
- 1窗口与视口的区别_视口与窗口
- 23.7 TCP 拥塞控制_接收端不支持拥塞控制怎么解决
- 3Flyway 搭建_flyway配置
- 4Runes_you are helping an archaeologist decipher some run
- 5elememt-plus的表格的增删改查#Vue3无需json数据,无需后端接口
- 6Yolov5 转换成 RKNN模型_yolov5转rknn
- 7EasyDSS视频直播点播平台如何修改登录密码与开启接口鉴权?_easydss 播放鉴权验证
- 8《YOLOv7高阶自研》专栏介绍 & CSDN独家改进创新实战& 专栏目录
- 9有哪些软件可以一键发布多个自媒体平台?这6个平台一定要收藏
- 10凯雷调整收购Veritas价格 赛门铁克少收14亿美元
AST 浅析_ast asm
赞
踩
前言
Aspect 语法难懂?ASM 字节码操作繁琐?APT 难以精准找到切入点?你该试试 AST 了!编辑器级别,效率高,更轻量。
一、概念
在开始上手之前,我们先了解下几个简单的概念:
什么是 AST ?AST 的作用?
我们知道,编程语言再怎么变,不变的是由「类型」「运算符」「流程语句」「函数」「对象」组成的本质,这些本质概念表达了底层的运算与逻辑,那么这么多编程语言,要怎么抽离出这个逻辑本质呢?
答案就是:转化为统一的结构!
这个统一的结构不依赖于源语言的语法,只代表源语言中的语法结构,如类型、修饰符、运算符……
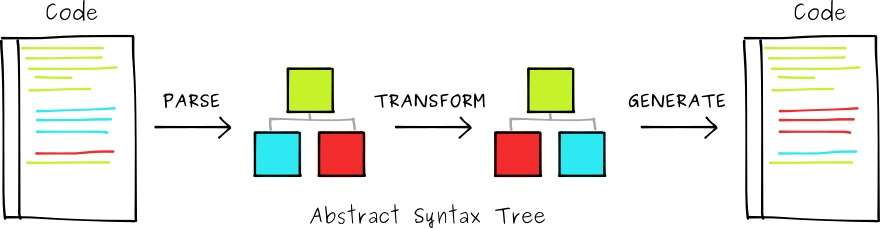
这就是抽象语法树 AST。AST(abstract syntax tree)即抽象语法树,是源代码的抽象语法结构的树状表现形式,每一个节点代表一个语法结构。那 AST 是怎么转化得来的呢?
AST 的生成过程
不同的语言,都会有对应不同的语法分析器,语法分析器会把源代码作为字符串读入、解析,并建立语法树,这是一个程序完成编译所必要的前期工作。
我们看下 Java 的编译过程,重点关注步骤一和步骤二:

步骤一:词法分析,将源代码的字符流转变为 Token 列表。
一个个读取源代码,按照预定规则合并成 Token,Token 是编译过程的最小元素,关键字、变量名、字面量、运算符等都可以成为 Token。
步骤二:语法分析,根据 Token 流来构造树形表达式也就是 AST。
语法树的每一个节点都代表着程序代码中的一个语法结构,如类型、修饰符、运算符等。经过这个步骤后,编译器就基本不会再对源码文件进行操作了,后续的操作都建立在抽象语法树之上。

- 可以访问 Astexplorer 在线玩转 AST
怎么利用 AST?
我们可以发现,AST 定义了代码的结构,通过操作 AST,我们可以精准地定位到声明语句、赋值语句、运算语句等,实现对源代码的分析、优化、变更等操作。
举个例子,想要改变 a 的赋值,如下图:
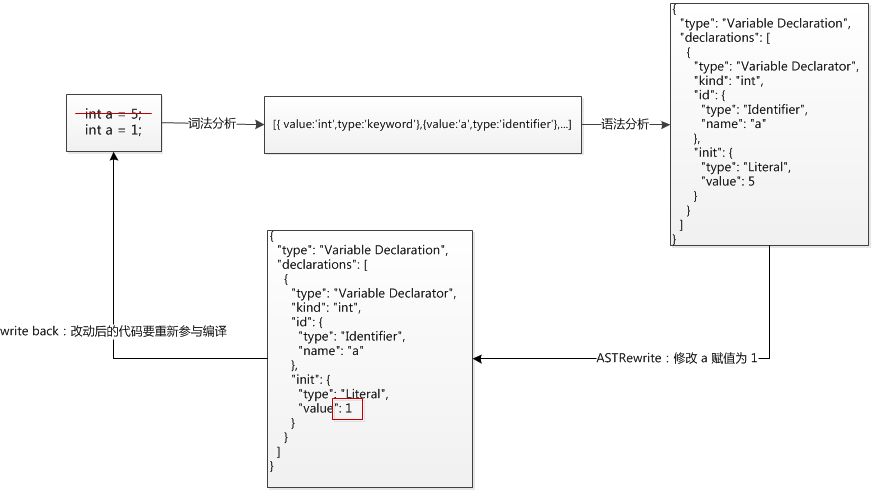
想改 a 的赋值,可以对 AST 语法树的 value 节点下手,一旦改动,编译器会重新进行编译流程处理,此时赋值改动就反映到源码上了。是不是很神奇?其实 Lombok、IDE 语法高亮、IDE 格式化代码、自动补全、代码混淆压缩、甚至大名鼎鼎的 ButterKnife 的 R、R2 文件映射和静态代码检查,都是利用了 AST。
既然要操作 AST,我们怎么拿到 AST 呢?
答案是:在注解处理器 APT!
利用 JDK 的注解处理器,可在编译期间处理注解,还可以读取、修改、添加 AST 中的任意元素,让改动后的 AST 重新参与编译流程处理,直到语法树没有改动为止。

AST优缺点
相比其他的AOP方法,AST 属于编辑器级别,时机更为提前,效率更高。
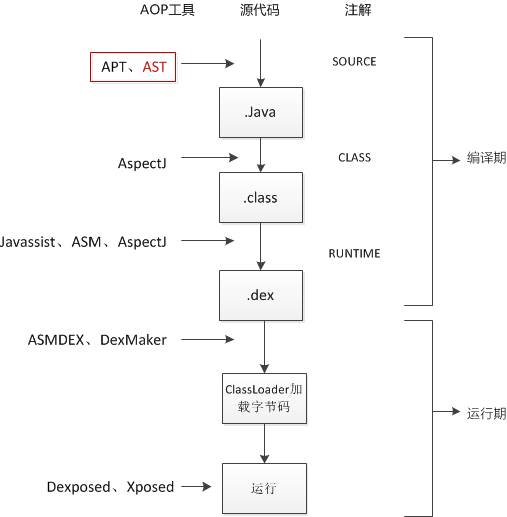
但语法复杂,推荐通过库来操作 AST:
二、实践
实现一个清除 log 功能
整体思路:在编译期间拿到 AST,扫描是否含有特定日志语句如:Log,存在则删除该语句。
1. 实现 AbstractProcessor

2. 添加注解
@SupportedAnnotationTypes 指定此注解处理器支持的注解,可用 * 指定所有注解@SupportedSourceVersion 指定支持的java的版本

3. 获取 AST

在注解处理器的 init 函数里,通过 Trees.instance(env) 拿到抽象语法树(AST)。
此处把ProcessingEnvironment强转成JavacProcessingEnvironment,后面的操作都变成了IDE编辑器内部的操作了。
4. 操作 AST
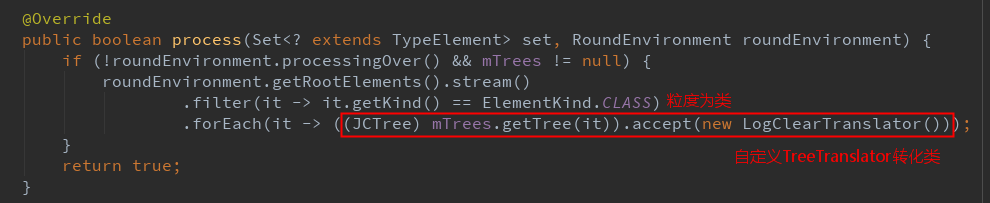
在注解处理器的 process 函数中,我们扫描所有的类,实现一个自定义的 TreeTranslator。
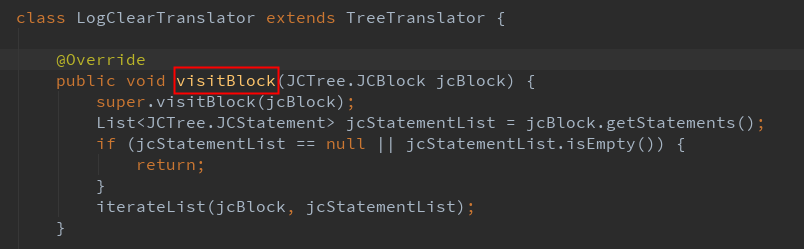
为什么自定义的 TreeTranslator 要复写 visitBlock?因为我们的需求场景是扫描所有 log 语句,粒度为语句块。AST 支持我们以不同的粒度去访问,还有哪些粒度呢?我们看下TreeTranslator 的继承层次,可以发现一个 Visitor 类。

打开 Visitor 类:
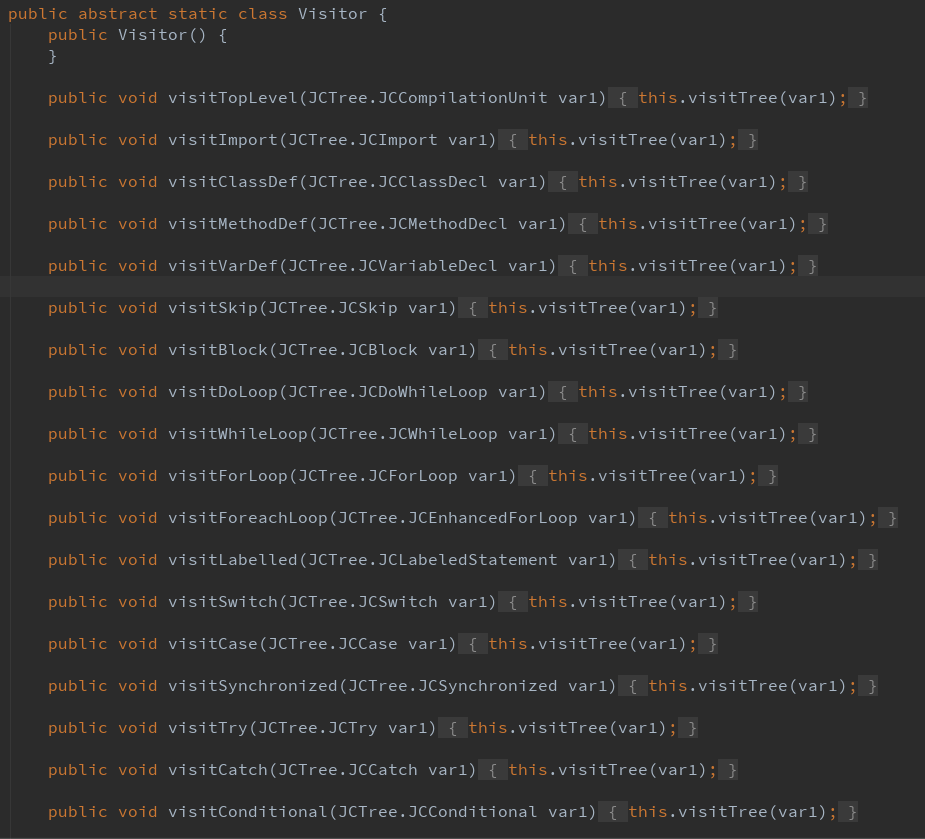
所有 visit 方法一目了然,我们前面提到 AST 每一个节点都代表着源语言中的一个语法结构,所以我们可以细粒度到指定访问 if、return、try等特定类型节点,只需覆写相应的 visit 方法。
回到我们的需求场景:扫描所有 log 语句,既然是语句,粒度应该为语句块,所以我们覆写 visitBlock 进行扫描,当扫描到指定语句比如 Log. 时,就不把整个语句都写入 AST,以此达到清除 log 语句的效果。
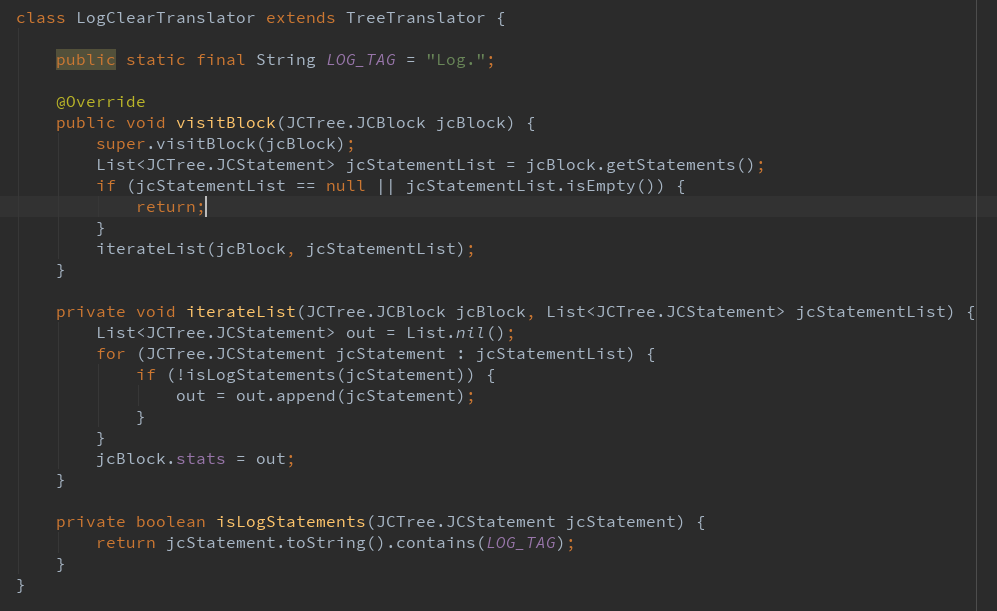
- 想了解更多 AST 操作语法?详见 java注解处理器——在编译期修改语法树
- 想获取 demo 源码请戳
剖析 ButterKnife
有了实战的基础,我们再来看看 ButterKnife 是如何利用 AST 的。全网对这块的讲解少之又少,解析只着重于 APT,实在可惜。
细心的你会发现在 ButterKnife 的 sample-library 中,注解的都是引用了 R2 :

为什么 library 工程不直接引用 R?当我们把 R2 改成 R 之后,编译器会报错:

也就是说注解的属性必须是常量,但是 library 中 R.id.title 的值为变量。原因见 Non-constant Fields in Case Labels.、Android主项目和Module中R类的区别。
那我们可以拷贝下 R 文件,生成一个 R2,把属性都改为常量即可解决。为了让这个拷贝过程无感知,J 神使用了 gradle 插件来自动化完成,这就是 library 需要引用 butterknife-gradle-plugin 的原因。
那另一个问题来了,R2 仅仅是 module 中 R 的复制,只代表了所在 module 编译期间 R 的值,在运行时主工程的 R 和 R2 完全对不上,单纯地拷贝修改是不行的。咋整呢?
那我们生成 R2 供编译期使用,在生成代码阶段把 R2 替换成 R 不就行了?好主意!J 神的思路就是这样的!我们打开生成的 XXX_ViewBinding 文件就可以发现 —— R2 已经被换成了 R。

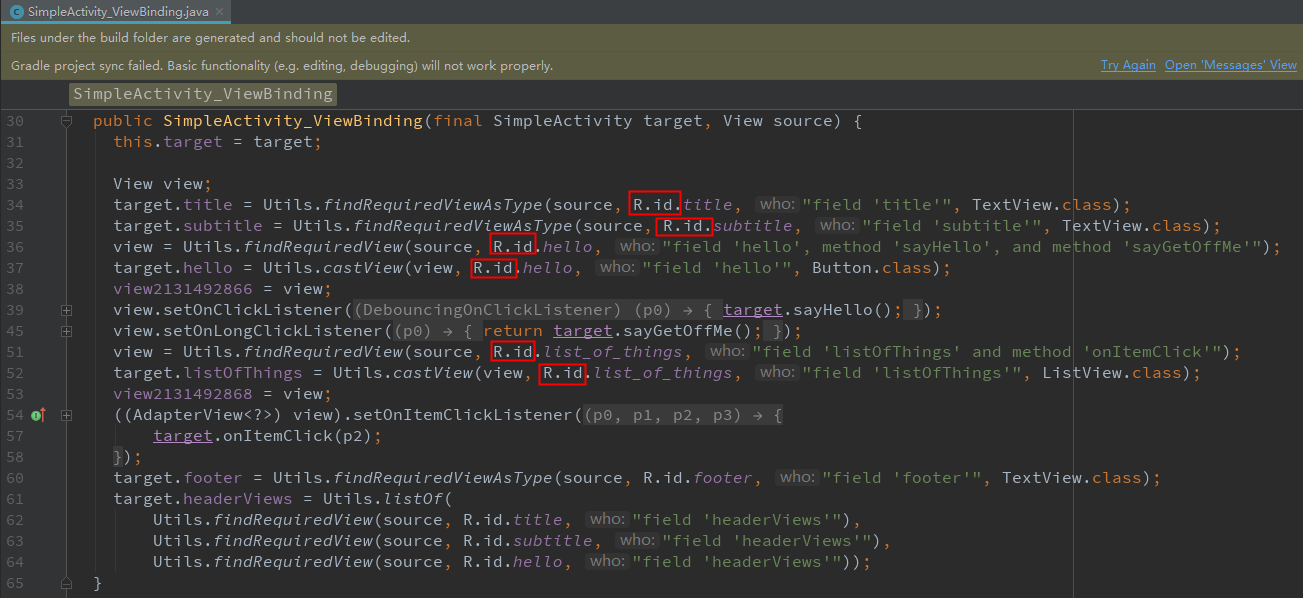
但是怎么拿到 R 和 R2 的映射呢?
我们思考下:以 @BindView(R2.id.view) 为例,最终生成的代码是 findViewById(0x7f…)。那我们通过 0x7f… 反寻 R2.id.view 这样的常量名,R 和 R2 一样,所以也连带知道了 R.id.view 变量名,于是可以将生成代码的结果从 findViewById(0x7f…) 替换成 findViewById(R.id.view) ,这里的 R 在主工程的编译过程中会被 inline 成最终确定的数值,从而避免在生成代码的过程中直接填写数值带来的麻烦。
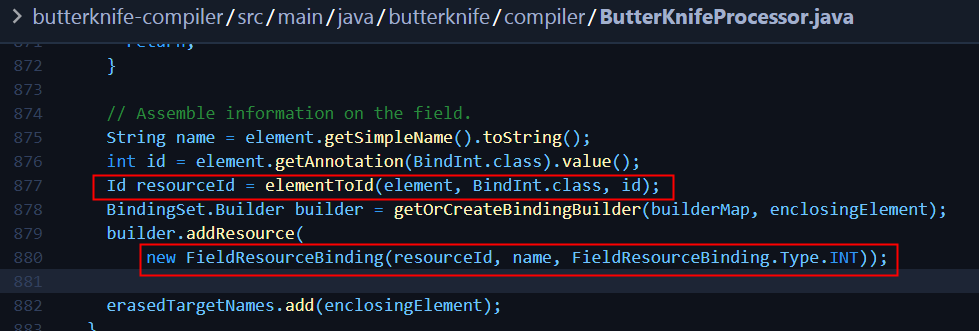
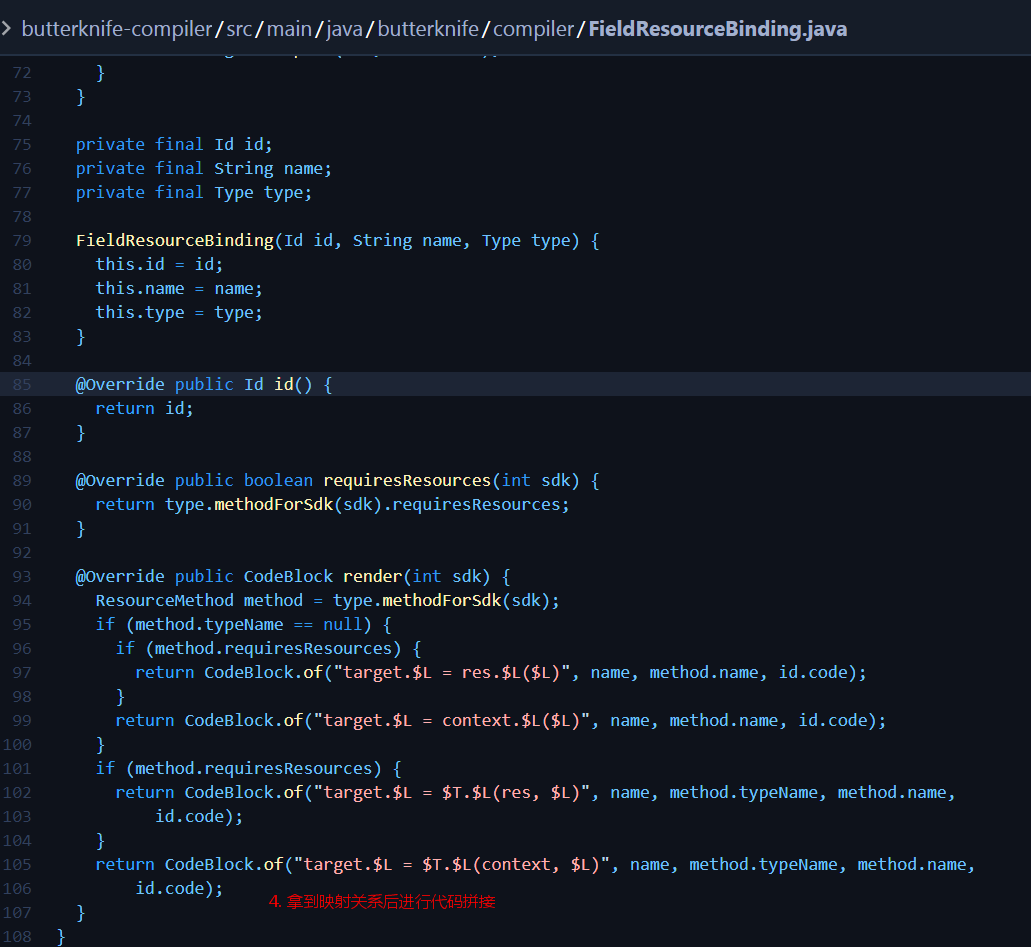
思路确定了,那接下来第一步就是通过 0x7f… 反寻 R2.id.view ,但是在 APT 里,我们只能拿到 Element 的注解值,也就是说,并不知道当前传入的是 R2 的哪个 field。现在就该轮到 AST 大显身手了,根据 Element 反查出真正 Java 文件的树形结构。
- 拿到AST树;

- 在扫描资源时,获取 Element AST 树,注入自定义的 TreeScanner 访问器 RScanner 来访问子节点;

- RScanner 寻找 R 文件内部类(id、string等)),建立 view 与 id 的关系;

- 拿到映射关系后,进行代码拼接。
扩展
AST 应用场景扩展
你以为 AST 的应用场景就这么多了吗?
不不不,我们开下脑洞,既然拿到了源代码的树形表达式,我们不一定要把表达式转回成源码,那是不是可以通过它自动写代码?画个源码流程图?画个类图?写个说明文档?或者其它你想要的东西?
看看这个项目 js-code-to-svg-flowchart,或许能给带你更多灵感。
对 AST 仍有疑问?
也许下面这些资料可以答疑:
想了解其他 AOP 方法?
本篇完成耗时 24 个番茄钟(600 分钟)
作者:FeelsChaotic
链接:https://www.jianshu.com/p/0f1c7b3e907f

