
- 1python字典(dict)_python dict取值
- 2Ext文本输入框:Ext.form.TextField属性汇总
- 3如何安装Ubuntu20.04(详细图文教程_ubuntu20.04安装教程
- 4鸿蒙OpenHarmony技术:【设备互信认证】
- 5深度学习项目构建(持续更新)_深度学习 项目 结构
- 6【git】下载gitee项目到本地_git下载项目到本地
- 7NLP模型的tokenize方法中return_tensors参数_return_tensors="pt
- 8Python(1)遍历文件目录并简单筛选文件_python hdfs 递归读取目录文件并且过滤success文件
- 9物联网大学生创新创业项目_物联网创业项目
- 10如何在Linux运行RStudio Server并实现Web浏览器远程访问_如何登录rstudioserver?
bert知识扩充
赞
踩
一、BERT-wwm
wwm(Whole Word Masking),全词Mask就是对整个词都通过Mask进行掩码,包含更多信息的是词,相比于Bert的改进是用Mask标签替换一个完整的词而不是子词,中文和英文不同,英文中最小的Token就是一个单词,而中文中最小的Token却是字,词是由一个或多个字组成,且每个词之间没有明显的分隔,

论文下载链接:https://arxiv.org/pdf/1906.08101.pdf
二、BERT-wwm-ext
它是BERT-wwm的一个升级版,相比于BERT-wwm的改进是增加了训练数据集同时也增加了训练步数
已训练好中文模型下载:https://github.com/brightmart/albert_zh
BERT-wwm-ext主要是有两点改进:
1)预训练数据集做了增加,次数达到5.4B;
2)训练步数增大,训练第一阶段1M步,训练第二阶段400K步。
中文模型下载
由于目前只包含base模型,故我们不在模型简称中标注base字样。
BERT-base模型:12-layer, 768-hidden, 12-heads, 110M parameters
三、RoBERTa
相比于Bert的改进:更多的数据、更多的训练步数、更大的批次(用八千为批量数),用字节进行编码以解决未发现词的问题。
对Adam算法中的两处进行了调整:
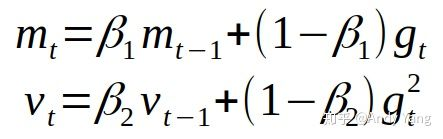
Adam 中二阶矩估计时的 β_2,一般对于梯度稀疏之问题,如 NLP 与 CV,建议将此值设大,接近 1,因此通常默认设置为 0.999,而此处却设 0.98。
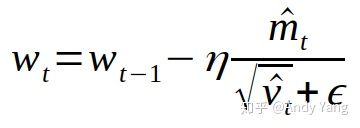
调节最早只用来防止除零情况发生的ε,通过对ε的调节能够提高模型的稳定性,有时能够提升模型性能。
对于Mask不再使用静态的Mask而是动态的Mask,对于同一句话,在不同的批次中参与训练其Mask的位置是不同的。(这样做相当于对数据进行了简单的增强)
取消了Next Sentence这一预训练任务,输入的不再是通过[SEP]隔开的句子对,而是一个句子段,对于短句会进行拼接,但是最大长度仍是512(这样做是因为更长的语境对模型更有利,能够使模型获得更长的上下文),同时输入的句子段不跨文档(是因为引入不同文档的语境会给MLM带来噪音)。
论文下载地址:https://arxiv.org/pdf/1907.11692.pdf
已训练好中文模型下载:https://github.com/brightmart/roberta_zh
四、SpanBERT
作者提出一种分词级别的预训练方法。它不再是对单个Token进行掩码,而是随机对邻接分词添加掩码。对于掩码词的选取,作者首先从几何分布中采样得到分词的长度,该几何分布是偏态分布,偏向于较短的分词,分词的最大长度只允许为10(超过10的不是截取而是舍弃)。之后随机(均匀分布)选择分词的起点。对选取的这一段词进行Mask,Mask的比例和Bert相同,15%、80%、10%、10%。
对于损失函数也进行了改进,去除了Next Sentence,
具体做法是,在训练时取 Span 前后边界的两个词,值得指出,这两个词不在 Span 内,然后用这两个词向量加上 Span 中被遮盖掉词的位置向量,来预测原词。

详细做法是将词向量和位置向量拼接起来,作者使用一个两层的前馈神经网络作为表示函数,该网络使用 GeLu 激活函数,并使用层正则化:

作者使用向量表示yi来预测xi,并和 MLM 一样使用交叉熵作为损失函数,就是 SBO 目标的损失,之后将这个损失和 BERT 的 Mased Language Model(MLM)的损失加起来,一起用于训练模型
论文下载地址:https://arxiv.org/pdf/1907.10529.pdf
五、ERNIE2
它的主要创新是ERNIE2采用Multi-task进行预训练,训练任务有词级别的、结构级别、语义级别三类。同时多任务是轮番学习,学习完一个任务再学习下一个任务,不同任务使用相应损失函数,类似于教课,不同课应该分开上,若多任务同时学习会学的较为混乱,多个任务同时学习最好是任务之间存在关系,能够相互指导。
论文下载地址:https://arxiv.org/pdf/1907.12412.pdf
fp16和fp32
fp16是指采用2字节(16位)进行编码存储的一种数据类型;同理fp32是指采用4字节(32位);
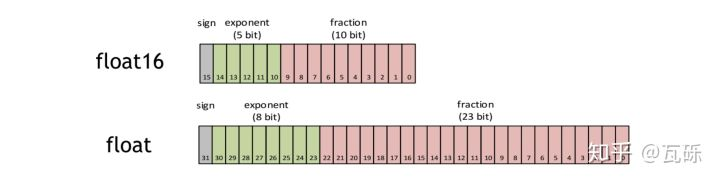
如上图,fp16第一位表示+-符号,接着5位表示指数,最后10位表示分数

fp16和fp32相比对训练的优化:
1.内存占用减少:很明显,应用fp16内存占用比原来更小,可以设置更大的batch_size
2.加速计算:加速计算只在最近的一些新gpu中,有论文指出fp16训练速度可以是fp32的2-8倍
由于fp16的值区间比fp32的值区间小很多,所以在计算过程中很容易出现上溢出(Overflow,>65504 )和下溢出(Underflow,<6x10^-8 )的错误,溢出之后就会出现“Nan”的问题
解决办法:
1.混合精度加速:简单的讲就是使用fp16进行乘法和存储,只使用fp32进行加法操作,避免累加误差;
2.损失放大化:
反向传播前,将损失变化(dLoss)手动增大 倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出;
反向传播后,将权重梯度缩 倍,恢复正常值。
Reference
https://blog.csdn.net/weixin_41797870/article/details/105274928

