
nlp 特征工程
Now that we processed the data and removed unwanted noise from our text in the last story, it’s time to process it and get the desired output from it. Machine Learning algorithms learn from a pre-defined set of features from the training data to produce output for the test data. But the main problem in working with language processing is that machine learning algorithms cannot work on the raw text directly. So, we need some feature extraction techniques to convert text into a matrix(or vector) of features.
既然我们已经处理了数据并在上一个故事中消除了文本中的有害噪声,那么该是时候对其进行处理并从中获得所需的输出了。 机器学习算法从训练数据的一组预定义功能中学习,以生成测试数据的输出。 但是使用语言处理的主要问题是机器学习算法无法直接在原始文本上运行。 因此,我们需要一些特征提取技术来将文本转换为特征矩阵(或向量)。
This article will take you through different methods of transforming text into features and using them in both machine and deep learning. Feature extraction is mainly focussed on two methods:
本文将带您了解将文本转换为功能并在机器学习和深度学习中使用它们的不同方法。 特征提取主要集中在两种方法上:
- Bag of words & TF-IDF 文字袋和TF-IDF
- Word embedding 词嵌入
口碑(BoW) (Bag-of-Words (BoW))
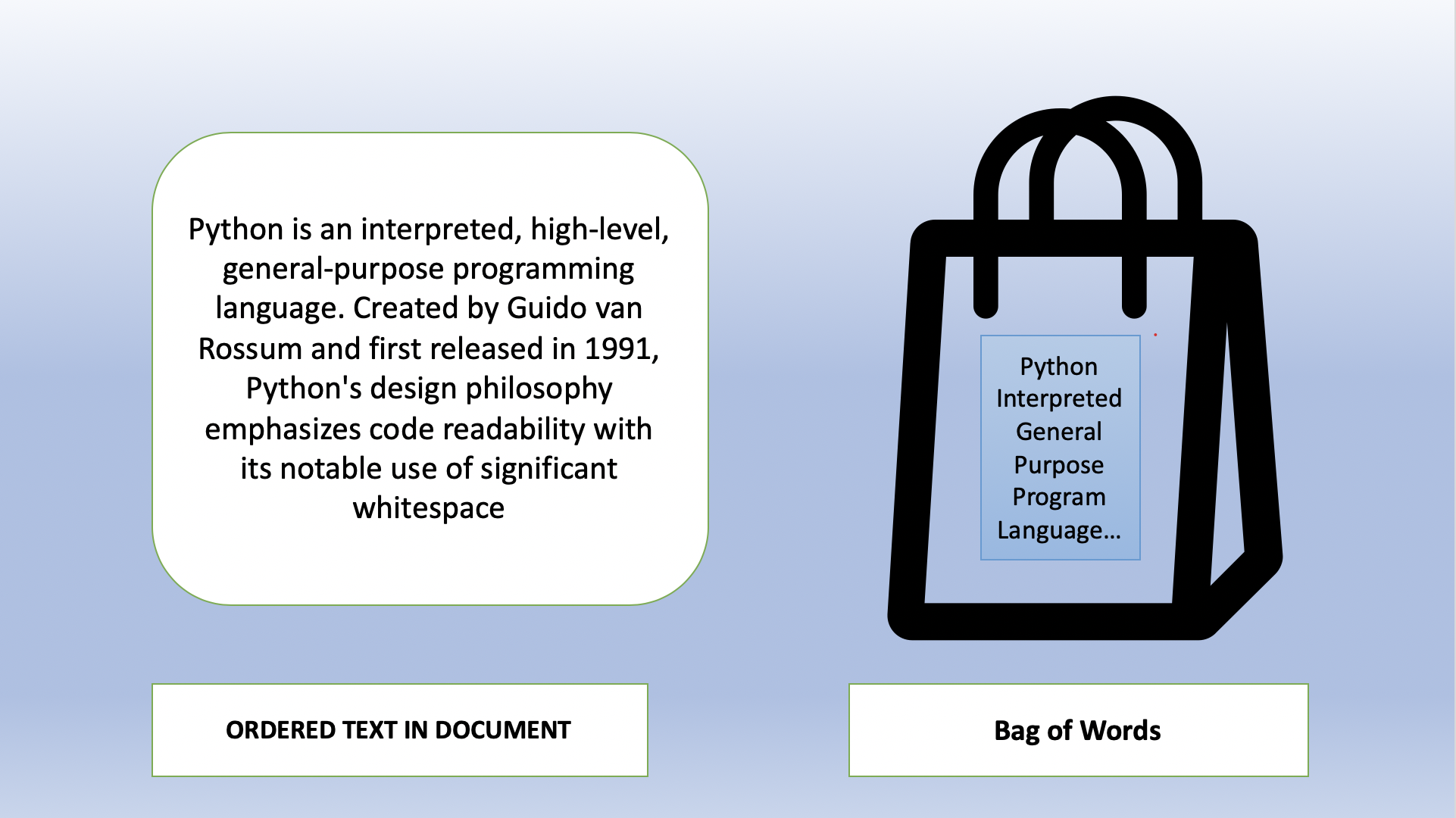
BoW is one of the simplest ways to convert tokens into features. The BoW model is used in document classification, where each word is used as a feature for training the classifier.
BoW是将令牌转换为功能的最简单方法之一。 BoW模型用于文档分类,其中每个单词都用作训练分类器的功能。
BoW creates the matrix of features by assigning the frequency of each feature in rows. BoW creates columns of features and fills row values by their frequency sentence by sentence. Here, I took two sentences, removed some noise from them and preprocessed it as discussed it here, and applied BoW that created a matrix something like this.
BoW通过在行中分配每个特征的频率来创建特征矩阵。 BoW创建要素列,并按其频率逐句填充行值。 在这里,我拿了两个句子,从其中删除了一些噪音,并按照此处的讨论对其进行了预处理,然后应用BoW创建了类似这样的矩阵。

Here shows a sample code of Bag-of-Words with python. Python let us write code simply with Scikit-learn, which is one of the most popular machines learning library and provides APIs for feature extraction. max_features arguments allow us to extract the total number of features we need to train our model.
这里显示了使用Python的“词袋”的示例代码。 Python让我们可以使用Scikit-learn简单地编写代码,Scikit-learn是最受欢迎的机器学习库之一,并提供用于特征提取的API。 max_features参数允许我们提取训练模型所需的特征总数。
# Creating the Bag of Words modelfrom sklearn.feature_extraction.text import CountVectorizercv = CountVectorizer(max_features=3250)X = cv.fit(corpus)A major drawback in using BoW is that the order of occurrence of words in a sentence is lost, as we create a vector of tokens in randomized order. This problem is easily solved by using TF-IDF.
使用BoW的主要缺点是,当我们以随机顺序创建标记向量时,会丢失句子中单词出现的顺序。 使用TF-IDF可以轻松解决此问题。
特遣部队 (TF-IDF)
TF-IDF stands for Term Frequency-Inverse Document Frequency. The BoW might miss some important words due to low frequency, but that’s not the case in TF-IDF. As you can see in the name, TF-IDF is composed of two parts:
TF-IDF代表术语频率-逆文档频率 。 BoW可能会因为频率较低而错过一些重要的单词,但TF-IDF并非如此。 如名称所示,TF-IDF由两部分组成:
Term Frequency: It is a probability of a given word in a document, i.e.
词频 :这是文档中给定单词的概率,即
tf(w) = frequency of word w in doc d / total words in doc d
tf(w) = frequency of word w in doc d / total words in doc d
A different technique for calculating tf is log normalization.
计算tf的另一种技术是对数归一化。
tf(w) = 1 + log(f) , f is frequency of word w in the document
tf(w) = 1 + log(f) , f is frequency of word w in the document
Inverse Document Frequency: It is a measure of how rare a given word is in a document. The less is the frequency of the word, the more the value of IDF. It is given by a formula:
反向文档频率:它是衡量给定单词在文档中有多罕见的度量。 单词的频率越少,IDF的值就越大。 它由一个公式给出:
idf(w) = log (N / f), N is total number of documents & f is the frequency of word w
idf(w) = log (N / f), N is total number of documents & f is the frequency of word w
Lastly, combining both the formula derives the equation for TF-IDF:
最后,将这两个公式结合起来可得出TF-IDF的公式:
tf-idf (w) = tf(w) * idf(w)
tf-idf (w) = tf(w) * idf(w)
sentences = ["Hello! How are you all? This is Deep, an AI enthusiast. AI is a great thing to explore and can make computer smarter."]#import libraryfrom sklearn.feature_extraction.text import TfidfVectorizertf = TfidfVectorizer(max_features=3250, stop_words = 'english')tf.fit(sentences)tf.vocabulary_#Output:{'hello': 6, 'deep': 2, 'ai': 0, 'enthusiast': 3, 'great': 5, 'thing': 9, 'explore': 4, 'make': 7, 'computer': 1, 'smarter': 8}词嵌入 (Word Embedding)
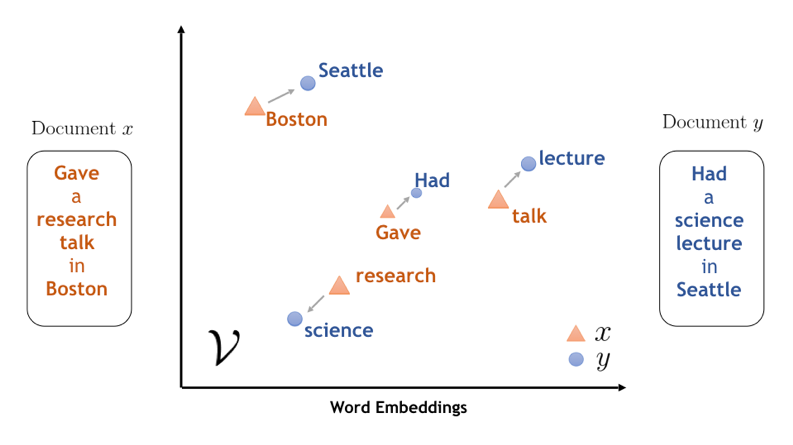
Word embedding is representing a word in a vector space, with similar words have similar vectors. This technique preserves the similarity or the relationship between similar words.
词嵌入是在向量空间中表示一个词, 相似的词具有相似的向量。 该技术保留了相似词之间的相似性或关系。
Word embedding methods learn a real-valued vector representation for a predefined fixed-sized vocabulary from a corpus of text. Two pre-defined models that are commonly used to create word embedding are:
词嵌入方法可从文本语料库中学习预定义固定大小词汇的实值矢量表示。 通常用于创建单词嵌入的两个预定义模型是:
- Word2vec Word2vec
- Glove 手套
Word2Vec (Word2Vec)
Word2Vec is a popular statistical method developed at Google for learning efficiently from the text corpus. It is made of two layers shallow than an actual neural network to recognize text easily. It first constructs a vocabulary from the training corpus and then learns word embedding representations. Two different approaches are used in word2vec technique:
Word2Vec是Google开发的一种流行的统计方法,可以从文本语料库中高效学习。 它由比实际神经网络浅的两层组成,可以轻松识别文本。 它首先从训练语料库构建词汇表,然后学习单词嵌入表示。 word2vec技术中使用了两种不同的方法:
- Continuous Bag-of-Words, or CBOW model: The CBOW model learns the embedding by predicting the current word based on its context. 连续词袋(CBOW)模型:CBOW模型通过根据上下文预测当前单词来学习嵌入。
- Continuous Skip-Gram Model: The continuous skip-gram model learns by predicting the surrounding words given a current word. 连续跳过语法模型:连续跳过语法模型通过预测给定当前单词的周围单词来学习。
Here, we are using Gensim, an API that provides algorithms like word2vec for NLP.
在这里,我们使用的是Gensim,该API提供了针对NLP的word2vec之类的算法。
#pip install gensim, if you haven't installed yet from gensim.test.utils import common_texts, get_tmpfilefrom gensim.models import Word2Vec# Word2Vec modeling cbowmodel = Word2Vec(data, size=100, window=5, min_count=1, workers=4)print("Cosine similarity between 'W1' "+ "and 'W2' - CBOW : ",model1.similarity('W1', 'W2'))sgmodel = = = 100,window = = print("Cosine similarity between 'W1' "+ "and 'W2' - Skip Gram : ",model2.similarity('W1', 'W2'))手套 (Glove)
Global Vector or Glove is an unsupervised algorithm, an extension to the word2vec method for efficiently learning word vectors, developed by Pennington, et al. at Stanford.
Pennington等人开发的“全局向量或手套”是一种无监督算法,是对word2vec方法的扩展,该方法可有效学习词向量。 在斯坦福。
from gensim.scripts.glove2word2vec import glove2word2vecglove_input_file = 'glove.txt'word2vec_output_file = 'word2vec.txt'glove2word2vec(glove_input_file, word2vec_output_file)filename = 'word2vec_output_file'from gensim.models import KeyedVectors# load the Stanford GloVe modelmodel = KeyedVectors.load_word2vec_format(filename, binary=False)# calculate: (king - man) + woman = ?result = model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)print(result)Here, I haven’t gone much into the details of the Glove and Word2vec. I will try to discuss these topics in detail in further articles..
在这里,我对手套和Word2vec的细节并没有做过多介绍。 我将在以后的文章中尝试详细讨论这些主题。
Thank you for reading!
感谢您的阅读!
翻译自: https://medium.com/towards-artificial-intelligence/feature-engineering-with-nlp-23a97e933e8e
nlp 特征工程

