
热门标签
热门文章
- 1细数GitHub 上既有趣又有用的 Java 项目Top14
- 2【独家源码】ssm课题申报系统ogvvo计算机毕业设计问题的解决方案与方法_ogv审核
- 3R+python︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
- 42023如果纯做业务测试的话,在测试行业有出路吗?_业务测试是不是最简单的
- 5斐波那契数列三种实现【C++】_c++斐波那契数列
- 6这里聚焦了全球嵌入式技术风景~
- 7hive一次查询多个分区表_《Hive用户指南》- Hive性能调优相关
- 8Git: ‘LF will be replaced by CRLF the next time Git touches it‘ 问题解决办法
- 9记录在阿L做外包的日子,给正在(金三银四)的你一点经验_阿里w2薪资
- 10百度智能云“千帆大模型平台”升级,大模型最多、Prompt模板最全—测评结果超预期_智能评分 评分 promot
当前位置: article > 正文
大语言模型在研究领域的应用——知识图谱增强的大语言模型
作者:Cpp五条 | 2024-04-27 09:48:03
赞
踩
大语言模型在研究领域的应用——知识图谱增强的大语言模型
尽管大语言模型具有出色的自然语言生成能力,但在知识密集型任务中常常面临一些挑战,例如可能生成幻象或事实错误内容。因此,在一些特定场景中,需要向大语言模型补充外部的知识信息。知识图谱(Knowledge Graph, KG)存储了大量的结构化知识信息,常用于知识密集型的任务场景,也广泛被用于补充大语言模型的知识信息。本部分将从两个方面讨论如何使用知识图谱增强大模型,包括基于子图检索的方法和基于查询交互的方法。
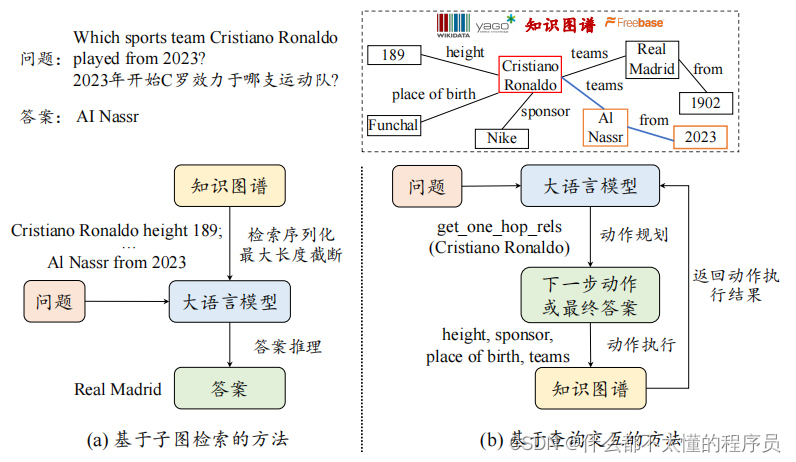
基于子图检索的方法
基于检索增强的方法通常首先从知识图谱中检索一个相对较小的子图(知识检索),然后将该子图序列化并作为提示的一部分,输入给大语言模型以丰富其相关背景知识(知识利用)。对于知识检索,可以使用启发式方法过滤掉知识图谱上不重要的节点。这类方法通常使用 PageRank 等图节点排序算法来计算知识图谱上每个节点的重要性,并按照预先设定的阈值筛选出重要的节点以构成
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/496105
推荐阅读
相关标签

