
- 14.1 SciPy库介绍及导入_scipy.intergrate怎么导入
- 2关系抽取全面总结:五大类实体关系三元组抽范式模型总结
- 3SpringCloudAlibaba 2021.0.1 - Java/Kotlin 项目完整搭建(Nacos + OpenFeign + Getway + Sentinel)_springcloudalibaba项目搭建
- 4PyTorch QAT(量化感知训练)实践——基础篇
- 5用反馈的观点看带源极负反馈的共源级_带源极负反馈的cs放大器增益
- 6SpringBoot项目application配置文件数据库密码上传git暴露问题解决方案
- 7seq2seq (中英对照翻译)Attention_基于tensorflow框架的seq2seq中英机器翻译模型云盘下载
- 8python自动回复机器人的条件和限制_一个自动回复FAQ问题的聊天机器人
- 9文件服务器不能识别的标点符号,语音识别标点符号
- 10AI说,它可以把你变成个游戏 | 3D人体模型 · CVPR
Grad-CAM简介_gradcam
赞
踩
论文名称:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
论文下载地址:https://arxiv.org/abs/1610.02391
推荐代码(Pytorch):https://github.com/jacobgil/pytorch-grad-cam
bilibili视频讲解:https://b23.tv/1kccjmb
0 前言
对于常用的深度学习网络(例如CNN),普遍认为是个黑盒可解释性并不强(至少现在是这么认为的),它为什么会这么预测,它关注的点在哪里,我们并不知道。很多科研人员想方设法地去探究其内在的联系,也有很多相关的论文。今天本文简单聊一聊Grad-CAM,这并不是一篇新的文章,但很有参考意义。通过Grad-CAM我们能够绘制出如下的热力图(对应给定类别,网络到底关注哪些区域)。Grad-CAM(Gradient-weighted Class Activation Mapping)是CAM(Class Activation Mapping)的升级版(论文3.1节中给出了详细的证明),Grad-CAM相比与CAM更具一般性。CAM比较致命的问题是需要修改网络结构并且重新训练,而Grad-CAM完美避开了这些问题。本文不对CAM进行讲解,有兴趣的小伙伴自行了解。

刚刚提到Grad-CAM能够帮我们分析网络对于某个类别的关注区域,那么我们通过网络关注的区域能够反过来分析网络是否学习到正确的特征或者信息。在论文6.3章节中举了个非常有意思的例子,作者训练了一个二分类网络,Nurse和Doctor。如下图所示,第一列是预测时输入的原图,第二列是Biased model(具有偏见的模型)通过Grad-CAM绘制的热力图。第三列是Unbiased model(不具偏见的模型)通过Grad-CAM绘制的热力图。通过对比发现,Biased model对于Nurse(护士)这个类别关注的是人的性别,可能模型认为Nurse都是女性,很明显这是带有偏见的。比如第二行第二列这个图,明明是个女Doctor(医生),但Biased model却认为她是Nurse(因为模型关注到这是个女性)。而Unbiased model关注的是Nurse和Doctor使用的工作器具以及服装,明显这更合理。

1 Grad-CAM介绍以及实验
1.1 理论介绍
作者的想法还是比较简单的,参见下图。这里我们简单看下Image Classification任务,首先网络进行正向传播,得到特征层
A
A
A(一般指的是最后一个卷积层的输出)和网络预测值
y
y
y(注意,这里指的是softmax激活之前的数值)。假设我们想看下网络针对Tiger Cat这个类别的感兴趣区域,假设网络针对Tiger Cat类别的预测值为
y
c
y^c
yc。接着对
y
c
y^c
yc进行反向传播,能够得到反传回特征层
A
A
A的梯度信息
A
ˊ
\acute{A}
Aˊ。通过计算得到针对特征层
A
A
A每个通道的重要程度,然后进行加权求和通过
R
e
L
U
ReLU
ReLU就行了,最终得到的结果即是Grad-CAM。
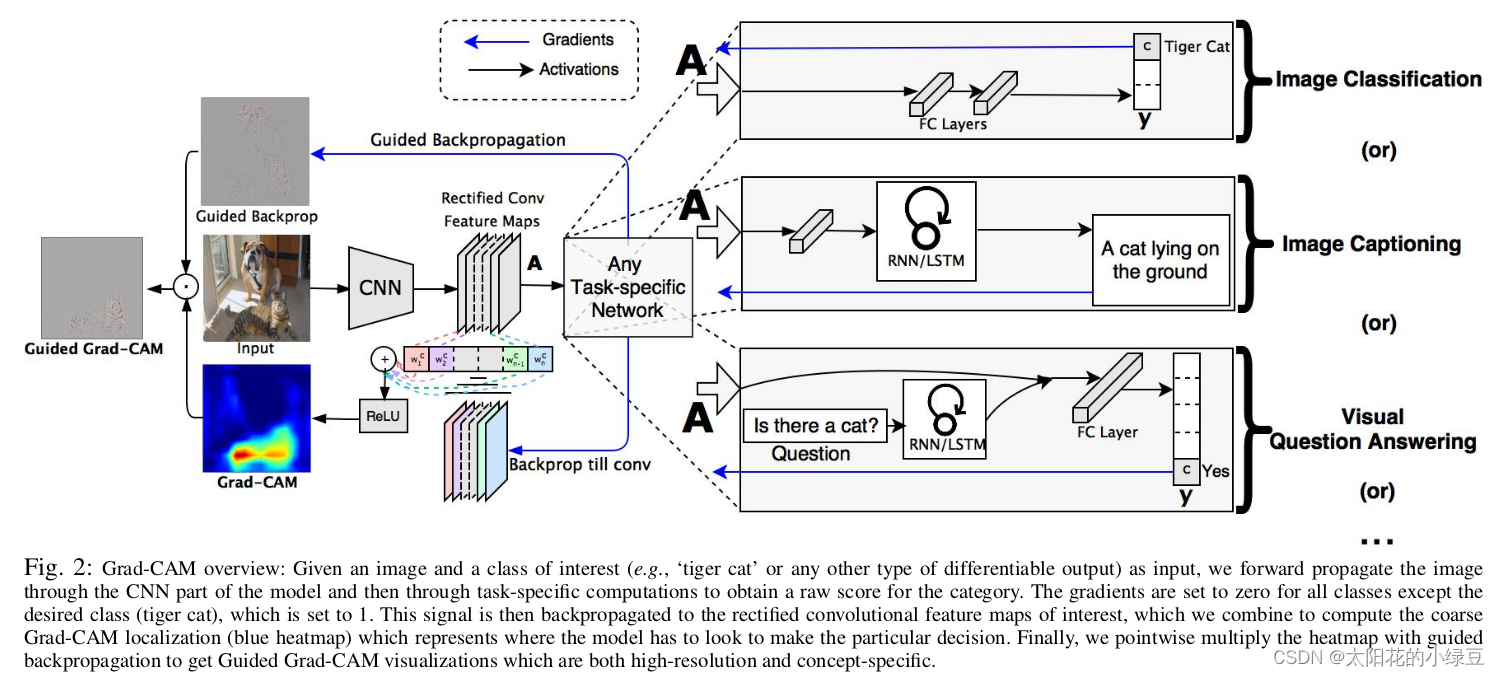
至于为什么要这么做,我这里讲下我个人的观点(若有不对请指出)。首先得到的特征层 A A A是网络对原图进行特征提取得到的结果,越往后的特征层抽象程度越高,语义信息越丰富,而且利用CNN抽取得到的特征图是能够保留空间信息的(Transformer同样)。所以Grad-CAM在CNN中一般 A A A都指的是最后一个卷积层的输出(参考下图实验,越往后的特征层效果越好)。当然特征层 A A A包含了所有我们感兴趣目标的语义信息,但具体哪些语义信息对应哪个类别我们并不清楚。接着通过对类别 c c c的预测值 y c y^c yc进行反向传播,得到反传回特征层 A A A的梯度信息 A ˊ \acute{A} Aˊ,那么 A ˊ \acute{A} Aˊ就是 y c y^c yc对 A A A求得的偏导,换句话说, A ˊ \acute{A} Aˊ代表 A A A中每个元素对 y c y^c yc的贡献,贡献越大网络就认为越重要。然后对 A ˊ \acute{A} Aˊ在 w , h w, h w,h上求均值就能得到针对 A A A每个通道的重要程度(这里是对于类别 c c c而言的)。最后进行简单的加权求和在通过 R e L U ReLU ReLU就能得到文中所说的Grad-CAM。

关于Grad-CAM总结下来就是下面这个公式:
L
G
r
a
d
−
C
A
M
c
=
R
e
L
U
(
∑
k
α
k
c
A
k
)
(
1
)
L_{\rm Grad-CAM}^c=ReLU(\sum_{k}\alpha _k^cA^k) \quad \quad (1)
LGrad−CAMc=ReLU(k∑αkcAk)(1)
其中:
- A A A代表某个特征层,在论文中一般指的是最后一个卷积层输出的特征层
- k k k代表特征层 A A A中第k个通道(channel)
- c c c代表类别 c c c
- A k A^k Ak代表特征层A中通道k的数据
- α k c \alpha_k^c αkc代表针对 A k A^k Ak的权重
关于
α
k
c
\alpha_k^c
αkc的计算公式如下:
α
k
c
=
1
Z
∑
i
∑
j
∂
y
c
∂
A
i
j
k
(
2
)
\alpha_k^c = \frac{1}{Z}\sum_{i}\sum_{j} \frac{\partial y^c}{\partial A_{ij}^k} \quad \quad (2)
αkc=Z1i∑j∑∂Aijk∂yc(2)
其中:
- y c y^c yc代表网络针对类别 c c c预测的分数(score),注意这里没有通过softmax激活
- A i j k A_{ij}^k Aijk代表特征层 A A A在通道 k k k中,坐标为 i j ij ij位置处的数据
- Z Z Z等于特征层的宽度 × \times ×高度
通过计算公式(2)可知
α
k
c
\alpha_k^c
αkc就是通过预测类别
c
c
c的预测分数
y
c
y^c
yc进行反向传播,然后利用反传到特征层
A
A
A上的梯度信息计算特征层
A
A
A每个通道
k
k
k的重要程度。接着通过
α
\alpha
α对特征层
A
A
A每个通道的数据进行加权求和,最后通过
R
e
L
U
ReLU
ReLU激活函数得到Grad-CAM(论文中说使用ReLU是为了过滤掉Negative pixles,而Negative pixles很可能是归属于其他类别的pixles)。当然一般还要通过一些后处理,插值等方法与原图叠加得到最终的可视化结果。
光说公式没意思,这里举个例子,下图中CNN Extractor代表CNN特征提取器,GAP代表Global Average Pooling,FC代表全连接层:

假设网络正向传播得到的特征层
A
A
A如图所示(这里为了方便只画了两个channel,数据都是随便写的不必深究),针对类别Cat的预测值进行反向传播得到针对特征层
A
A
A的梯度信息
A
ˊ
\acute{A}
Aˊ(关于梯度是如何计算的,可以参考本文1.2和1.3的内容),接着利用上述提到的公式(2)计算针对特征层
A
A
A每个通道的权重,就是求
A
ˊ
\acute{A}
Aˊ每个通道的均值。
α
k
c
=
1
Z
∑
i
∑
j
∂
y
c
∂
A
i
j
k
(
2
)
\alpha_k^c = \frac{1}{Z}\sum_{i}\sum_{j} \frac{\partial y^c}{\partial A_{ij}^k} \quad \quad (2)
αkc=Z1i∑j∑∂Aijk∂yc(2)
那么有:
α
C
a
t
=
(
α
1
C
a
t
α
2
C
a
t
)
=
(
1
3
−
2
3
)
\alpha^{\rm Cat} =
然后我们再带入公式(1):
L
G
r
a
d
−
C
A
M
c
=
R
e
L
U
(
∑
k
α
k
c
A
k
)
(
1
)
L_{\rm Grad-CAM}^c=ReLU(\sum_{k}\alpha _k^cA^k) \quad \quad (1)
LGrad−CAMc=ReLU(k∑αkcAk)(1)
得到对应类别Cat的Grad-CAM:
L
G
r
a
d
−
C
A
M
C
a
t
=
R
e
L
U
(
1
3
⋅
(
1
0
2
3
5
0
1
1
1
)
+
(
−
2
3
)
⋅
(
0
1
0
3
1
0
1
0
1
)
)
=
R
e
L
U
(
(
1
3
−
2
3
2
3
−
1
1
0
−
1
3
1
3
−
1
3
)
)
=
(
1
3
0
2
3
0
1
0
0
1
3
0
)
L_{\rm Grad-CAM}^{\rm Cat} = ReLU(\frac{1}{3} \cdot
1.2 梯度计算示例
上面在介绍计算Grad-CAM时,其实主要是计算正向传播得到的特征层 A A A,和反向传播得到的 A ˊ \acute{A} Aˊ,得到特征层 A A A很简单,大家也经常会提取某个特征层进行分析或者特征融合等等。但获取 A ˊ \acute{A} Aˊ会相对麻烦点,计算倒不是难点因为常用的深度学习框架都会自动帮我们计算,只是很少有人会使用到反传的梯度信息。那 A ˊ \acute{A} Aˊ究竟要怎么去计算,如果大家有兴趣的话可以看下下面的例子,不感兴趣的话可以直接跳过。
下面构建了一个非常简单的神经网络,主要结构就是一个卷积层 + 一个全连接层,通过这个简单的例子来演示如何计算反向传播过程中某个特征层的梯度。

根据上图,可得output第一个元素的计算公式如下:
y
1
=
f
f
c
(
f
c
o
n
v
2
d
(
X
,
W
1
)
,
W
2
1
)
y_1 = f_{fc}(f_{conv2d}(X, W_1), W_2^1)
y1=ffc(fconv2d(X,W1),W21)
其中,
X
X
X代表输入(input),
f
c
o
n
v
2
d
f_{conv2d}
fconv2d表示卷积层的计算,
f
f
c
f_{fc}
ffc表示全连接层的计算,
W
1
W_1
W1代表卷积层对应的权重(为了方便,这里都不考虑偏执bias),
W
2
1
W_2^1
W21代表全连接层中第一个节点对应的权重。
这里先令
f
c
o
n
v
2
d
(
X
,
W
1
)
f_{conv2d}(X, W_1)
fconv2d(X,W1)即卷积层输出的结果为
O
=
(
O
11
,
O
12
,
O
21
,
O
22
)
T
O=(O_{11}, O_{12}, O_{21}, O_{22})^T
O=(O11,O12,O21,O22)T(为了方便后续计算,这里直接展平写成向量形式)分别对应图中的
(
4
,
7
,
5
,
6
)
T
(4, 7, 5, 6)^T
(4,7,5,6)T,注意这里的
O
O
O并不是标量,是向量,那么
y
1
y_1
y1的计算公式为:
y
1
=
f
f
c
(
O
,
W
2
1
)
=
O
11
⋅
W
2
11
+
O
12
⋅
W
2
12
+
O
21
⋅
W
2
13
+
O
22
⋅
W
2
14
y_1 = f_{fc}(O, W_2^1) = O_{11} \cdot W_2^{11} + O_{12} \cdot W_2^{12} + O_{21} \cdot W_2^{13} + O_{22} \cdot W_2^{14}
y1=ffc(O,W21)=O11⋅W211+O12⋅W212+O21⋅W213+O22⋅W214
接着对
O
O
O求偏导:
∂
y
1
∂
O
=
∂
y
1
∂
(
O
11
,
O
12
,
O
21
,
O
22
)
T
=
(
W
2
11
,
W
2
12
,
W
2
13
,
W
2
14
)
T
=
(
0
,
1
,
0
,
1
)
T
\frac{\partial y_1}{\partial O}=\frac{\partial y_1}{\partial (O_{11}, O_{12}, O_{21}, O_{22})^T}=(W_2^{11}, W_2^{12}, W_2^{13}, W_2^{14})^T=(0, 1, 0, 1)^T
∂O∂y1=∂(O11,O12,O21,O22)T∂y1=(W211,W212,W213,W214)T=(0,1,0,1)T
将
∂
y
1
∂
O
\frac{\partial y_1}{\partial O}
∂O∂y1得到的结果进行reshape一下得到(后面有使用Pytorch进行的实验,结果是一致的):
(
0
1
0
1
)
看官请留步,后面是选看内容,不想看的可以直接跳到Pytorch实验部分
如果想进一步求
y
1
y_1
y1对输入
X
X
X的偏导,即
∂
y
1
∂
X
\frac{\partial y_1}{\partial X}
∂X∂y1。
X
→
O
→
y
1
X\to O\to y_1
X→O→y1,这里需要稍微注意下,
y
1
y_1
y1是标量,
O
O
O和
X
X
X是向量(为了方便理解,这里将矩阵展平成向量)。根据链式法则以及雅克比矩阵的传递性得(参考的https://github.com/soloice/Matrix_Derivatives内容):
∂
Y
∂
X
=
∂
Y
∂
O
⋅
∂
O
∂
X
\frac{\partial Y}{\partial X}=\frac{\partial Y}{\partial O} \cdot \frac{\partial O}{\partial X}
∂X∂Y=∂O∂Y⋅∂X∂O
再根据
Y
Y
Y(向量)退化成标量时雅克比矩阵和函数导数的关系有:
∂
Y
∂
X
=
∂
y
1
∂
X
T
,
∂
Y
∂
O
=
∂
y
1
∂
O
T
\frac{\partial Y}{\partial X}=\frac{\partial y_1}{\partial X^T}, \space \space \space \frac{\partial Y}{\partial O}=\frac{\partial y_1}{\partial O^T}
∂X∂Y=∂XT∂y1, ∂O∂Y=∂OT∂y1
再带入上式得(此公式是把导数视为行向量):
∂
y
1
∂
X
T
=
∂
y
1
∂
O
T
⋅
∂
O
∂
X
\frac{\partial y_1}{\partial X^T}=\frac{\partial y_1}{\partial O^T} \cdot \frac{\partial O}{\partial X}
∂XT∂y1=∂OT∂y1⋅∂X∂O
前面已经计算出了
∂
y
1
∂
O
\frac{\partial y_1}{\partial O}
∂O∂y1,那么
∂
y
1
∂
O
T
\frac{\partial y_1}{\partial O^T}
∂OT∂y1转置下即可。接下来就是要求解
∂
O
∂
X
\frac{\partial O}{\partial X}
∂X∂O:
∂
O
∂
X
=
∂
(
O
11
,
O
12
,
O
21
,
O
22
)
T
∂
(
X
11
,
X
12
,
X
13
,
.
.
.
,
X
31
,
X
32
,
X
33
)
T
\frac{\partial O}{\partial X} = \frac{\partial (O_{11}, O_{12}, O_{21}, O_{22})^T}{\partial (X_{11}, X_{12}, X_{13}, ..., X_{31}, X_{32}, X_{33})^T}
∂X∂O=∂(X11,X12,X13,...,X31,X32,X33)T∂(O11,O12,O21,O22)T
对应的雅克比矩阵(Jacobian matrix)为一个
4
×
9
4 \times 9
4×9大小的矩阵:
(
∂
O
11
∂
X
11
∂
O
11
∂
X
12
∂
O
11
∂
X
13
.
.
.
∂
O
11
∂
X
32
∂
O
11
∂
X
33
∂
O
12
∂
X
11
∂
O
12
∂
X
12
∂
O
12
∂
X
13
.
.
.
∂
O
12
∂
X
32
∂
O
12
∂
X
33
∂
O
21
∂
X
11
∂
O
21
∂
X
12
∂
O
21
∂
X
13
.
.
.
∂
O
21
∂
X
32
∂
O
21
∂
X
33
∂
O
22
∂
X
11
∂
O
22
∂
X
12
∂
O
22
∂
X
13
.
.
.
∂
O
22
∂
X
32
∂
O
22
∂
X
33
)
比如说对于
O
11
O_{11}
O11,是通过
W
1
W_1
W1与
X
X
X左上角的
2
×
2
2\times2
2×2窗口进行加权求和得到的,即:
O
11
=
X
11
⋅
W
1
11
+
X
12
⋅
W
1
12
+
X
21
⋅
W
1
21
+
X
22
⋅
W
1
22
O_{11} = X_{11} \cdot W_1^{11} + X_{12} \cdot W_1^{12} + X_{21} \cdot W_1^{21} + X_{22} \cdot W_1^{22}
O11=X11⋅W111+X12⋅W112+X21⋅W121+X22⋅W122
通过上面公式可得(
O
11
O_{11}
O11 只和
X
11
,
X
12
,
X
21
,
X
22
X_{11},X_{12},X_{21},X_{22}
X11,X12,X21,X22有关,故其他的偏导数都为0):
∂
O
11
∂
X
11
,
∂
O
11
∂
X
12
,
∂
O
11
∂
X
13
,
.
.
.
,
∂
O
11
∂
X
32
,
∂
O
11
∂
X
33
=
W
1
11
,
W
1
12
,
0
,
W
1
21
,
W
1
22
,
0
,
0
,
0
,
0
=
1
,
0
,
0
,
1
,
2
,
0
,
0
,
0
,
0
\frac{\partial O_{11}}{\partial X_{11}}, \frac{\partial O_{11}}{\partial X_{12}}, \frac{\partial O_{11}}{\partial X_{13}}, ..., \frac{\partial O_{11}}{\partial X_{32}}, \frac{\partial O_{11}}{\partial X_{33}}=W_1^{11}, W_1^{12}, 0, W_1^{21}, W_1^{22}, 0, 0, 0, 0 = 1, 0, 0, 1, 2, 0, 0, 0, 0
∂X11∂O11,∂X12∂O11,∂X13∂O11,...,∂X32∂O11,∂X33∂O11=W111,W112,0,W121,W122,0,0,0,0=1,0,0,1,2,0,0,0,0
同理可得:
(
∂
O
11
∂
X
11
∂
O
11
∂
X
12
∂
O
11
∂
X
13
.
.
.
∂
O
11
∂
X
32
∂
O
11
∂
X
33
∂
O
12
∂
X
11
∂
O
12
∂
X
12
∂
O
12
∂
X
13
.
.
.
∂
O
12
∂
X
32
∂
O
12
∂
X
33
∂
O
21
∂
X
11
∂
O
21
∂
X
12
∂
O
21
∂
X
13
.
.
.
∂
O
21
∂
X
32
∂
O
21
∂
X
33
∂
O
22
∂
X
11
∂
O
22
∂
X
12
∂
O
22
∂
X
13
.
.
.
∂
O
22
∂
X
32
∂
O
22
∂
X
33
)
=
(
1
0
0
1
2
0
0
0
0
0
1
0
0
1
2
0
0
0
0
0
0
1
0
0
1
2
0
0
0
0
0
1
0
0
1
2
)
那么:
∂
y
1
∂
X
T
=
∂
y
1
∂
O
T
⋅
∂
O
∂
X
=
(
0
1
0
1
)
(
1
0
0
1
2
0
0
0
0
0
1
0
0
1
2
0
0
0
0
0
0
1
0
0
1
2
0
0
0
0
0
1
0
0
1
2
)
=
(
0
1
0
0
2
2
0
1
2
)
\frac{\partial y_1}{\partial X^T} = \frac{\partial y_1}{\partial O^T} \cdot \frac{\partial O}{\partial X} =
对得到的结果进行下reshape得到(后面有使用Pytorch进行的实验,结果是一致的):
(
0
1
0
0
2
2
0
1
2
)
1.3 Pytorch梯度计算实验
这个实验过程中的网络、权重以及输入的数据是严格按照刚刚讲的示例搭建的。
实验代码如下:
import torch def save_gradient(module, grad_input, grad_output): # print(f"{module.__class__.__name__} input grad:\n{grad_input}\n") print(f"{module.__class__.__name__} output grad:\n{grad_output}\n") def main(): # input tensor x = torch.reshape(torch.as_tensor([[1., 2., 3.], [1., 1., 2.], [2., 1., 2.]], dtype=torch.float32), (1, 1, 3, 3)) x = torch.autograd.Variable(x, requires_grad=True) print(f"input:\n{x}\n") # define model # [kernel_number, kernel_channel, kernel_height, kernel_width] conv_weight = torch.reshape(torch.as_tensor([1, 0, 1, 2], dtype=torch.float32), (1, 1, 2, 2)) conv = torch.nn.Conv2d(1, 1, 2, bias=False) conv.load_state_dict({"weight": conv_weight}) # 注册hook,捕获反向转播过程中流经该模块的梯度信息 handle1 = conv.register_full_backward_hook(save_gradient) # [output_units, input_units] fc_weight = torch.reshape(torch.as_tensor([[0, 1, 0, 1], [1, 0, 1, 1]], dtype=torch.float32), (2, 4)) fc = torch.nn.Linear(4, 2, bias=False) fc.load_state_dict({"weight": fc_weight}) # handle2 = fc.register_full_backward_hook(save_gradient) # forward o1 = conv(x) print(f"feature map o1:\n{o1}\n") flatten = torch.flatten(o1, start_dim=1) o2 = fc(flatten) print(f"feature map o2:\n{o2}\n") # backward y_1 # [batch_size, units] o2[0][0].backward() print(f"input grad: \n{x.grad}\n") # print(f"fc weights grad: \n{fc.weight.grad}\n") # print(f"conv2d weights grad: \n{conv.weight.grad}\n") # release handles handle1.remove() # handle2.remove() if __name__ == '__main__': main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
终端输出结果:
input: tensor([[[[1., 2., 3.], [1., 1., 2.], [2., 1., 2.]]]], requires_grad=True) feature map o1: tensor([[[[4., 7.], [5., 6.]]]], grad_fn=<BackwardHookFunctionBackward>) feature map o2: tensor([[13., 15.]], grad_fn=<MmBackward0>) Conv2d output grad: (tensor([[[[0., 1.], [0., 1.]]]]),) input grad: tensor([[[[0., 1., 0.], [0., 2., 2.], [0., 1., 2.]]]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
利用pytorch计算的有关梯度信息和上面我们自己手动推的结果进行对比,主要是Conv2d output grad和input grad,可以发现结果是一样的。
2 使用Pytorch绘制热力图
这个项目是我从https://github.com/jacobgil/pytorch-grad-cam仓库中提取得到的(保留了Grad-CAM相关的代码)。
这里主要简单看下main_cnn.py文件。在该脚本中,直接从TorchVision官方库中调用官方在Imagenet数据上预训练好的模型。这里默认使用的是MobileNet V3 Large模型,使用其他卷积神经网络也是一样的,可参考注释部分的创建模型代码。如果要使用Vision Transformer或者Swin Transformer模型需要使用main_vit.py或者main_swin.py脚本,这里不去讲。创建好模型并且载入预训练权重后,需要指定捕获哪一个特征层
A
A
A,即代码中target_layers,一般默认都是捕获最后一个卷积层的输出。接着还要指定我们感兴趣的类别id,即代码中的target_category,注意这里是直接使用官方在Imagenet数据上预训练好的模型,所以这里的类别id指的是Imagenet数据中1000个类别的id(代码中id默认从0开始),比如说对于tabby, tabby cat这个类别,它对应的target_category = 281,具体可参考我项目中imagenet1k_classes.txt文件,对应类别的行号减1即对应类别id(比如tabby, tabby cat这个类别是在第282行,故id为281)。
import os import numpy as np import torch from PIL import Image import matplotlib.pyplot as plt from torchvision import models from torchvision import transforms from utils import GradCAM, show_cam_on_image def main(): model = models.mobilenet_v3_large(pretrained=True) target_layers = [model.features[-1]] # model = models.vgg16(pretrained=True) # target_layers = [model.features] # model = models.resnet34(pretrained=True) # target_layers = [model.layer4] # model = models.regnet_y_800mf(pretrained=True) # target_layers = [model.trunk_output] # model = models.efficientnet_b0(pretrained=True) # target_layers = [model.features] data_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) # load image img_path = "both.png" assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path) img = Image.open(img_path).convert('RGB') img = np.array(img, dtype=np.uint8) # [N, C, H, W] img_tensor = data_transform(img) # expand batch dimension input_tensor = torch.unsqueeze(img_tensor, dim=0) cam = GradCAM(model=model, target_layers=target_layers, use_cuda=False) target_category = 281 # tabby, tabby cat # target_category = 254 # pug, pug-dog grayscale_cam = cam(input_tensor=input_tensor, target_category=target_category) grayscale_cam = grayscale_cam[0, :] visualization = show_cam_on_image(img.astype(dtype=np.float32) / 255., grayscale_cam, use_rgb=True) plt.imshow(visualization) plt.show() if __name__ == '__main__': main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
运行结果如下:

当然,这里我只是以图像分类任务为例,对于目标检测、语义分割等任务也都适用,详情可参考原项目。

