- 1我的参会记要:OceanBase第二届开发者大会
- 2用栈实现二叉树 C&java_根据栈建立树
- 3十、CentOS7安装HBase-2.1.0伪分布式_hbase2.1.0 伪分布式安装
- 4分布式一致性算法简介_持续一致性如何计算两个副本中的向量时钟
- 52021-03-11 php 获取文件/上传文 是否是图片格式(与后缀无关,取文件实际内容)_--enable-exif
- 6算法复杂度分析(3600字)_论文中为何要加复杂性分析
- 7rejected –non-fast-forward解决方法
- 8微信小程序与web-view网页进行通信的尝试
- 99、Flink 用户自定义 Functions 及 累加器详解
- 10使用Spring Boot实现大文件断点续传及文件校验_springboot整合文件断点续传
Multiport RAM,多读多写寄存器-——基于FPGA BRAM的多端口地址查找表与FPGA BRAM的资源分析...
赞
踩
本项目开源,如需要完整源代码移步到此链接:
https://blog.csdn.net/qq_45634652/article/details/138034081?spm=1001.2014.3001.5502
一、背景
在多端口交换机的设计中,交换机的每个端口都会各自维护一张查找表,数据帧进入到交换机后,需要进行查表和转发。但随着端口数量和表项需求的增加,每个端口都单独维护一张表使得FPGA的资源变得非常紧张。因此,需要一张查找表(本质是可读可写的RAM),能够满足多读多写的功能。但在Xilinx FPGA上,Xilinx提供的BRAM IP最高只能实现真双端口RAM。不能满足多读多写的需求。
补充:这里不使用其他RAM类型如URAM的原因是,BRAM拥有更好的时序,更适合在高速交换中用于查找表。
二、手写Multiport Ram
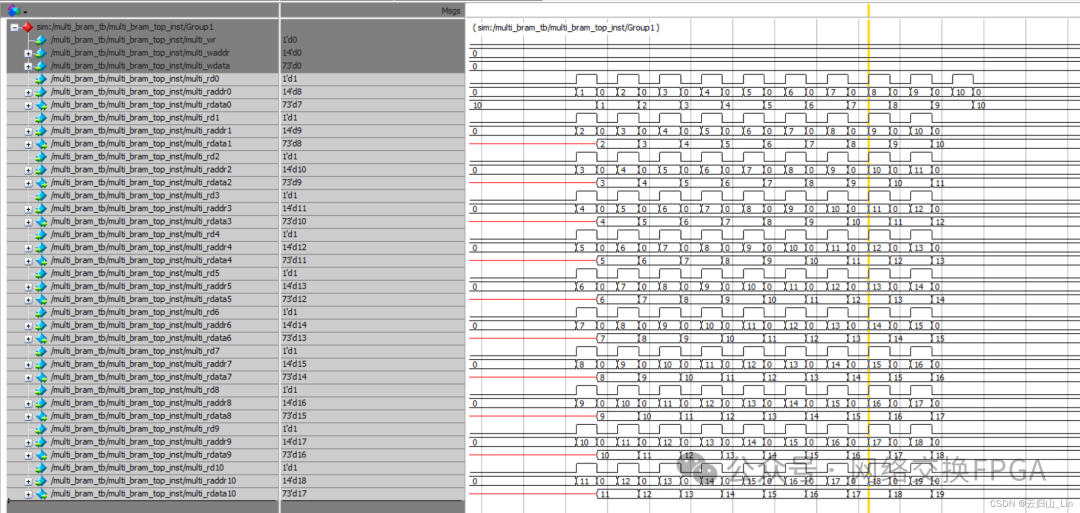
Multiport Ram,即多读多写存储器,本工程实现的是1个口写,同时满足11个口读的BRAM。
为了让vivado在综合的时候把手写ram例化为BRAM,我们需要按照官方手册的要求编写multiport ram。这时需要通过(*ram_style="block"*)对array进行修饰。
查看Vivado的官方手册ug901可知,对于Distributed RAM(LUTRAM)和Dedicated Block RAM(BRAM),二者都是写同步的。主要区别在于读数据,前者为异步,后者为同步的。

下面给出一种手写多端口bram的方案并给出一种优化FPGA bram资源利用的方法。
Multiport RAM 代码方案
实现多端口bram最简单的方法就是把读数据部分的逻辑复制11份,写数据部分的逻辑保留1份。部分代码如下,实现位宽73bit,深度为16K的multiport ram:

资源评估
利用vivado综合实现后,消耗的资源如下
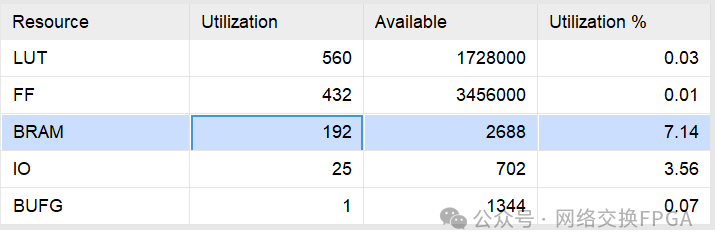
MultiportRAM:16K深度,73位宽的单口写,11口读的RAM消耗的BRAM数为192个。
普通真双口RAM:利用vivado IP核生成的16K深度,73bit位宽的真双口RAM消耗的BRAM数为32个。即如果11个端口各自维护一张地址查找表共使用352个RAM。
对比发现,在满足11个端口同时读地址查找表的条件下,多端口RAM比普通RAM节约了45%左右的BRAM资源
三、Multiport RAM 资源利用的优化
可能有的同学说,在某些大工程里面,192个BRAM还是有点多。下面我给出了一种降低BRAM资源消耗的方法。
首先我们把例化的ram array的位宽翻倍
- //原本
- (*ram_style="block"*)reg [DATA_WIDTH-1:0] bram [0:DEPTH-1];
- //现在
- (*ram_style="block"*)reg [DATA_WIDTH+DATA_WIDTH-1:0] bram [0:DEPTH-1];
(有同学会问了,这样资源消耗不是翻倍了吗?···别急!)
我们把需要写入RAM的数据,73位写data复制成两份,同时写进bram的高73位和低73位,地址不变,其中multi_wdata是我们要写进表中的73位表项,代码如下:
- //bram例化模块的写使能、地址和数据
- .we ( multi_wr),
- .wr_addr (multi_waddr),
- .wr_data ({multi_wdata,multi_wdata})
在bram输出中,每两个端口共用一个143位的bram行,并根据使能情况赋值:
***补充:具体代码在文章开头链接
资源评估
利用vivado综合实现后,消耗的资源如下
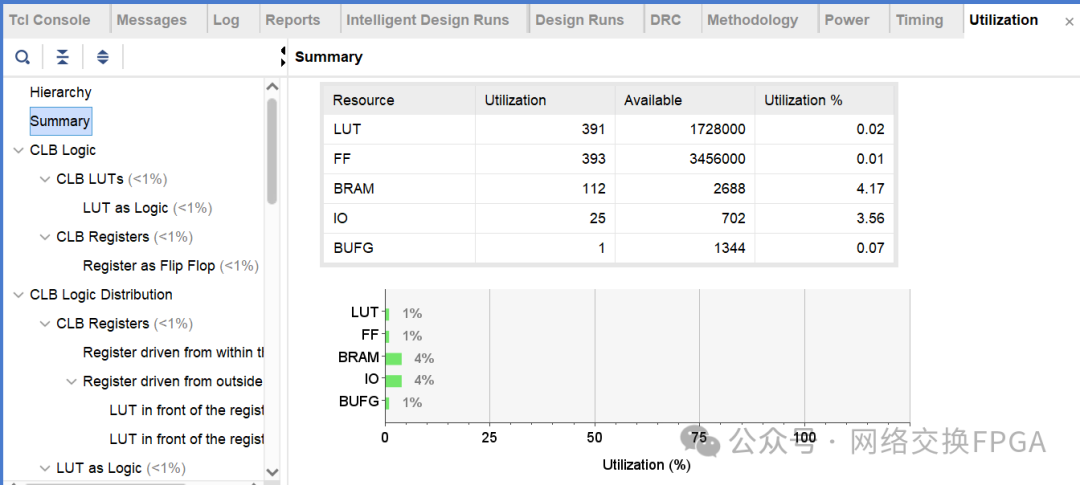
MultiportRAM:16K深度,146位宽的单口写,11口读的RAM消耗的BRAM数为112个。
普通真双口RAM:利用vivado IP核生成的16K深度,73bit位宽的真双口RAM消耗的BRAM数为32个。即如果11个端口各自维护一张表共使用352个RAM
对比发现,在满足11个端口同时读地址查找表的条件下,多端口RAM比普通RAM节约了68%左右的BRAM资源
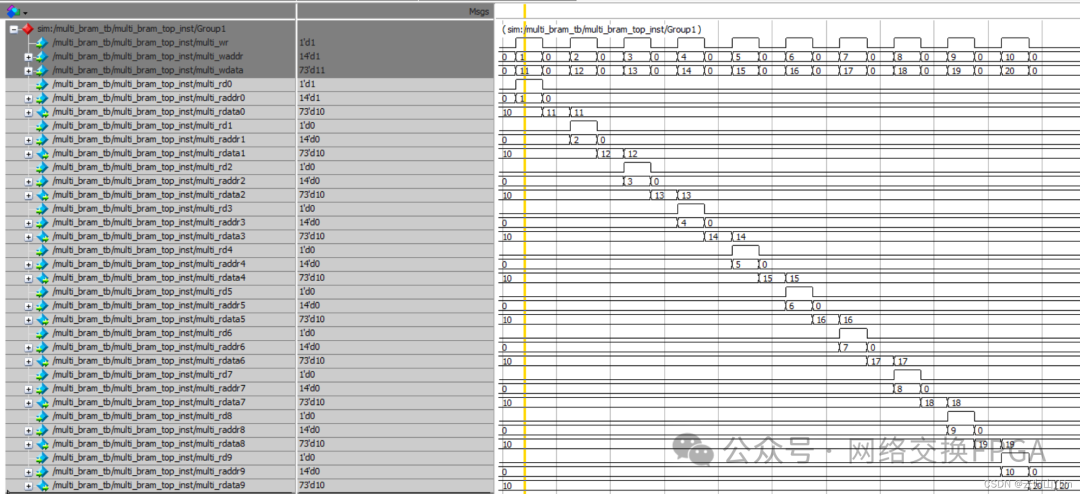
四、防止读写冲突的组合逻辑设计(写优先)
代码原理,利用组合逻辑时序,当写入地址和读地址相同时,写入地址、数据正常进行,但读端口不对RAM进行读取,而是将写入端的数据直接赋值给读出端的数据。
下一拍,即读写冲突结束后的下一拍,再读一拍RAM中的数据,使得读端口数据保持这一次读的结果(因为组合逻辑在读写冲突时没有真正读RAM,所以RAM输出data会保持上一次输出的data),但这一步不是必要的,纯粹为了好看。
部分代码如下:
***补充:具体代码在文章开头链接
读写冲突的仿真结果如下:
五、Multiport RAM仿真和时序
所有写端口都是一拍写入。读端口是第一拍读使能,读地址,第二拍读出数据。
1.单口写数据

2.单端口读数据

3.多口读相同数据
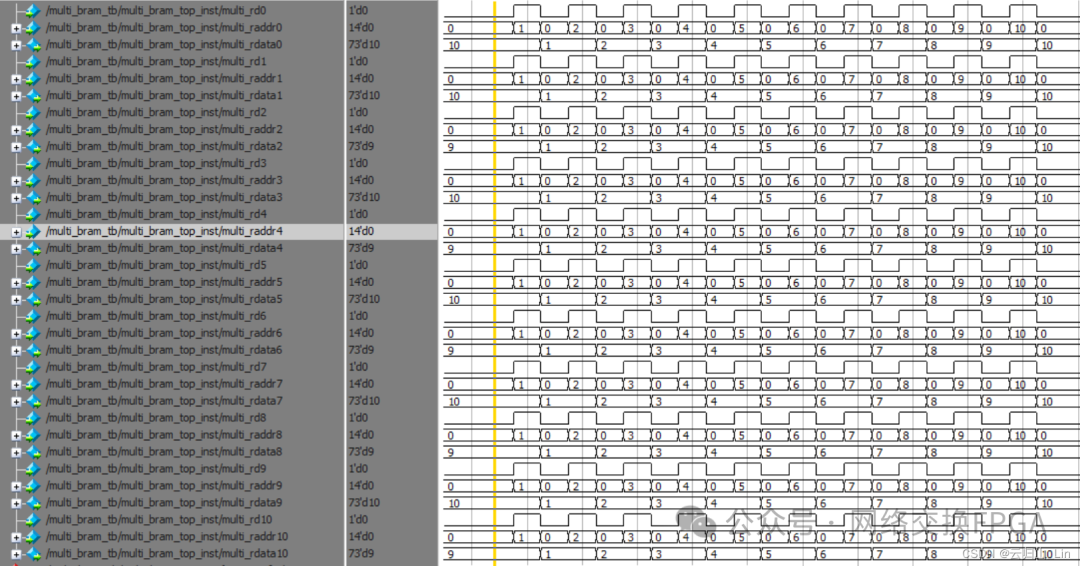
4.多口同时读不同数据