
孟德尔随机化法(Mendelian Randomization,MR)
赞
踩
一、工具变量
参考:https://www.zhihu.com/question/29067965
在构建回归模型时,一般将因变量 Y Y Y 拆成两部分,自变量 X X X 和随机误差 ε ε ε。若 X X X 与 ε ε ε 之间存在相关性,则在构建回归模型的时候,导致对 X X X 的参数 β β β 估计不准。如果能找到一个过滤器,把 X X X 中和 ε ε ε 相关的部分过滤掉,只剩下与 ε ε ε 无关的部分,则可以准确估计参数 β β β。工具变量是指与自变量 X X X 相关而与 ε ε ε 无关的变量,工具变量可以作为过滤器,去除 X X X 中与 ε ε ε 相关的部分。具体操作如下:
以工具变量 Z Z Z 作为自变量,对 X X X 进行回归,记回归后的因变量为 X ′ X^{\prime} X′。 X ′ X^{\prime} X′ 有且仅用 Z 表达,而 Z 与 ε 无关,所以 X ′ X^{\prime} X′ 与 ε ε ε 无关。这样就把 X X X 分成两个部分,由 Z Z Z 决定的部分 X ′ X^{\prime} X′ 和于 Z Z Z 无关的部分。与 Z Z Z 无关的部分包含了我们认为 X X X 中蕴含着的和 ε ε ε 相关的部分。去除 X X X 中与 ε ε ε 相关的部分很简单,即用拟合值 X ′ X^{\prime} X′ 来替换 X X X,所有和我们无法控制的因素 ε ε ε 相关的都被工具变量 Z Z Z 过滤掉了,代入到原来的方程式中回归,就能得到更准的估计了。
需要注意的是, X X X 中与 Z Z Z 无关的部分不仅包含与 ε ε ε 相关的,还包括与 Z Z Z 不相关且与 ε ε ε 也不相关的部分。所以为了尽可能准确的表示 X X X,可以使用多个工具变量来尽可能的减少不必要的过滤。
理想情况下,工具变量 Z Z Z 和自变量 X X X 强相关,然后和 ε ε ε 无关;但是有时候 Z Z Z 虽然和 ε ε ε 无关,但是和 X X X 的相关性并不强,用 Z Z Z 所能表示的 X X X 太少,这就相当于过滤网孔太细,能够留下来的东西太少,受到样本抽样的影响也会很大,此时我们称 Z Z Z 为弱工具变量。所以正确选择合适的工具变量是关联研究的重点与难点。
二、孟德尔随机化法
1986年,Katan 首次提出 MR 的遗传思想:亲代等位基因随机分配给子代,如果基因型决定表型,基因型通过表型而与疾病发生关联,因此可以使用基因型作为工具变量来推断表型与疾病之间的关联。MR 设计的最关键步骤是寻找合适的 SNP 作为工具变量。
根据 基因-mRNA-蛋白质-表型,通过 GWAS 我们可以找到表型与基因型之间的相关性。但 GWAS 只能找寻关联,无法确定因果。找到的 SNP 是与表型间存在因果关系,还是由于其他未知因素 U 而导致的假阳性,我们无法验证。以前常用的做法是敲除 SNP 附近的基因,观察表型是否按照预想的情况发展。随着多组学的发展,为使用工具变量提供了可能,可以使用多组学验证来确定SNP与表型之间是否存在因果关系。 假设 GWAS 中与表型显著关联(超过阈值)的 SNP 的区间内有基因 A,如果基因 A 与表型存在因果关系,那么受基因 A 调控(以基因 A 的表达量为表型进行 GWAS )或调控基因 A(以转录组为表型进行 GWAS,所有在基因 A 区间出峰的基因)的 SNP 的区间内基因 B 也应该与表型之间显著关联,但基因 B 可能不含有导致基因 A 与表型存在关联的未知因素 U。所以如果基因 B 与表型之间无关联,那么我们可以判断基因 A 可能为假阳性结果;如果基因 B 与表型之间存在关联,那么我可以判断基因 A 可能与表型存在关联。基因 A 与表型存在关联的可信度与基因 B 的质量直接相关:如果基因 B 功能已知、效果单一且与基因 A 直接强关联,那么基因 A 则大概率与表型相关;如果基因 B 功能不清,与基因 A 相关性一般,那么基因 A 则可能与表型相关。当我们以组学角度研究问题是,一般基因 B 的功能是难以清晰了解的,主要的筛选方法是与基因 A 的相关性,即以基因A的表达量或转录组为表型进行 GWAS 时的 p-value,所以基因 B 常用于排除假阳性。利用基因 B 我们可以筛选掉一部分假阳性的基因,基因 B 我们这里称为工具变量。
MR 设计的常用策略:
① 一阶段 MR(One stage MR):最早的 MR 研究设计是由 G G G- X X X 和 G G G- Y Y Y 的关联来推断 X X X- Y Y Y 的关联。因为没有 X X X- Y Y Y 因果效应大小的估计,只是通过推断来估计 X X X 与 Y Y Y 的可能关联,比如,KIV-2 基因拷贝数变异与血浆脂蛋白 Lp(a)含量有关,同时又与心肌梗死的发生率有关,因此推断 Lp(a)含量与心肌梗死的发生有关。
第一步:通过 G G G- X X X 和 G G G- Y Y Y 的回归模型获得回归系数 α g α_g αg 和 δ g δ_g δg;第二步:计算获得 X X X- Y Y Y 回归模型系数 β x = δ g / α g β_x=δ_g/α_g βx=δg/αg。
② 独立样本 MR(One-sample MR):该方法通过使用 2 阶段最小二乘法回归模型(2-stage least-squares regression,2SLS),定量估计暴露因素 X X X 与 Y Y Y 之间的关联效应大小。
PS:2SLS是指连续建模两次最小二乘法回归模型。第二次建模的自变量值为第一次建模的回归值。
第一步:建立
G
G
G-
X
X
X 回归模型,获得暴露因素预测值(predicted value,
P
P
P)
第二步:构建
P
P
P-
Y
Y
Y 的回归模型,即获得暴露因素预测值
P
P
P 和变量
Y
Y
Y 之间的回归方程。
④ 双向 MR(Bidirectional MR):若遗传变异 G 1 G_1 G1 与 X 1 X_1 X1 和 X 2 X_2 X2 将都有关联,但是遗传变异 G 2 G_2 G2 与 X 2 X_2 X2 有关却与 X 1 X_1 X1 不存在关联,则可能 X 1 X_1 X1 为因而 X 2 X2 X2 为果。在 “独立样本 MR” 和 “一阶段 MR” 中通过 G G G 仅能确定 X X X- Y Y Y 关联,但是无法判断方向,即 X X X- Y Y Y之间的因果关系。而 双向 MR 有助于确定相关性的方向。如 Timpson 等在双向 MR 设计中使用肥胖基因 FTO( G 1 G_1 G1)和 CRP 基因( G 2 G_2 G2)作为工具变量,研究 BMI( X 1 X_1 X1)和CRP水平( X 2 X_2 X2)之间的关系。作者通过 FTO 基因与 BMI、CRP 水平之间有显著性关联,而 CRP 基因与 BMI 之间无显著性关联,推断 BMI 可能为因而 CRP 水平可能为果。此方法在解决因果网络方向的问题上将会有很大用途。
但需要注意的是,在借助工具变量 G 1 G_1 G1 判断 X 1 X_1 X1- X 2 X_2 X2 之间的相关性时,必须考虑 G 1 G_1 G1 是否存在一因多效的情况。如果 G 1 G_1 G1 与 X 1 X_1 X1、 X 2 X_2 X2 相关,但 X 1 X_1 X1 与 X 2 X_2 X2 之间无直接的相关性,是通过 G 1 G_1 G1 而构成相关性,那么 G 2 G_2 G2 的使用会误导研究者认为 X 1 X_1 X1 是 X 2 X_2 X2 的因。为了排除 G 1 G_1 G1 是一因多效的可能性,可以使用多个与 X 1 X_1 X1、 X 2 X_2 X2 相关的工具变量,综合考量。
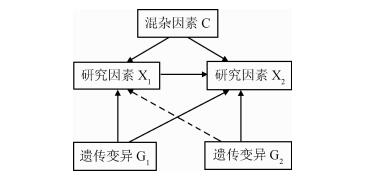
MR 对关联性的分析已经对因果方向的判断,可以用于构建网络。如在通过 GWAS 找到了许多与表型相关的位点,用 MR 可以判断这些位点与表型间的相关性是否可靠,同时还可以判断位点间是否存在因果关系,即 GWAS 挖掘到的位点之间可能是存在上下级调控关系的。当然,不只是 GWAS 的结果,任何可以找寻相关性的方法的结果都可以利用 MR 进行验证并说明因果关系,如通过机器学习找到的与表型相关联的 SNP 位点。

