
热门标签
热门文章
- 1SVN项目迁移到Git,并同步提交记录_svn迁移到git保留记录
- 2[201710][Spring Boot 2 精髓 - 从构建小系统到架构分布式大系统][李家智][著]_spring boot 2 精髓电子书
- 3选择国辰智企智慧园区物流一站式平台,迎接高效、精准、智能的数智未来
- 4网安毕设分享(算法) 基于Django的端口扫描与渗透测试系统(工程源码)_python 漏洞扫描
- 5YOLOv10 正式发布!原理、部署、应用一站式齐全_yolov10出了么
- 6Chainer 使复杂神经网络变的简单
- 7【AI测试】已落地-python文字图像识别PaddleOCR_图像识别paddleocr应用软件测试
- 8Meta 发布Llama 3,能力直逼GPT-4,一己之力拉高开源大模型水位_llama3 接近 gpt 4
- 9tkinter控件布局grid_tkinter.grid csdn
- 10python中的idle在哪里_idle 文件名
当前位置: article > 正文
python爬虫--酷狗音乐榜单TOP500_酷狗音乐top500数据
作者:AllinToyou | 2024-05-22 16:24:53
赞
踩
酷狗音乐top500数据
前期准备:
- 正则表达式:
\d:代表一个数字
{}:代表字符个数
*:代表任意字符
[]:[]内字符只能取其一
+:表示前字符至少出现过一次
-:一个范围
?:表示前一个字符可出现0次或1次
[a-z]{3}[1-9]{6}:前三个为字符:a-z,四到十位为数字1-9 密码
\d{3}-d{8}:3个数字-8个数字 电话号码
- 网页构成:
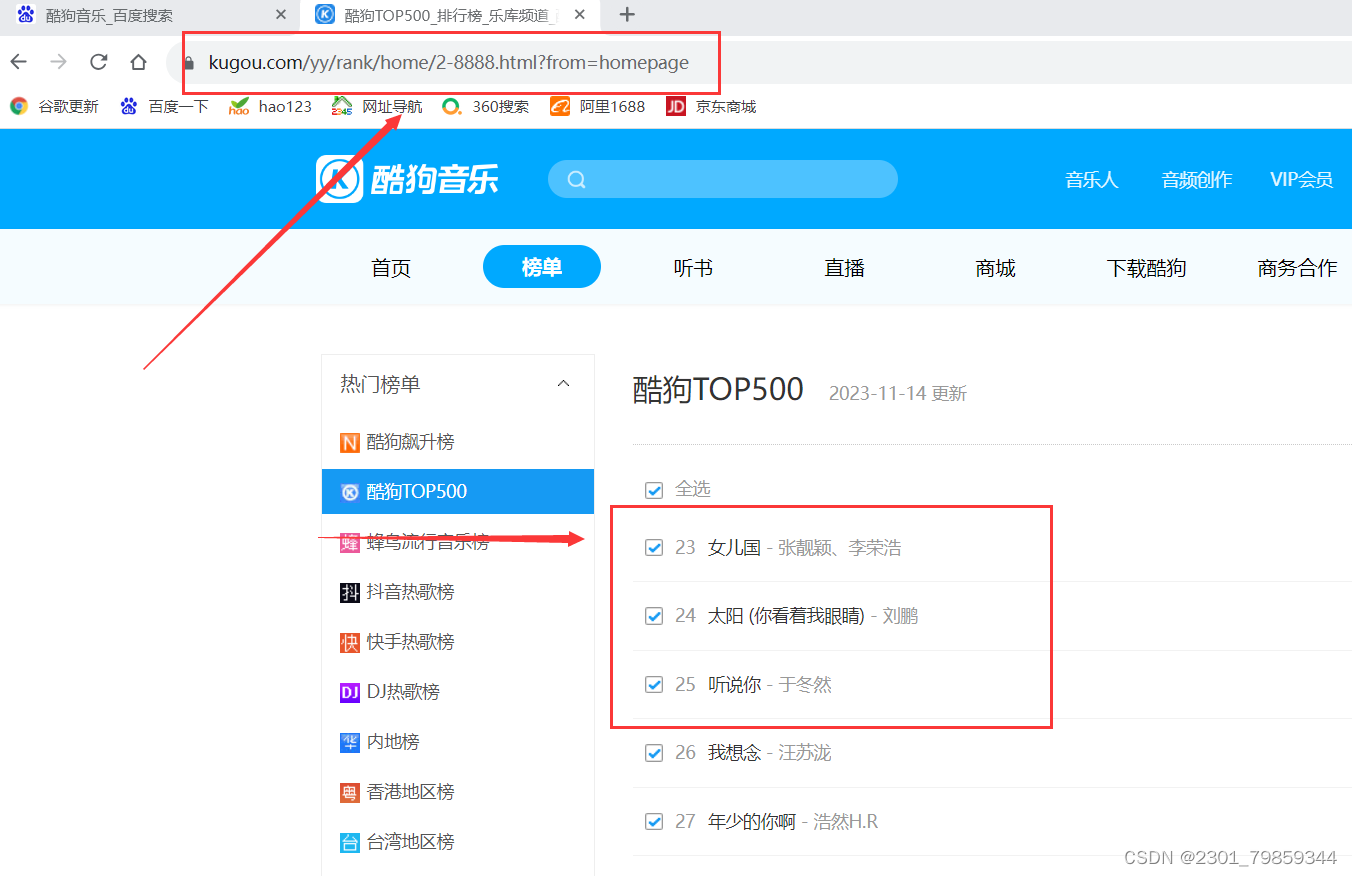
我们需要top500首歌,找到网页,查看地址,每页22首,需要23个页面,我们就确定网页号,由正则表达式知道{}表示字符个数确定{}范围为1-24
range函数:
range(a,b) i>=a&&i<b
range(1,5)得到{1,2,3,4}
https://www.kugou.com/yy/rank/home/{}-8888.html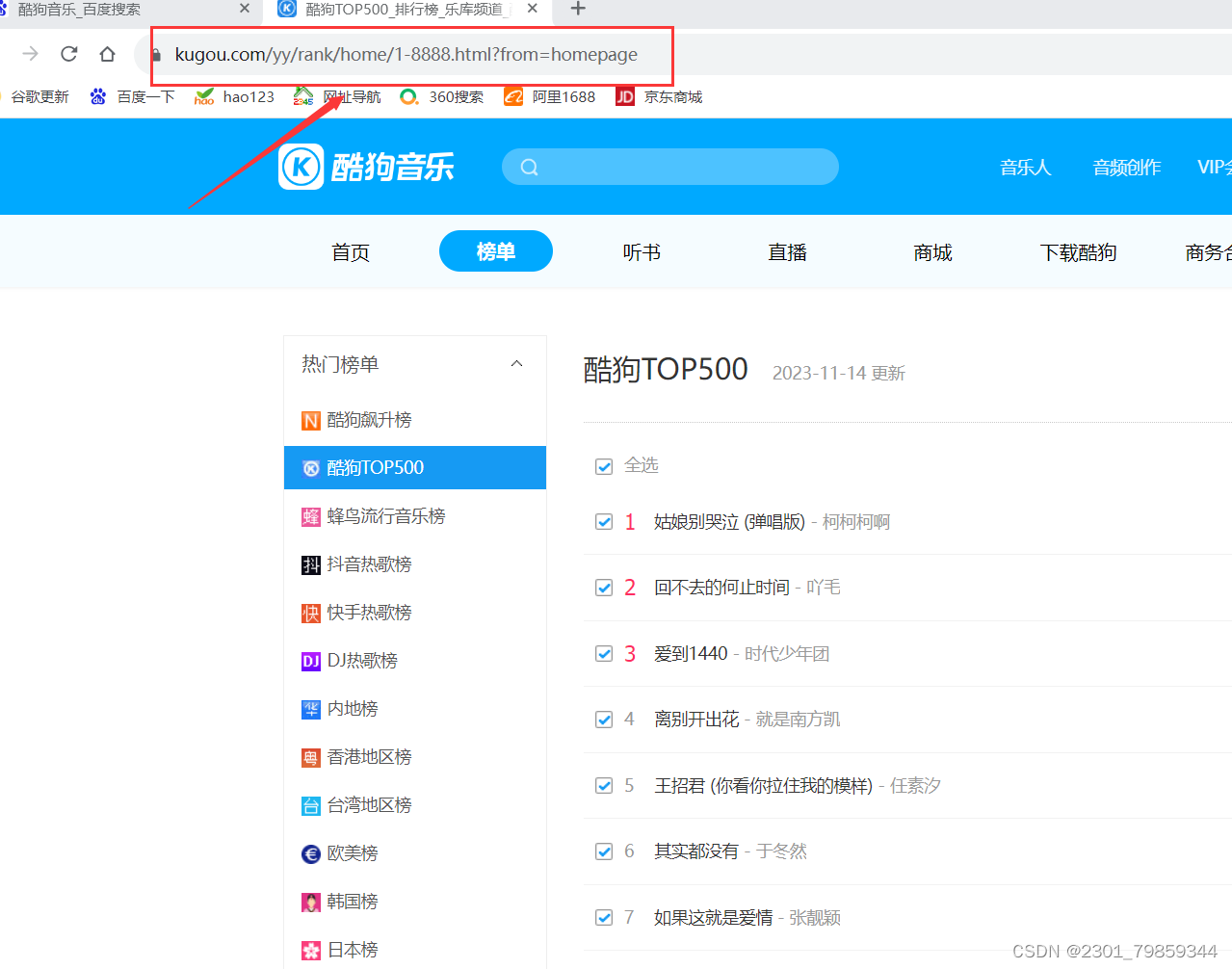
User-Agent获取:
在Chorme网页,输入
Chrome://version
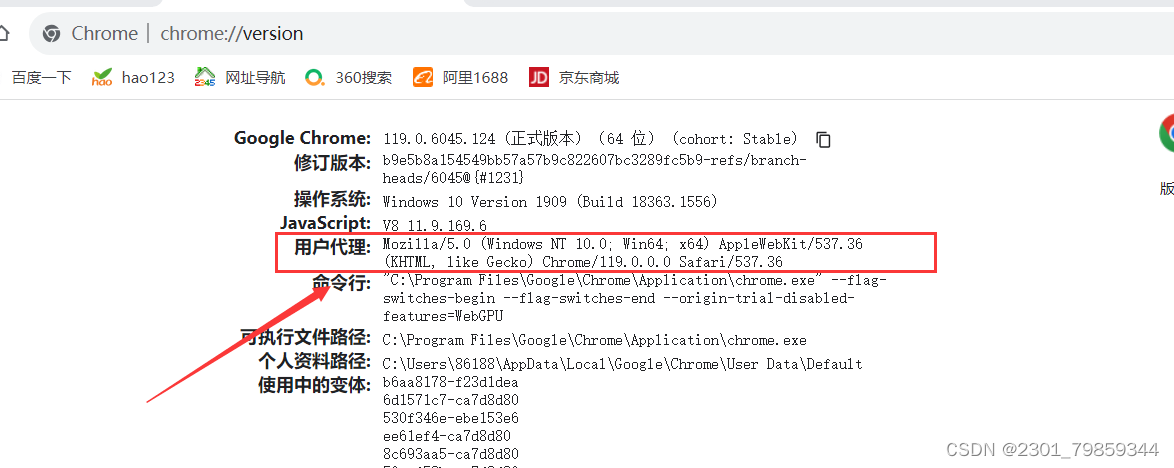
找到用户代理,后面代码就是
- headers={
- 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
- }
实际操作:
需要下载库:
将下面xxxx换成下面几个库,cmd环境下,运行安装即可。
urllib lxml requests bs4(可能会缺少模块就使用下面这个命令,快速下载,还有很多镜像源,和直接下载的方法,可以自己百度找找)
pip install xxxx -i http://pypi.douban.com/simple --trusted-host pypi.douban.com完整代码:
- import requests
- from bs4 import BeautifulSoup
- import time
-
- headers={
- 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
- }
- #User-Agent需要自己打开Chrome浏览器找到复制
- #User-Agent是Chrome浏览器开发者工具,便于伪装成浏览器
- def get_info(url): #定义函数爬取信息
- wb_data=requests.get(url,headers=headers)
- soup=BeautifulSoup(wb_data.text,'lxml')
- ranks=soup.select('span.pc_temp_num')
- titles=soup.select('div.pc_temp_songlist>ul>li>a')
- times=soup.select('span.pc_temp_tips_r>span')
- for rank,title,time,in zip(ranks,titles,times):
- data={
- 'rank':rank.get_text().strip(),
- 'singer':title.get_text().split('-')[0],
- 'song':title.get_text().split('-')[1],
- 'time':time.get_text().strip()
- }
- print(data)
-
- if __name__=='__main__':
- urls=['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,24)]
- for url in urls:
- get_info(url)
- time.sleep(1)

运行结果:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/608991
推荐阅读
相关标签

