
热门标签
热门文章
- 1springboot+mysql高校教学管理系统-计算机毕业设计源码32780
- 2手写一个RPC框架,我(小白)行,你(大佬)肯定行_手撸一个rpc框架
- 3python-jwt的生成和解析_python createjwt
- 4【位段】位段和结构体的区别
- 5VScode+esp-idf:安信可esp32-cam开发板测试sd卡_esp32cam sd卡
- 6Web SQL 学习笔记_could not prepare statement (1 not an error)
- 7easy connect for Mac 详细安装教程
- 82022-06-04 关于aliyun-java-vod-upload.jar包在maven中引入失败问题
- 9Stable Diffusion 黑白老照片上色修复_controlnet 修复老照片
- 1020 Debian如何配置DNS服务(2)主从服务器
当前位置: article > 正文
【自监督学习】对比学习(Contrastive Learning)介绍
作者:AllinToyou | 2024-05-20 03:39:55
赞
踩
对比学习
1. 前言
1.1. 为什么要进行自监督学习
我们知道,标注数据总是有限的,就算ImageNet已经很大,但是很难更大,那么它的天花板就摆在那,就是有限的数据总量。NLP领域目前的经验应该是:自监督预训练使用的数据量越大,模型越复杂,那么模型能够吸收的知识越多,对下游任务效果来说越好。这可能是自从Bert出现以来,一再被反复证明的真理,如果它不是唯一的真理,那也肯定是最大的真理。图像领域如果技术想要有质的提升,可能也必须得走这条路,就是充分使用越来越大量的无标注数据,使用越来越复杂的模型,采用自监督预训练模式,来从中吸取图像本身的先验知识分布,在下游任务中通过Fine-tuning,来把预训练过程习得的知识,迁移给并提升下游任务的效果。
1.2. 什么是自监督学习
利用代理任务(pretext task)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
1.3. 自监督学习分类
- 生成式的方法(Generative Methods) :这类方法以自编码器为代表,主要关注pixel label的loss。即在自编码器中对数据样本编码成特征再解码重构,这类型的任务难度相对比较高,要求像素级的重构,中间的图像编码必须包含很多细节信息举例来说,这里认为重构的效果比较好则说明模型学到了比较好的特征表达,而重构的效果通过pixel label的loss来衡量。如VAE、GAN。
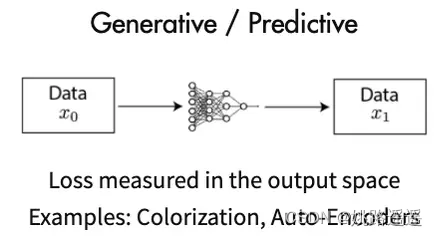
- 对比式的方法(Contrastive Learning):也称判别式的方法,通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。而如何构造相似实例,以及不相似实例,如何构造能够遵循上述指导原则的表示学习模型结构,以及如何防止模型坍塌(Model Collapse),这几个点是其中的关键。如对比学习。
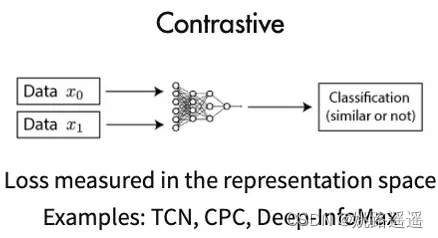
2.对比学习(Contrastive Learning)
2.1. 什么是对比学习
对比学习有的paper中称之为自监督学习,有的paper称之为无监督学习,自监督学习是无监督学习的一种形式,现有的文献中没有正式的对两者进行区分定义,这两种称呼都可以用。



上面有三张图,图1和图2是
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/595934
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

