
热门标签
热门文章
- 1Android Studio音频视频播放器课程设计_androidstuiod做视频播放器需要用到什么技术
- 2firewalld:禁ping设置_icmp-block-inversion
- 3如何利用 GPT4创建引人注目的流程图_gpt 绘制流程图
- 4机器人机械臂抓取综述_机械臂平面抓取
- 5ros2 launch如何控制node的启动顺序_ros2 launch文件先后启动顺序
- 6Python之密码设置_python一个合格的密码应该符合下面规则: 密码至少有8个字符。 密码包括
- 7在19计算机考研炸掉的情况下,21计算机考研的难度会很大吗?
- 8嵌入式人工智能是一个怎样的概念呢?
- 9Python爬取淘宝商品评价信息实战_python 获取商品评论
- 10从 CoT 到 Agent,最全综述来了!上交出品_cot 大模型
当前位置: article > 正文
ollama+anythingllm==构建本地知识库_ollama anythingllm
作者:2023面试高手 | 2024-05-13 22:02:48
赞
踩
ollama anythingllm
1-安装ollama和运行模型
安装ollama,自动安装到C盘
配置ollama环境变量,调整模型存放的位置
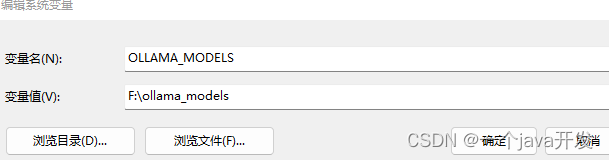
右下角退出ollama程序,然后再次启动
ollama run llama3
此时模型会被自动下载到环境变量配置的地址,并且启动一个对话界面
输入/bye退出对话界面
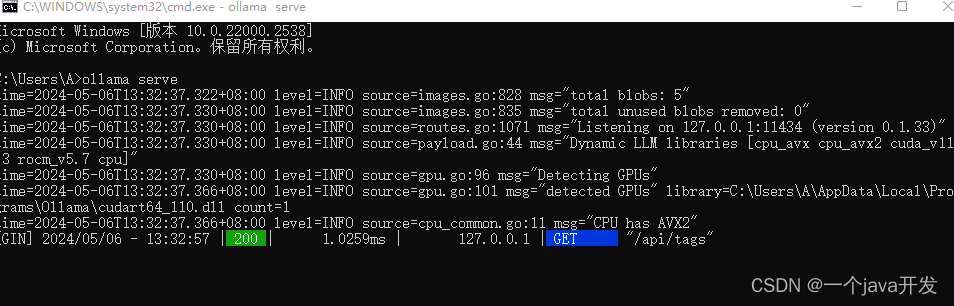
将ollama启动成一个后端服务器ollama serve
2-下载安装anythingllm
下载安装anythingllm
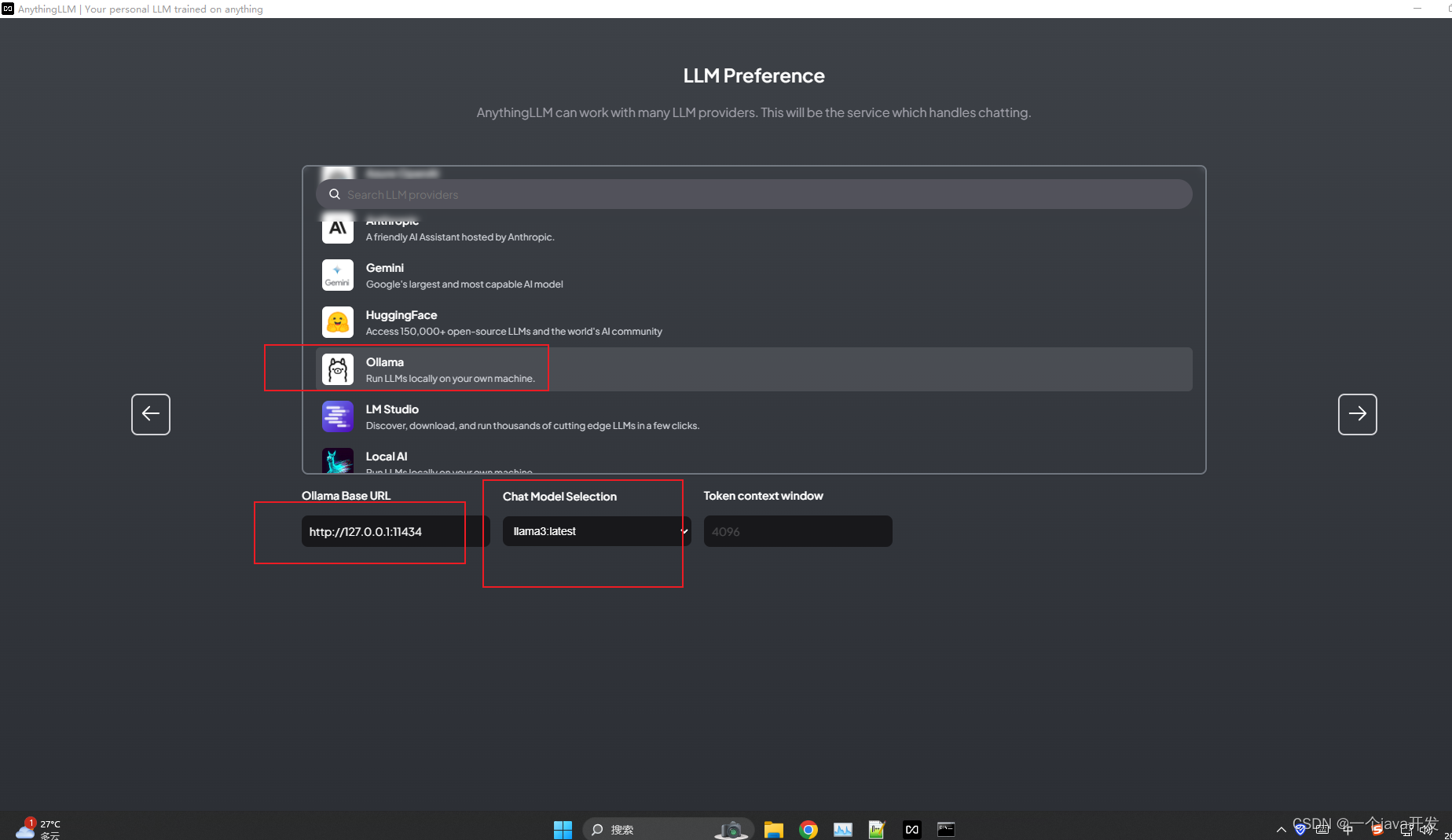
安装完成后打开,输入ollma服务器的地址,然后可以选择使用ollama中的哪个模型
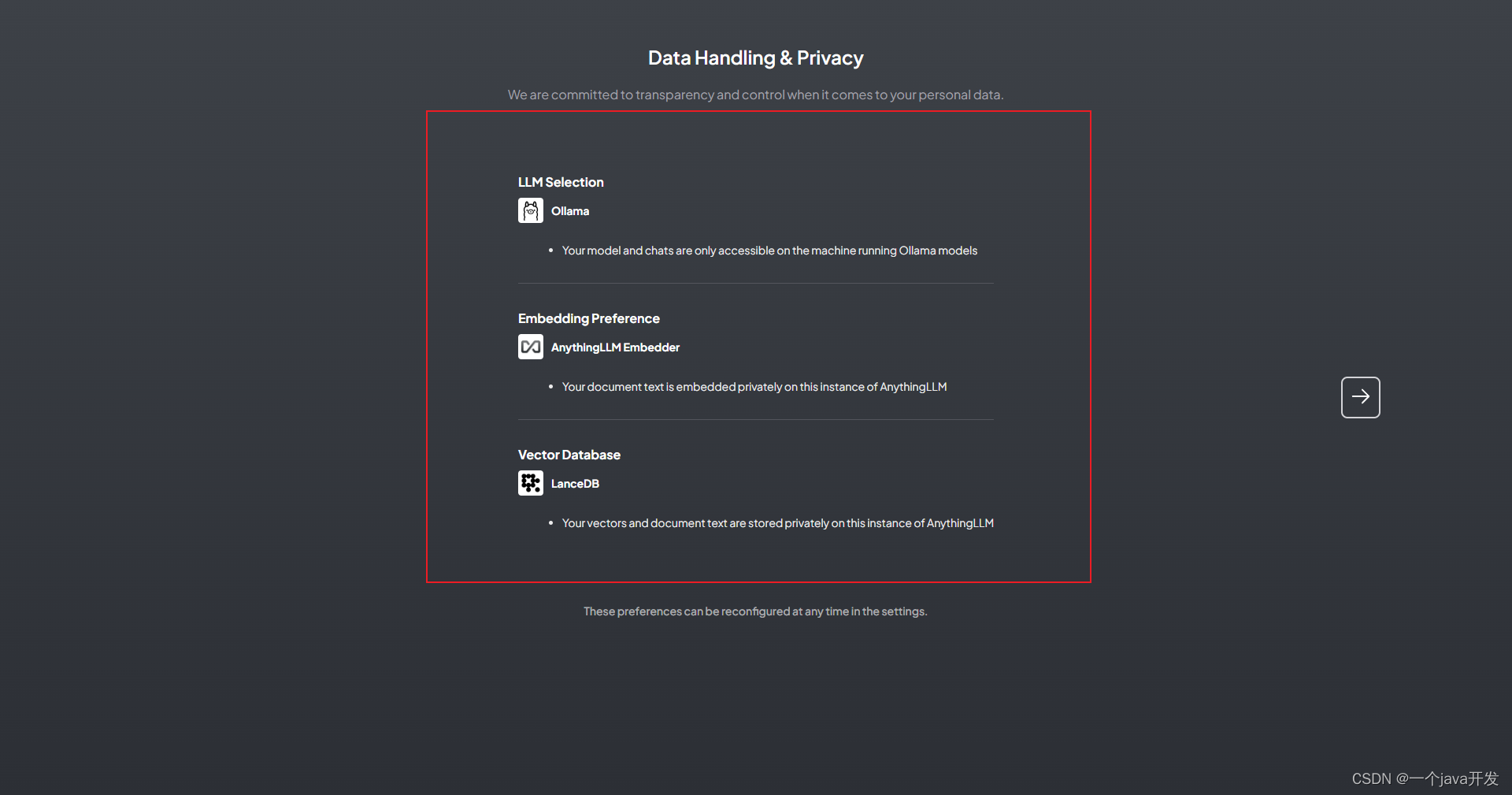
可以看到默认的向量数据库配置
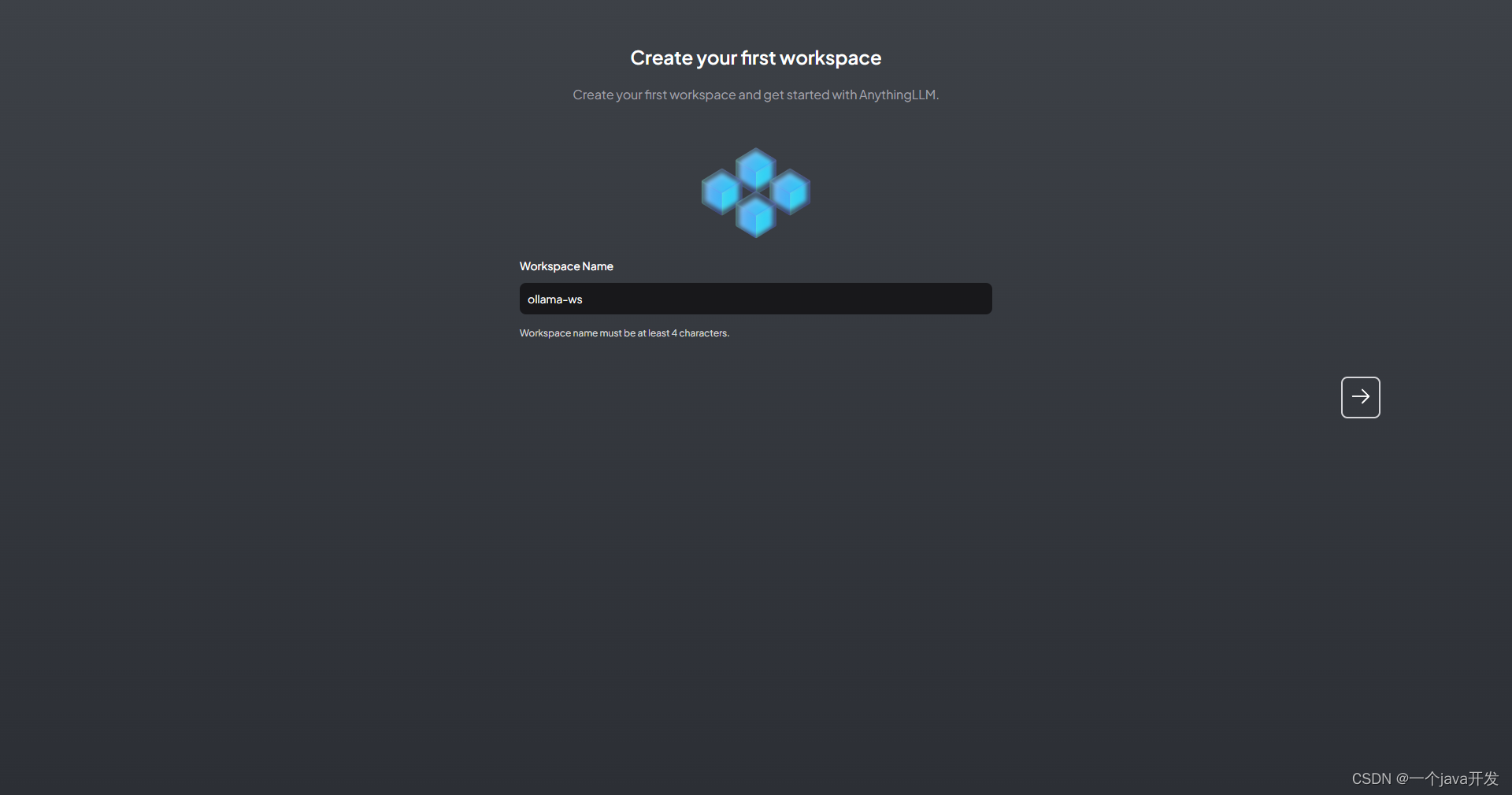
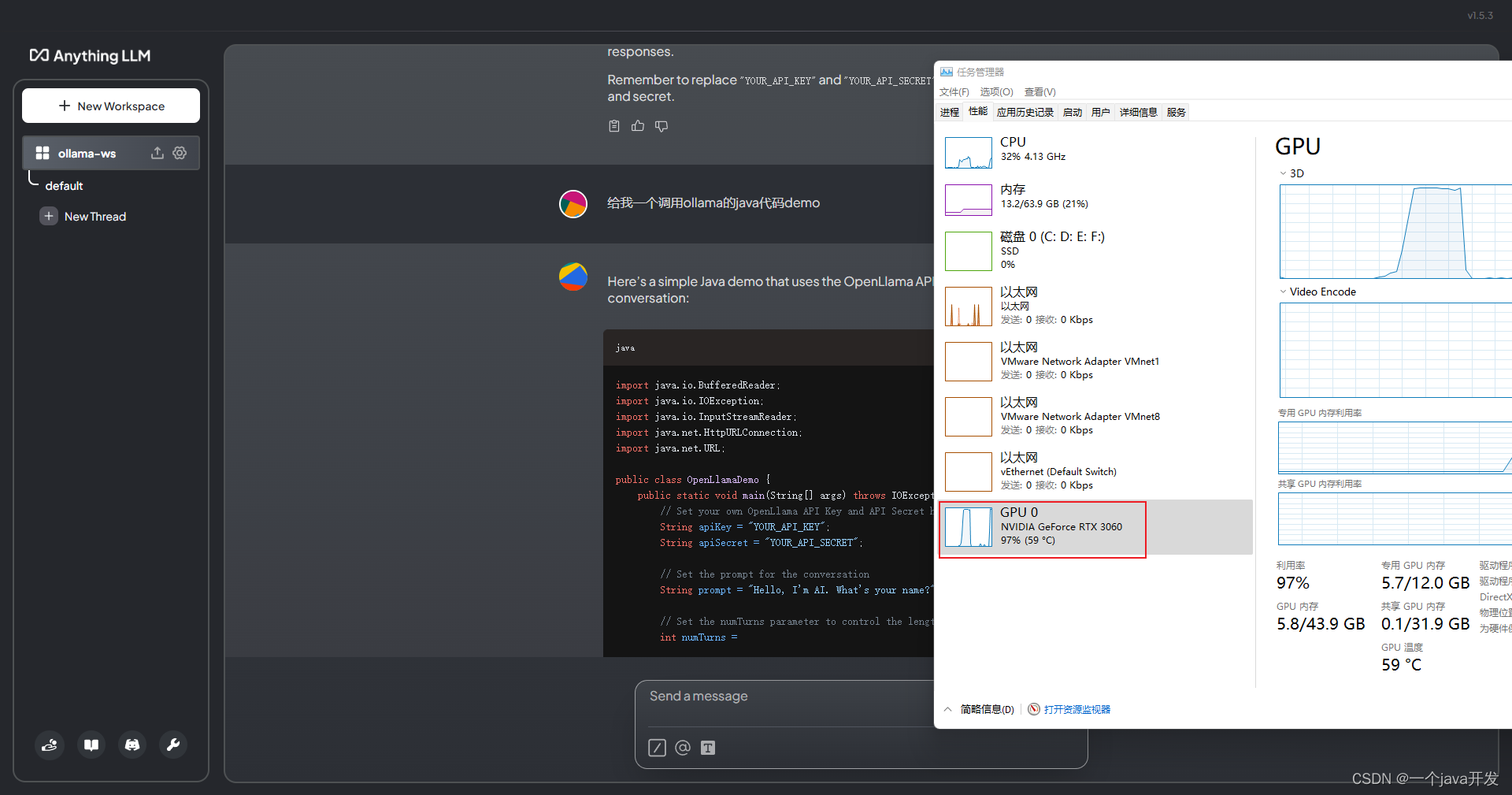
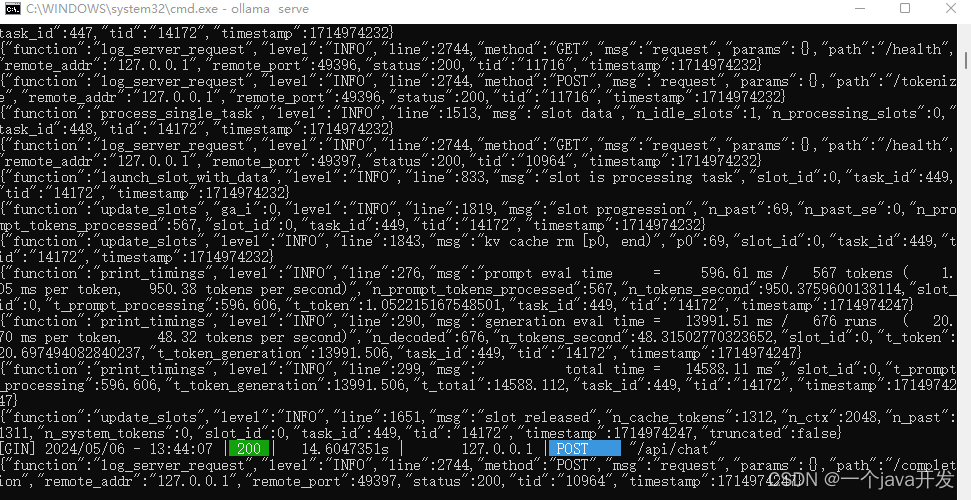
测试下文本问答,可以看到走的GPU,并且可以在ollama服务端看到了来自anythingllm的请求日志
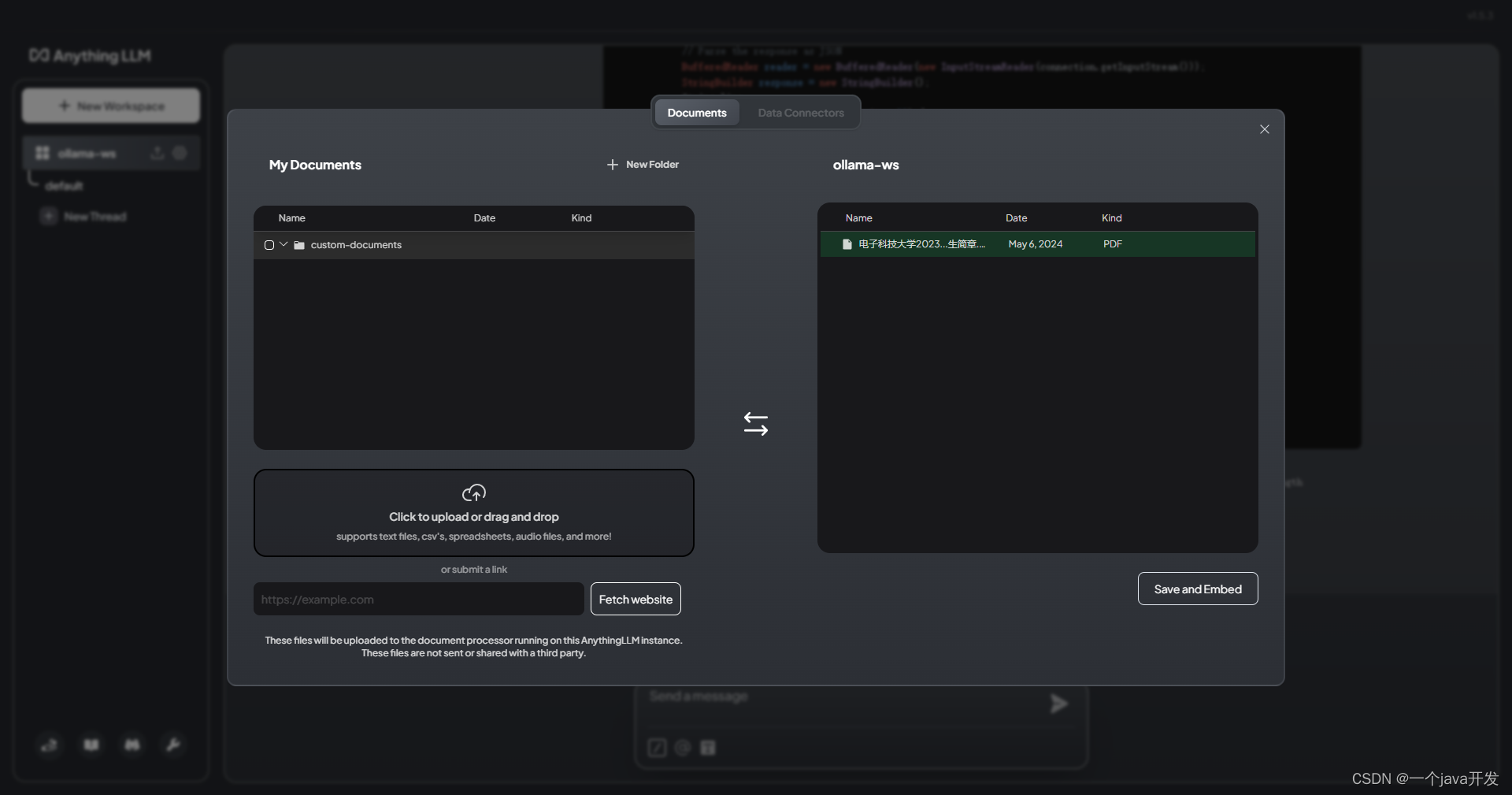
3-矢量数据库。本地文档知识库
上传文件并且move to workspace
save and embed
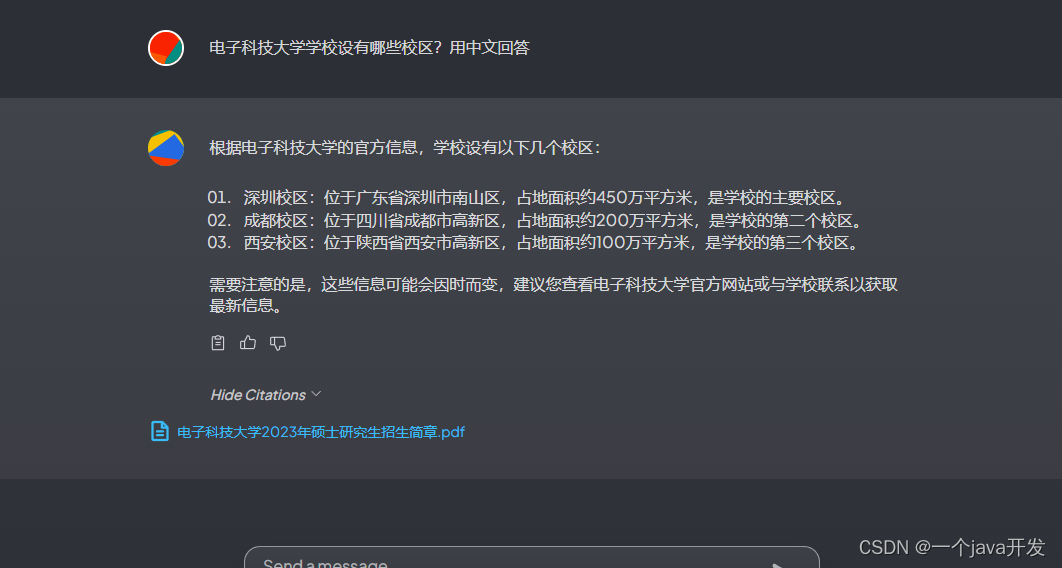

根本不准,可能是文档不太行。
自己写手写个TXT吧,我在TXT里写的内容为
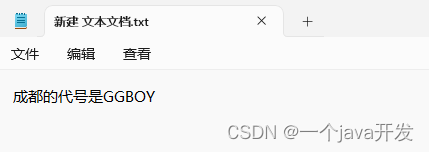
上传TXT并向量化
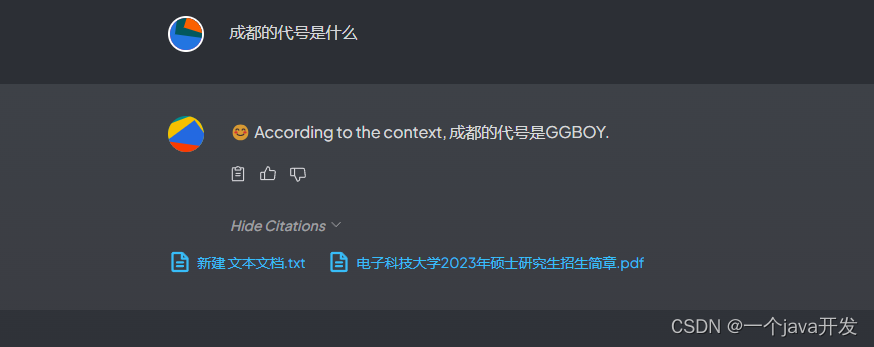
然后再问,可以发现这下准了,所以准确度还是对投入的文档有一定的准确度要求的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/565886
推荐阅读
相关标签

