
- 1软件开发人员的 5 项能力:如何识别优秀的程序员_软件技术能力体现
- 2128种chatGPT可以为人类做的事情_统计chatgpt 能做的任务类型
- 3shell中 -eq,-ne,-gt,-lt,-ge,-le数字比较符(整数值操作符)_shell gt
- 4SpringBoot系列——Jedis使用配置详解_springboot jedis连接池配置
- 5用23种设计模式打造一个cocos creator的游戏框架----(四)装饰器模式_cocos creator框架结构
- 6关于Spark报错不能连接到Server的解决办法(Failed to connect to master master_hostname:7077)_failed to connect to master h100:7077 org.apache.s
- 7win 11 添加VSCode至右键菜单_open with code win11
- 8全网素材解析接口_静听音乐,全网音乐VIP神器,各个音乐平台都能解析到无损音乐,酷狗音乐和咪咕音乐还可以下载至臻音质...
- 9基于Java的校园快递管理系统_一、运用meclipse软件,编写一个快递包裹的java程序,实现以下功能:(50分)(1)提
- 10利用PYQT5结合YOLOX搭建检测系统_yolov8病虫害识别和pyqt5
基于Vision Transformer的图像去雾算法研究与实现(附源码)_transformer去雾
赞
踩
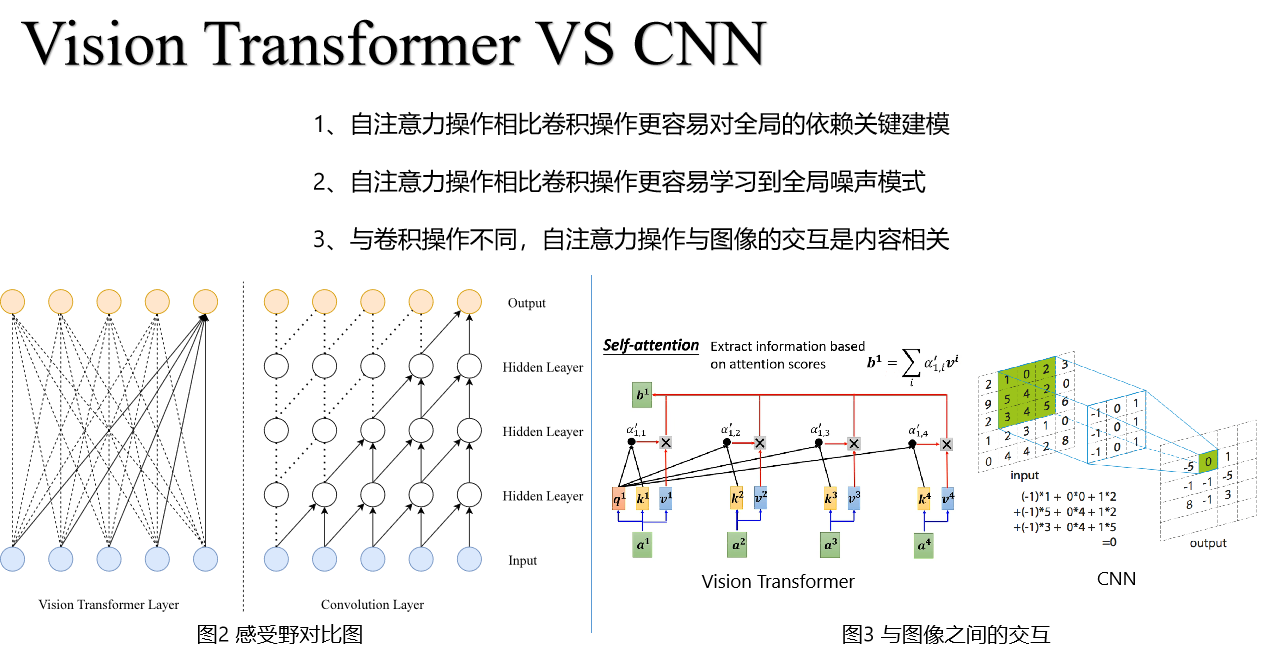
基于Vision Transformer的图像去雾算法研究与实现
0. 服务器性能简单监控
\LOG_USE_CPU_MEMORY\文件夹下的use_memory.py文件可以实时输出CPU使用率以及内存使用率,配合nvidia-smi监控GPU使用率
可以了解服务器性能是否足够;运行时在哪一步使用率突然升高;是否需要释放内存等等
1. 数据集

1.1 NH-HAZE
数据集下载: https://competitions.codalab.org/competitions/22236#participate-get_data
Train:1-40;Test:41-45
我们引入了NH-HAZE,一个非均匀的真实数据集,有成对真实的模糊和相应的无雾图像。因此,非均匀雾霾数据集的存在对于图像去雾场是非常重要的。
它代表第一个真实的图像去模糊数据集与非均匀的模糊和无模糊(地面真实)配对图像
为了补充之前的工作,在本文中,我们介绍了NH-HAZE,这是第一个具有非均匀模糊和无雾(地面真实)图像的真实图像去模糊数据集。
1.2 NTIRE 2019
DENSE-haze是一个真实的数据集,包含密集(均匀)模糊和无烟雾(地面真实)图像
官方地址:
https://data.vision.ee.ethz.ch/cvl/ntire19/#:~:text=Datasets%20and%20reports%20for%20NTIRE%202019%20challenges
https://data.vision.ee.ethz.ch/cvl/ntire19//dense-haze/
另一个下载地址:
https://www.kaggle.com/rajat95gupta/hazing-images-dataset-cvpr-2019?select=GT
Train:1-45;Test:51-55
1.3 I-HAZE
其中包含 35 对有雾的图像和相应的无雾(真实)室内图像
下载地址:https://data.vision.ee.ethz.ch/cvl/ntire18//i-haze/
Train:1-25;Test:31-35
1.4 O_HAZE
O-HAZE是第一个引入的包含模糊和无烟雾(地面真实)图像的真实数据集。它由45个不同的户外场景组成,使用一个专业的雾霾发生器在控制照明下拍摄。而O-HAZE和I-HAZE则由相对较轻、均匀的雾霾组成
下载地址:https://data.vision.ee.ethz.ch/cvl/ntire18//o-haze/
Train:1-35;Test:41-45
我们使用NH-HAZE数据集作为举例数据集,其他数据集除了数据集路径之外,大多数参数设置都一样。
该去雾项目源码下载:
https://download.csdn.net/download/DeepLearning_/87570157
2. 模型运行过程
2.0 模型介绍
在文件夹
/Uformer_ProbSparse/下存放模型代码
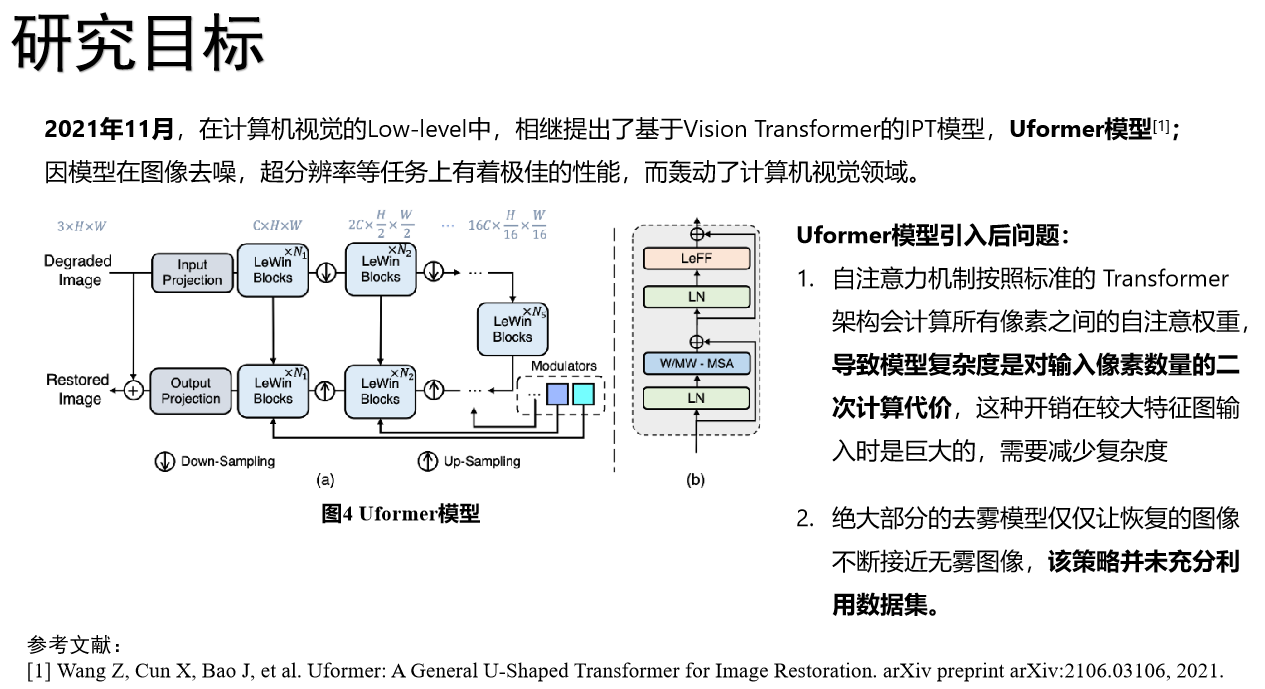

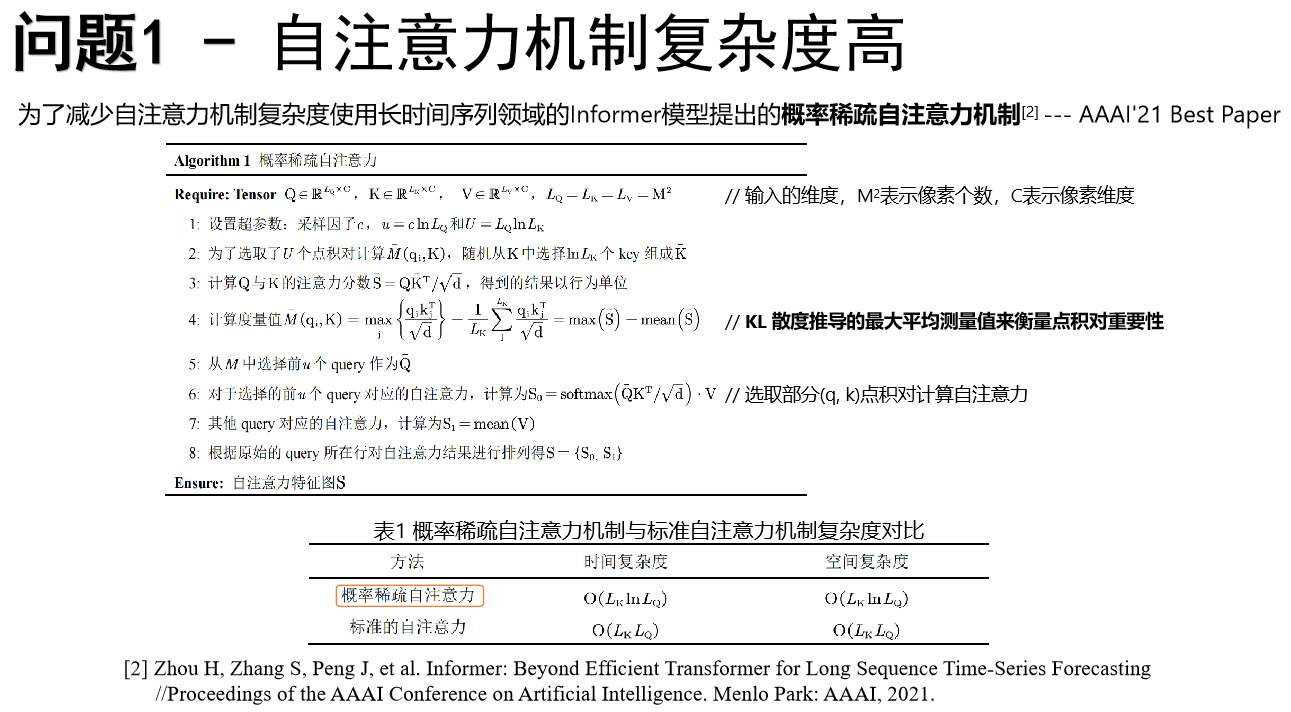
参考代码:https://github.com/ZhendongWang6/Uformer
2.1 预处理数据 — 把训练数据图像切分成大小为256*256的小图
下载数据集存放在:
/home/dell/桌面/TPAMI2022/Dehazing/#dataset/NH_haze/
内含两个文件夹:train test
对训练数据集处理:
python3 generate_patches_SIDD.py --src_dir /home/dell/桌面/TPAMI2022/Dehazing/#dataset/NH_haze/train --tar_dir /home/dell/桌面/2022毕业设计/Datasets/NH-HAZE/train_patches
- 1
2.2 训练代码My_train.py
python3 ./My_train.py --arch Uformer --nepoch 270 --batch_size 32 --env My_Infor_CR --gpu '1' --train_ps 128 --train_dir /media/dell/fd6f6662-7e38-4427-80c6-0d4fb1f0e8b9/work_file/2022毕业设计/Datasets/NH-HAZE/train_patches --val_dir /media/dell/fd6f6662-7e38-4427-80c6-0d4fb1f0e8b9/work_file/2022毕业设计/Datasets/NH-HAZE/test_patches --embed_dim 32 --warmup
- 1
如果要继续对模型进行训练:--pretrain_weights 设置预训练权重路径,我的模型预训练权重在My_best_model文件夹下,以数据集划分不同预训练权重
并添加参数 --resume
训练所有参数设置在option.py文件种,主要的参数含义:
--train_ps训练样本的补丁大小,默认为128,指多大的patches输入到模型中--train_dir--val_dir训练和测试文件夹,文件夹下包含两个文件夹gt和hzay,分别包含无雾图片集和带雾图片集--batch_size设置Batch_size,默认为3--is_ab**是否使用n a对比损失,默认为False(使用)--w_loss_vgg7对比损失使用的权重,默认为1--w_loss_CharbonnierLossCharbonnierLoss 所占权重,默认为1**
2.3 测试代码test_long_GPU.py和预训练权重
预训练权重:
链接:https://pan.baidu.com/s/1a1YPTGSNa0R6I-qiTNir0A
提取码:y422模型预训练权重:将百度网盘中的
Uformer_ProbSparse/My_best_model文件夹放到Uformer_ProbSparse文件夹下,里面包含4大数据集下的权重
python3 ./test_long_GPU.py
- 1
测试流程:
在My_train.py文件中,为了训练速度考虑,我们是在每个patch上进行的测试,但patch上测试结果不等于在整图上测试的结果,因此该文件是对模型在整图上结果进行测试,论文中的结果与该测试结果一致
由于代码的特殊设置,需要让输入的图片的长和宽为 --train_ps 的整数倍,如果不够足,则要进行扩展
主要参数解释:
-
--input_dir设置测试的文件夹,文件夹下包含两个文件夹gt和hzay,分别包含无雾图片集和带雾图片集 -
--train_ps训练样本的补丁大小,默认为128,指多大的patches输入到模型中 -
代码中的: L表示图像需要拓展长和宽为多大
例如:输入是1200 * 1600,patch size = 128时,L = 1664
L需要为128倍数,且要大于输入图像的长和宽,需要根据输入图像进行调整,例如:NH-HAZE数据集上的为L = 1664
3. NH-HAZE数据集上的Losslandscape
主要将最优权重的周围的loss可视化,以探索模型收敛的难易程度以及模型架构的性能
参考文献:Park N, Kim S. How Do Vision Transformers Work?[J]. arXiv preprint arXiv:2202.06709, 2022.
3.1 基于CNN模型(FFA-Net)的Loss landscape
预训练权重:
链接:https://pan.baidu.com/s/1a1YPTGSNa0R6I-qiTNir0A
提取码:y422模型预训练权重:将百度网盘中的
FFA_how-do-vits-work-transformer文件夹包含的内容放到FFA_how-do-vits-work-transformer文件夹下,里面包含FFA-Net在NH-HAZE数据集下的最优权重,以及该权重下运行的结果
在/FFA_how-do-vits-work-transformer/FFA_pretrain_weight/下存放FFA-Net模型在该数据集下的预训练权重,决定预训练权重的路径代码在/FFA_how-do-vits-work-transformer/FFA_model/option.py
主要代码FFA_losslandscape.py:在最优权重周围随机找121个权重,然后计算这些权重的loss值,得到的loss值保存在/FFA_how-do-vits-work-transformer/checkpoints/logs/FFA_NH/My_NH_ffa_3_19_best.pk/文件夹下用于绘图,得到的Loss landscape如下:

3.2 基于Vision Transformer架构改进后的Loss landscape
预训练权重:
链接:https://pan.baidu.com/s/1a1YPTGSNa0R6I-qiTNir0A
提取码:y422模型预训练权重在2.3节有阐述
将百度网盘中的
how-do-vits-work-transformer文件夹包含的内容放到how-do-vits-work-transformer文件夹下,下面有讲解文件夹内包含的内容
在/Uformer_ProbSparse/My_best_model/下存放改进后模型在各种数据集下的预训练权重,决定预训练权重的路径代码在/how-do-vits-work-transformer/Uformer_Info/option.py中的--pretrain_weights设置对应数据集上最优的参数权重路径
主要代码My_losslandscape.py:在最优权重周围随机找121个权重,然后计算这些权重的loss值,得到的loss值保存在/how-do-vits-work-transformer/checkpoints/logs/NH/Uformer_Informer/文件夹下用于绘图,得到的Loss landscape如下:
在实践过程中,通常运行
My_losslandscape.py代码就可以直接得到下图但在我运行过程中,因为服务器断电,只能继续训练,因此
\how-do-vits-work-transformer\checkpoints\logs\NH\Uformer_Informer\下的middle_result.txt和NH_Uformer_Informer_x1_losslandscape.csv是两次运行文件中间结构,而losslandscape.ipynb中融合了两次运行结果得到该图

Park N, Kim S. How Do Vision Transformers Work?[J]. arXiv preprint arXiv:2202.06709, 2022.提到:损失景观越平坦,性能和泛化效果越好
可以发现:我们基于Vision Transformer架构改进后的模型和FFA-Net模型在最优参数时的Loss landscape,能够反应出我们的模型收敛效果比较好这与训练过程一致:我们的模型训练270个epoch就会收敛,而FFA-Net则需要40000个epoch
4. 实验结果
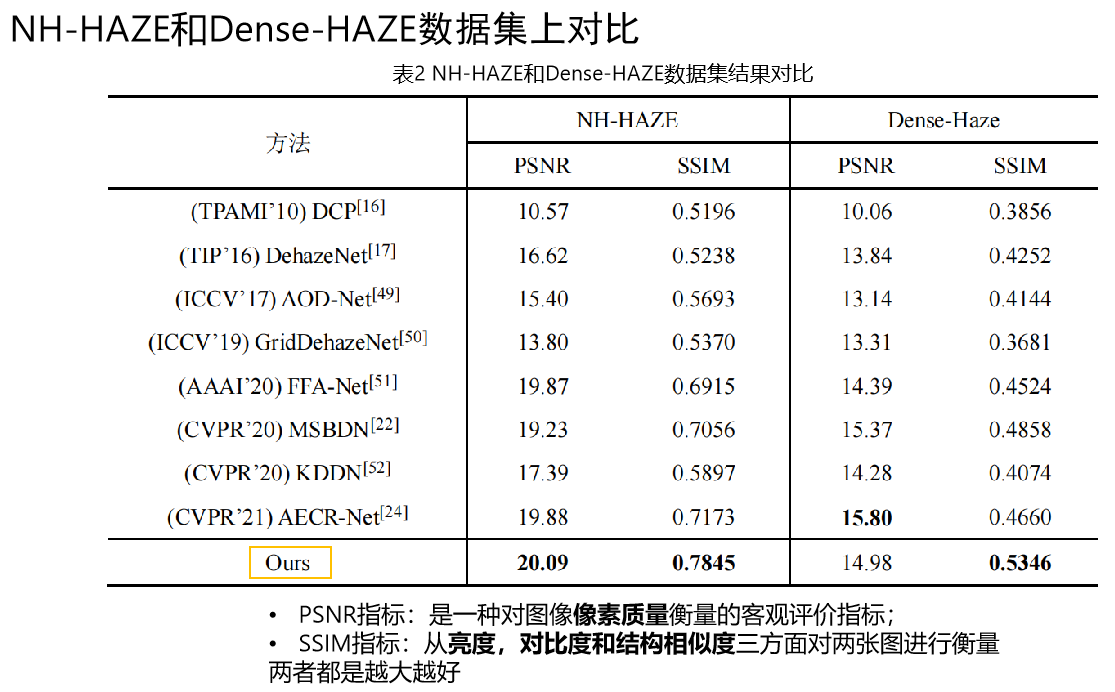

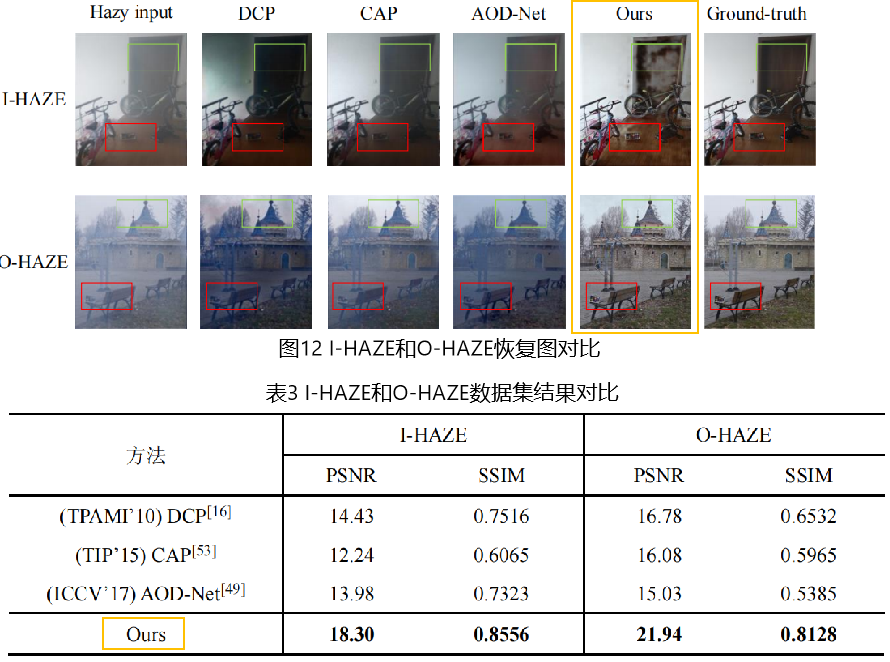
根据恢复图的结果,我们发现在部分图上的效果并不是特别优异
**可以很好的反应Vision Transformer的劣势:该架构虽然全局建模能力强,但局部建模能力没有CNN强,因此当输入某物体占大部分空间时,恢复结果容易受到其影响;因此可以在之后改进中使用CNN和Transformer组合模型,共同对全局和局部进行建模。
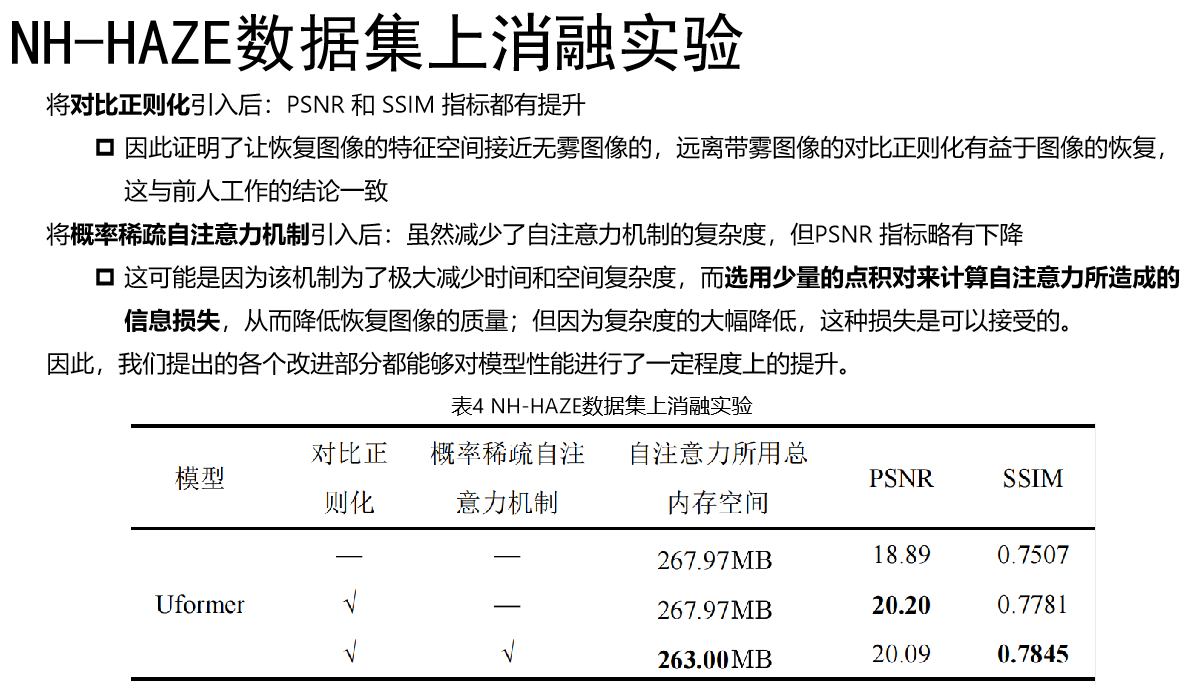
5. 消融实验
6. 总结展望



