com/hako-mikan/sd-webui-lora-block-weight
安装方法就不介绍了,扩展界面安装,压缩包解压放到扩展目录,git clone,都行
如果想要充分利用lora模型,分层控制是必须的
lora模型一共17层组成,第一层为开关,其他16层分别控制着lora的人物背景姿态服装,有时候lora效果很好但是有一些背景服装想要更改,加上提示词发现效果不大,降低lora权重又使图片不符合预期,分层控制就排上大用场了,把服装权重降到0,提示词就可轻松换装,对与不同lora叠加使用也有了更好的效果,相信你的小脑袋已经有了很多想法了,服饰,背景,脸分别采用不同lora模型,也不用担心模型的叠加使人物崩坏了。
2,打开webui
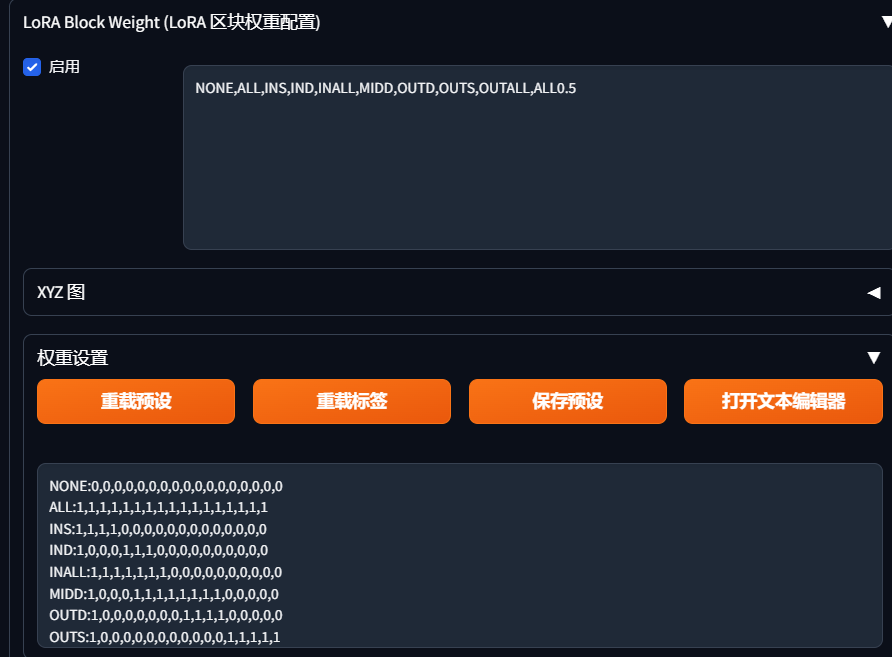

我自己使用了,效果还行,使用如下,例如去除lora服装效果
<lora:tianfeng_cutegirls5:1:1,1,1,1,1,1,0,1,1,1,0,1,1,1,1,1,1>,
:1,1,1,1,1,1,0,1,1,1,0,1,1,1,1,1,1 是自己加入的,分别是17层,第一层必须是1
- 1
- 2
再去除脸型
<lora:tianfeng_cutegirls5:1:1,1,1,1,1,1,0,1,0,0,0,1,1,1,1,1,1>
- 1
图片不放了,多少有点不雅,反正效果没问题,这里我做实验了,没问题
好了,到此结束吧!

