
- 1国产、自研、开源数据库的选型与应用 DAMS 2020
- 2uiautomation:基于windows的ui自动化框架_uiautomation安装
- 3软件测试之测试用例和缺陷报告模板分享_软件测试测试问题记录模版
- 4紫光同创国产FPGA学习之Design Editor_紫光同创ide如何查看fpga的布局
- 5在neo4j桌面版中利用.dump文件将已构建的图数据库中的数据导入到新数据库中_neo4j使用db.dump
- 6Stable Diffusion API 调用实战:详细教程_serverless-stable-diffusion-api
- 7MATLAB初学者入门(19)—— 均值算法
- 8(面试版)大数据组件的区别总结(hive,hbase,spark,flink)_hive spark flink
- 9必备年终绩效工作总结模板
- 10论文笔记:UrbanGPT: Spatio-Temporal Large Language Models
改善图像处理效果的五大生成对抗网络
赞
踩
作者 | Martin Isaksson
译者 | Sambodhi
策划 | 刘燕
在图像处理方面,机器学习实践者们正在逐渐转向借助生成对抗网络的力量,本文带你了解其中五种生成对抗网络,可根据自己的实际需求进行选型。
本文最初发表于 Towards Data Science 博客,经原作者公司 PerceptiLabs 授权,InfoQ 中文站翻译并分享。
在图像处理方面,机器学习实践者们正在逐渐转向借助生成对抗网络(Generative Adversarial Network,GAN)的力量。
实际受益于使用生成对抗网络的应用包括:从基于文本的描述生成艺术品和照片、放大图像、跨域翻译图像 (例如,将白天的场景改为夜间)及许多其他应用。为实现这一效果,人们设计了许多增强的生成对抗网络架构,它们具有独特的功能,可用于解决特定的图像处理问题。
在本文中,我们选择五种生成对抗网络进行深入讨论,因为它们提供了广泛的功能,从放大图像到创建基于文本的全新图像。
Conditional GAN
Stacked GAN
Information Maximizing GAN
Super Resolution GAN
Pix2Pix
如果你需要快速回顾生成对抗网络,请查阅博文《探索生成对抗网络》(Exploring Generative Adversarial Networks,https://blog.perceptilabs.com/exploring-generative-adversarial-networks-gans),这篇文章介绍了 生成对抗网络 如何训练两个神经网络:生成器和判别器,它们可以学习生成越来越逼真的图像,同时提高其将图像分类为真或假的能力。
Conditional GAN
Conditional GAN 面临的挑战之一是无法控制图像生成类型。生成器只是简单地从随机噪声开始,并反复创建图像,希望这些图像能随着时间的推移趋向于表示训练图像。
Conditional GAN(cGAN),通过利用额外信息,例如标签数据(也就是类标签)解决了这个问题。这样还能使训练更加稳定和快速,同时提高生成图像的质量。举例来说,cGAN 呈现的不同类型的蘑菇图片及标签,可以通过训练来产生和识别那些准备采摘的蘑菇。该模型可作为工业机器人计算机视觉的基础,通过编程实现蘑菇的搜寻与采摘。当不具备这些条件时,标准的生成对抗网络(有时也称为无条件生成对抗网络)仅仅依赖于将来自潜在空间的数据映射到产生的图像上。
cGAN 的实现方法有很多,有一种方法是将类标签输入判别器和生成器,从而对这两者进行调节。下图示例展示了一种标准的生成对抗网络生成手写数字图像,该网络通过增强标签数据,只生成数字 8 和 0 的图像。

图 1:一种 cGAN,类标签同时输入到生成器和判别器,以控制输出。
其中,可以对标签进行 独热 编码以去除序类型(ordinality),将标签作为附加层输入到判别器和生成器中,再将它们与各自的图像输入进行连接(即对生成器来说,与噪声连接起来,对生成器来说,与训练集连接起来)。因此,这两个神经网络在训练过程中都是以图像类标签为条件。
总结:当你需要控制生成的内容时(例如,生成训练数据的子集),使用 cGAN。
Stacked GAN
要是我们能够直接让电脑画幅图,是不是很酷?这正是 Stacked GAN(StackGAN)背后的灵感所在,在论文《StackGAN:基于堆叠式生成对抗网络的文本到逼真图像合成》(StackGAN:Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks) 中,作者对此进行了描述。
StackGAN 主要是一个两阶段的草图细化过程,与画家作画的方法相似,即先画出一般元素,然后再进行细化:
阶段一,生成对抗网络:它以给定的文字描述为条件,勾画出对象的原始形状和基本颜色,并根据随机噪声矢量绘制出背景布局,得到低分辨率图像。阶段二,生成对抗网络:纠正阶段一低分辨率图像中的缺陷,通过再次阅读文字说明来完善对象的细节,从而生成高分辨率的逼真图像。
作者对其模型的架构作了如下概述:

图 2:StackGAN 模型架构概述。
尽管使用普通的生成对抗网络也可以解决这一问题,但输出的图像可能缺少细节,且可能限制在较低的分辨率。StackGAN 的两阶段架构基于 cGAN 的思想来解决这一问题,就像作者在论文中说的那样:通过对阶段一结果和文本的再次调节,阶段二生成对抗网络学习捕捉阶段一生成对抗网络遗漏的文本信息,并为对象绘制更多细节。模型分布支持通过粗对齐得到的低分辨率图像与图像分布支持得到了较好的交叉概率。而这正是阶段二生成对抗网络能够产生更好高分辨率图像的根本原因。
要了解更多关于 StackGAN 的信息,请查看作者的 GitHub 仓库(https://github.com/hanzhanggit/StackGAN),他提供了一些模型,以及鸟类和花卉的图片。
总结:当你需要从完全不同的表示方式(例如,基于文本的描述)来生成图像时,请使用 StackGAN。
Information Maximizing GAN
类似于 cGAN,Information Maximizing GAN(InfoGAN)利用额外的信息对生成的内容进行更多的控制。通过这样做,它可以学习分解图像的各个方面,比如人的发型、物体或者情感,所有这些都是通过无监督训练。然后,这些信息可以用于控制生成图像的某些方面。举例来说,给定的人脸图像中,有些人戴着眼镜,InfoGAN 就可以被训练成对眼镜的像素进行拆分,然后用它来生成戴眼镜的新人脸。
在 InfoGAN 中,一个或多个控制变量与噪声一起被输入到生成器中。生成器的训练使用了一种称为辅助模型的附加模型中包含的 互信息(mutual information)进行的,该模型与判别器拥有相同的权重,但预测用于生成图像的控制变量的值。这种互信息是通过对生成器生成的图像的观察获得的。与判别器一起,辅助模型对生成器进行训练,使 InfoGAN 既能学会生成 / 识别假图像与真图像,又能捕捉生成图像的显著属性,从而学会改进图像生成。
这个架构总结如下图所示:
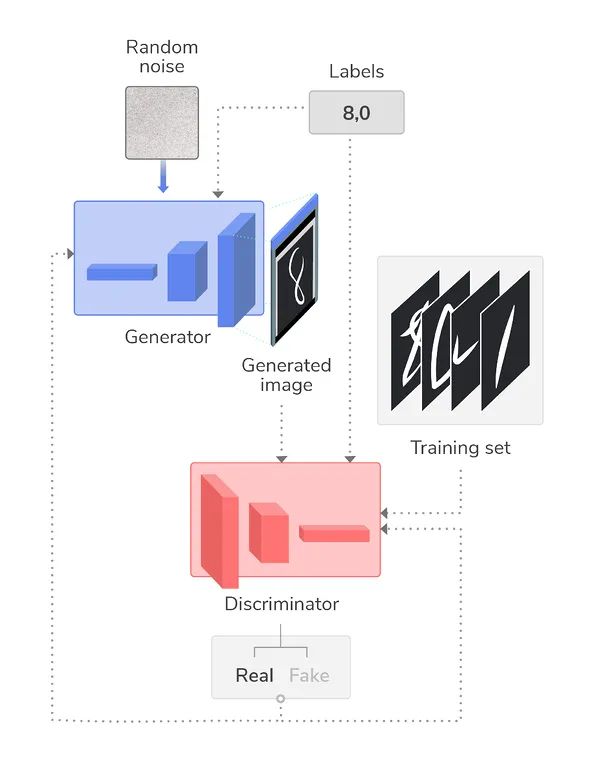
图 3:InfoGAN 架构概要
要了解关于 InfoGAN 的更多信息,请查看博文:《InfoGAN:生成对抗网络第三部分》(InfoGAN — Generative Adversarial Networks Part III ,https://towardsdatascience.com/infogan-generative-adversarial-networks-part-iii-380c0c6712cd)
总结:当你需要将图像的某些特征分离出来,以便合成到新生成的图像中时,请使用 InfoGAN。
Super Resolution GAN
图像增强领域正在不断发展,与双三次插值等传统统计方法相比,它更依赖于机器学习算法。Super Resolution GAN(SRGAN)就是这样一种机器学习方法,它可以将图像提升到超高分辨率。
SRGAN 利用生成对抗网络的对抗性,与深度神经网络相结合,学习如何生成放大的图像(最高可达到原始分辨率的四倍)。这些生成的超分辨率图像准确性更好,且通常会获得较高的 平均意见分(mean opinion scores,MOS)。
在对 SRGAN 进行训练时,首先将高分辨率的图像下采样到低分辨率的图像,然后输入到生成器中。然后,生成器尝试将该图像上采样到超分辨率图像。判别器用来比较生成的超分辨率图像和原始高分辨率图像。判别器的生成对抗网络损耗随后反向传播到判别器和生成器,如图所示:
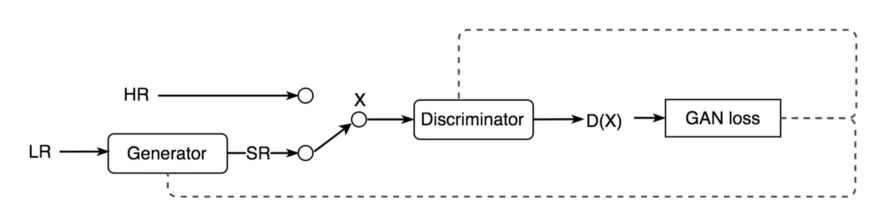
图 4:SRGAN 架构。LR= 低分辨率图像,HR= 高分辨率图像,SR= 超分辨率图像,X= 判别器的输入,D(X)= 判别器对 HR 和 SR 的分类。
生成器使用了许多 卷积神经网络(convolution neural networks,CNN)和 ResNet,以及批归一化层和激活函数 ParametricReLU。这些首先对图像进行下采样,然后再进行上采样,生成超分辨率图像。同样,判别器使用一系列卷积神经网络,以及密集层、Leaky ReLU 和 sigmoid 激活,以确定图像是原始的高分辨率图像,还是由生成器输出的超分辨率图像。
要了解更多关于 SRGAN 的信息,请参阅这篇博文《生成对抗网络:超分辨率生成对抗网络(SRGAN)》(GAN — Super Resolution GAN (SRGAN))。
总结:当你需要在恢复或保留细粒度、高保真细节的同时放大图片,请使用 SRGAN。
Pix2Pix
正如我们在博客中讨论的《机器学习用于图像处理和计算机视觉的五大方法》(Top Five Ways That Machine Learning is Being Used for Image Processing and Computer Vision,https://blog.perceptilabs.com/top-five-ways-that-machine-learning-is-being-used-for-image-processing-and-computer-vision#Object_Instance),对象分割是一种方法,将数字图像中的像素组分割成片段,然后可以在一个或多个图像中作为对象进行标记、定位,甚至跟踪。
分割也可以用来将输入图像转化为输出图像,以达到各种目的,如从标签图合成照片,从边缘图重建物体,及对黑白图像进行着色。
分割可以使用 Pix2Pix 来完成,Pix2Pix 是一种 cGAN,用于图像到图像的翻译,首先训练一个 PatchGAN 判别器来对翻译的图像进行分类,判断这些图像的真假,然后用来训练一个基于 U-Net 的生成器来产生越来越可信的翻译。使用 cGAN 意味着该模型可以用于多种翻译,而无条件生成对抗网络则需要额外的元素,如 L2 回归,以调节不同类型翻译的输出。

图 5:使用 Pix2Pix 进行着色的示例。此处显示了鞋子的黑白图画(输入)及其训练数据(基准真相),以及 Pix2Pix 生成的图像(输出)。
下图显示了 Pix2Pix 中的判别器如何在对黑白图像进行着色的情况下首先进行训练。
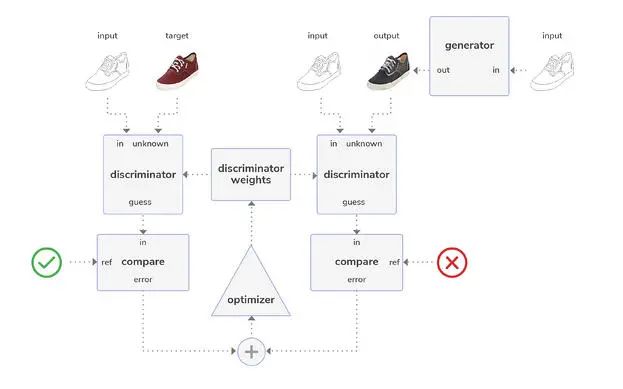
图 6:首先在 Pix2Pix 架构中对判别器进行训练。
在此,将黑白图像作为输入提供给生成器,生成器会生成一个彩色版本(输出)。判别器随后进行两次比较:第一次将输入与目标图像(即,代表基准真相的训练数据)进行比较,第二次将输入与输出(即,生成的图像)进行比较。然后,优化器根据两次比较的分类误差调整判别器的权重。
现在已经训练好了判别器,就可以用来训练生成器了。

图 7:使用训练好的判别器在 Pix2Pix GAN 中训练生成器。
在这里,输入的图像被同时馈送到生成器和判别器中。(训练好的)判别器将输入图像与生成器的输出进行比较,并将输出与目标图像相比较。随后,优化器调整生成器的权重,直到训练到生成器可以在大多数时间对判别器进行欺骗。
要了解更多关于 Pix2Pix 的信息,请参阅这篇文章《Pix2Pix:图像到图像的翻译神经网络》(Pix2Pix – Image-to-Image Translation Neural Network)。此外,请务必查看这个 GitHub 仓库。
总结:当你需要将源图像的某些方面翻译成生成的图像时,请使用 Pix2Pix GAN。
结语
生成对抗网络,更具体地说,是它们的判别器和生成器,可以用各种方式来构建,以解决广泛的图像处理问题。以下总结可以帮助你选择适合你的应用的生成对抗网络。
cGAN:控制(如限制)生成对抗网络的分类应进行训练。
StackGAN:将基于文本的描述用作创建图像的命令。
Infogan:解析你想要生成的图像的特定方面。
SRGAN:在保持细粒度的细节的同时,放大图片。
pix2pix:对图像进行分割和翻译(例如,对图像进行着色)。
作者介绍:
Martin Isaksson,PerceptiLabs 的联合创始人兼 CEO,这是一家专注于让机器学习变得简单的创业公司。
原文链接:
https://towardsdatascience.com/five-gans-for-better-image-processing-fabab88b370b
- 公众号:AI蜗牛车
-
- 保持谦逊、保持自律、保持进步
-
-
-
- 个人微信
- 备注:昵称+学校/公司+方向
- 如果没有备注不拉群!
- 拉你进AI蜗牛车交流群
-
-
-

