
- 1Android Studio Giraffe 发布,快来看有什么更新吧_android studio长颈鹿
- 2常见消息队列:ActiveMQ、RabbitMQ、RocketMQ、Kafka的区别总结_activemq rabbitmq(1)_rabbitmq 、 rocketmq、 kafka、 activemq 区别
- 3供应商管理软件 oracle,供应商全生命周期管理 - oracle.pdf
- 4Django 解决No URL to redirect to.
- 5PHP后台微信校园互助小程序平台(毕设作品)_校园互助微信小程序
- 6树莓派学习(二)笔记本连接_树莓派网线连接上笔记本有什么反应
- 7flowable 和activiti 数据库表结构对比说明_activiti flowable
- 8嵌入式室内环境参数监控系统设计_基于嵌入式的智能家居环境监测设计方案
- 9SHA-256算法的原理与C/C++实现_sha256 c++
- 10STM32之PWM预分频与重装载值与占空比_stm32 pwm中的预分频系数
什么是diffusion model? 它为什么好用?
赞
踩
作者 | 凌晗 编辑 | 汽车人
原文链接:https://www.zhihu.com/question/613579202/answer/3310826408
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【扩散模型】技术交流群
本文只做学术分享,如有侵权,联系删文
简介
NCSN (Noise Conditional Score Networks)来自于宋飏博士发表在 NeurIPS2019 上面的文章“Generative Modeling by Estimating Gradients of the Data Distribution”,也是推动扩散模型领域兴起的重要工作之一,比 DDPM 发表的还要早。这篇工作提出了基于“score”的生成式模型,和DDPM扩散模型有着千丝万缕的联系,后面宋飏博士发表中 ICLR2021 上的另一篇工作将 NCSN 和 DDPM 在 SDE 视角下进行了很好的统一。
宋飏博士在博客中提到,score-based generative model 的主要优点是:
有媲美 GAN 的生成质量,但是不需要对抗训练
灵活的模型架构、精确的对数似然计算
可以用于解决逆问题,并且不需要重新训练网络
从生成模型到 score-based model
生成模型
首先回顾一下,生成模型是什么?
假设我们从一个未知的数据分布p(x)中,独立的采样出了一系列的样本{,,...,},也就是我们常说的“数据集”。生成模型的目的就是,从这些含有有限样本的“数据集”出发,去拟合原来的数据分布p(x),从而让我们能够继续合成更多类似的样本。
为了实现这个目标,我们首先需要想办法去建模并估计数据的概率分布p(x)。一种方式是,类似于似然模型(likelihood-based models)那样,直接定义出来一个概率密度函数(probability density function, p.d.f.)或者概率分布函数(probability mass function, p.m.f.)。以概率密度函数为例:
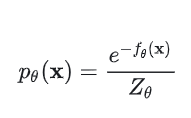

为了实现对原数据分布的拟合,可以通过最大似然估计来训练这个公式要求
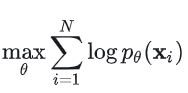
这个公式要求是一个归一化的概率密度函数——这一点其实会给我们带来很多麻烦。因为如果要求是归一化的,就必须知道归一化常数,但是对于任意的来说往往是一个难以求解的量。因此,为了让上述基于最大似然估计的训练能够进行,似然模型往往只能采用特定的网络结构(比如在自回归模型中采用常规卷积结构,在 normalizing flow models 中采用 invertible networks 结构)让可解,或者通过其他方式去近似(比如 VAE 中的变分推理,contrastive divergence 中的 MCMC),但是往往计算复杂度很高。
为了解决上述问题,宋飏博士等人提出了 score-based model,基本思想是通过对概率密度函数的梯度进行建模,而不是直接对概率密度本身进行建模,来间接表征数据的分布,并规避难以求解的问题。
score-based model
“score function”,或者简单的称为“score”,其实就是论文题目中提到的“Gradients of the Data Distribution”,更具体来说其实是概率密度函数的对数的梯度,即: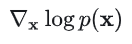 用来对其进行建模/拟合的模型就叫做——score-based model,记作。和上面直接建模概率密度函数p(x)时不同,score-based model 的优势是不会受到归一化常数的制约,可以直接用上面提到的可学习的实值函数(energy-based model)来建模,不用考虑归一化常数的问题(因为求导时相关项变为了 0):
用来对其进行建模/拟合的模型就叫做——score-based model,记作。和上面直接建模概率密度函数p(x)时不同,score-based model 的优势是不会受到归一化常数的制约,可以直接用上面提到的可学习的实值函数(energy-based model)来建模,不用考虑归一化常数的问题(因为求导时相关项变为了 0):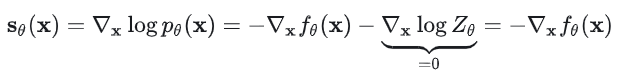 这样我们就可以灵活的选择不同类型的网络架构,不受归一化常数是否易求解的制约。
这样我们就可以灵活的选择不同类型的网络架构,不受归一化常数是否易求解的制约。
我们也可以给 score 的物理意义一个直观的解释——它是数据的对数概率密度增长最快的方向。

观察上面一个数据分布的对数概率密度梯度场可以发现,梯度方向汇聚到了两个中心区域,这代表了这两个区域是对数概率密度最大的地方——也就是此数据域的分布的核心、最能代表这个数据域先验的区域。
回想一下,对于生成模型来说,我们期望生成的图像采样于哪些概率分布区域呢?当然就是概率密度最大的区域!因为这些区域是最符合数据域先验的,有助于生成“最真”的图像。所以如果我们能够通过 score-based model 估计出来数据分布的 score,并实现在其指示的概率密度大的地方进行采样生成,就可以得到理想的生成结果。
如何用 score-based model 生成样本——朗之万采样
假设我们已经获得了 score-based model,我们要如何实现采样生成的步骤呢?
1
朗之万采样示意图

朗之万动力学方程是描述物理学中布朗运动的微分方程,相关推导涉及到伊藤积分等一系列随机过程相关的数学,还是比较复杂的。

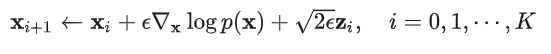
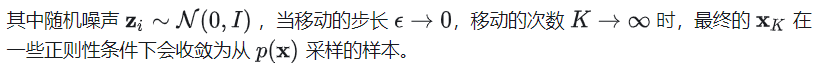

如何获得 score-based model——score matching
上面我们已经解决了从训练好的 score-based model 进行采样生成样本的问题,但是如何设计和训练 score-based model 则是这一切的基础和关键。
首先写出目标函数(损失函数),和似然模型类似,score-based model 也可以把最小化模型和数据分布之间的 Fisher divergence 作为训练目标:
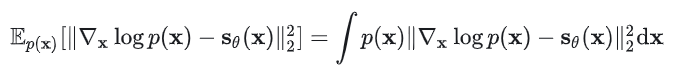
由于这个目标函数里面存在未知的先验分布p(x),所以没法直接计算。不过有一类叫做“score matching”的方法可以解决这个问题。和训练似然模型类似(知道归一化常数的前提下),score matching 方法可以在训练集上通过随机梯度下降(stochastic gradient descent, SGD),而不需要对抗训练,就可以估计出它的目标函数(score matching objective):
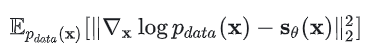

这个公式里面的是比较麻烦的地方,因为我们虽然有训练集的所有数据,但是很难直接算出来它的解析的概率分布,所以需要想办法避开它 ,经过一系列推导,我们可以把 score matching 目标函数简化为:
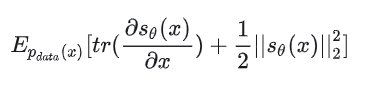
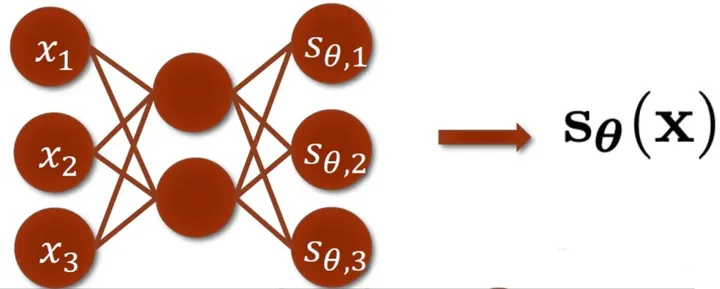
上式中,我们需要计算向量函数的偏导,即计算雅克比(Jocabian)矩阵,对的每一维输出都要计算一次导数(如下图,一般是个神经网络,可以用自动微分功能计算),运算量比较大,限制了 score matching 对深度网络和高维数据的处理能力。
论文中介绍了两个能够用于大尺度场景的 score matching 方法,一个是同年(2019)宋飏博士提出并发表的 Sliced Score Matching——使用一个随机向量v把雅克比矩阵降到一维变成向量: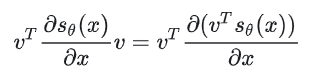

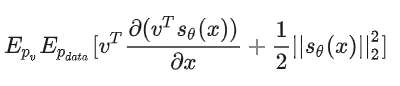
还有一种不用计算导数的 score matching 方法——Denoising Score Matching (DSM),这种方法是作者对 NCSN 采取的默认方法。详细推导见 DSM 原论文的 Sec4 和 Appendix,这里简述下基本思路:

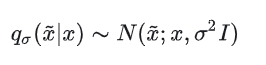
在这个分布中,原来的x相当于均值,相当于方差。我们能够直接写出这个分布的解析形式(高斯分布的概率密度函数),并求出:
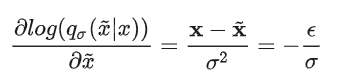
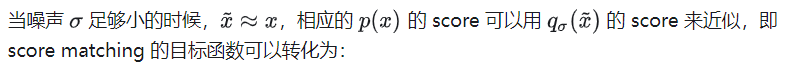
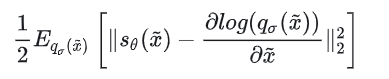

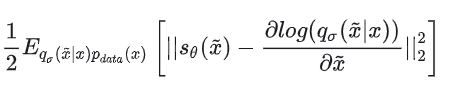

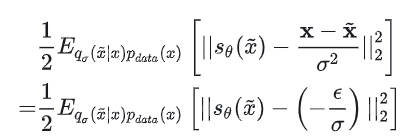
从这里我们可以看出,SDE/NCSN 中用网络去拟合的 score,和 DDPM 中用网络去拟合的噪声,其实本质是一样的。score 所对应的梯度方向,正是的方向,即从加噪图像还原回清晰图像的方向,也就是 Denoising Score Matching 和 DDPM 中“Denoise”的含义。
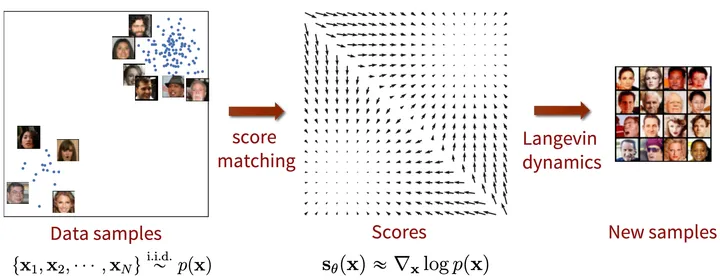
到目前为止,我们从概率分布的表示、估计到采样的过程基本已经完成了,整个“Score-based generative modeling”的过程可以总结如下图:
解决实现中的存在的问题——Annealed Langevin dynamics
虽然经过上面的设计与推导,score-based model 的基本方案已经有了,但是在具体实现中还有一些问题需要解决。这些问题的根源主要在于“流形假设”(manifold hypothesis)。
流形假设指出,现实世界的数据分布倾向于聚集在内嵌于一个高维空间(也叫 ambinet space)的低维流形上。这个假设对于大部分数据集(自然也包括这里用来训练 score-based model 的数据集)都是成立的,它也是流形学习的理论基础。

这些问题可能导致 score-based model 在训练时 loss 不收敛,从而无法得到理想的生成效果。下面对这两个问题产生的具体影响做进一步介绍,并给出作者的解决方案。
低概率密度区域 score 估计不准确

作者发现上述的基础方案在实际测试时,在数据密度低的区域,score 估计会不准确。这是因为数据分布的低概率密度区域意味着对应的数据样本比较少、权重较低,所以在有限的训练样本下(往往无法充分覆盖到概率密度很低的区域的数据样本),训练过程往往也很难充分的学习/拟合到相应区域的准确的 score。
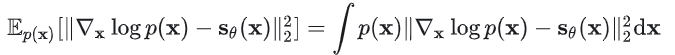
此外,从目标函数出发,可以看到上面的目标函数中p(x)其实是作为距离的权重因子的,所以对于数据分布的概率密度较小的区域,p(x)也比较小,也就意味着对应的样本在目标函数中的贡献比较低。
另外,由于朗之万动力学采样步骤的初始值是从任意分布中随机产生的,它大概率会落在真实数据分布 p(x)(以及训练集数据分布的低密度区域甚至是分布之外,这种从一开始就出现的不匹配也会导致朗之万采样过程难以生成理想的样本。
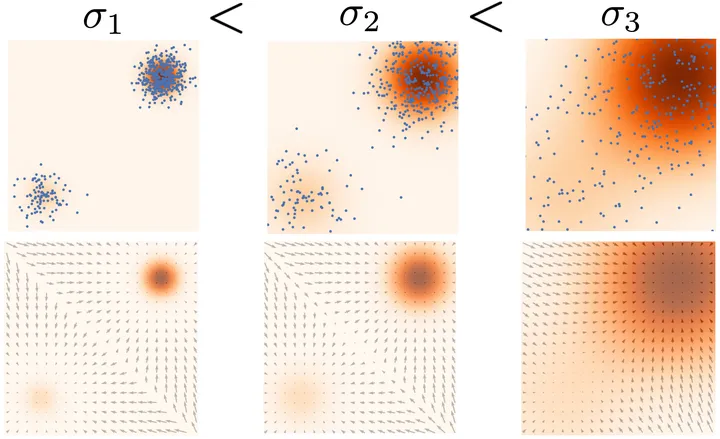
“忽视”数据分布的比例
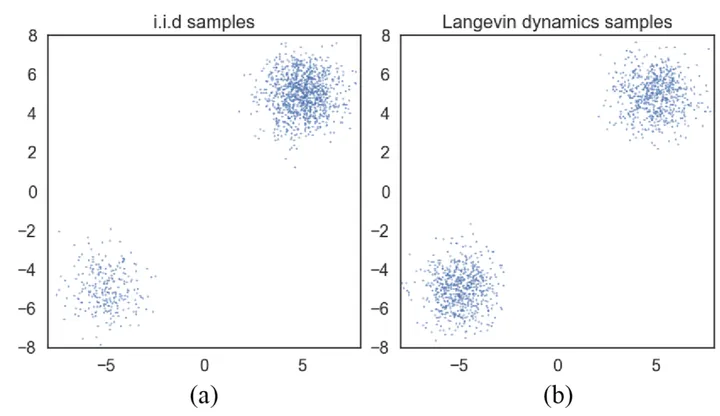
作者还发现,直接用朗之万采样会导致“忽视”数据分布比例的问题,从而让学到的分布和实际的分布可能不符。如上图所示,仍以双高斯混合分布为例,在实际的数据分布 (a) 中 ,右上部分的分布对应的样本比较多,左下部分的比较少;而生成的结果 (b) 确是两种分布对应的样本一样多,并没有反映出原始各分布之间的关系。这是因为朗之万采样过程中,在根据数据梯度“前进”时,选择向左下的高密度区域走还是向右上的高密度区域走,往往可能是随机的,这也是朗之万采样使用贪心思想的问题❓。
解决办法——Noise Conditional Score Networks (NCSN)
设计思路
为了解决上述问题,作者提出了升级版方法 —— Noise Conditional Score Networks (NCSN)& Annealed Langevin dynamics,其核心是用高斯噪声去扰动训练数据,然后估计不同噪声扰动下的数据分布的 score,并用于朗之万采样。这么做有什么好处呢?
对于第一个问题——“低数据区域 score 难以计算”:当用高斯噪声去扰动训练数据时,一方面,因为加的扰动噪声服从高斯分布,能够覆盖整个概率空间的,所以在一定程度上可以“弥补”原始训练集分布范围有限的问题,让其不至于被局限在一个低维流形上;另一方面,如果所加噪声足够大,也会让新产生的加噪数据集的分布中,原来低概率密度的区域被填充,从而能够提高该区域 score 估计的准确性。通过使用不同的噪声强度进行加噪,最终可以获得一系列噪声扰动的数据分布,它们将收敛到真实的数据分布。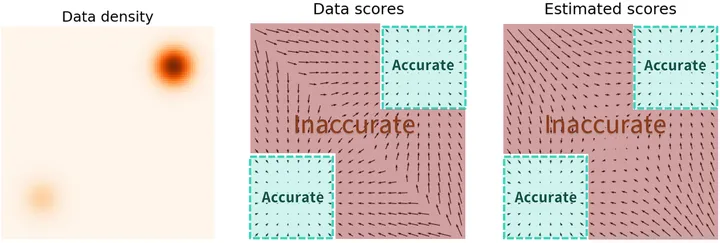

对于第二个问题——“忽视数据分布的比例”,在加噪扰动后,数据分布比例高的区域,被采样的概率也会增大,这也就意味着采样的时候更可能向比例高的分布接近,从而能够让生成模型的分布和原数据分布有相同的比例特性❓。
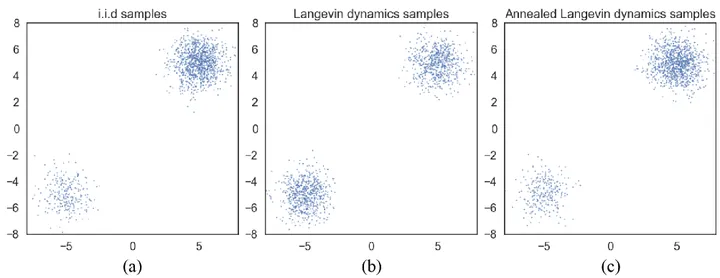
具体实现
具体实现中应该如何控制所加噪声的程度呢?噪声加的大,能有效“填充”概率密度低的区域,缓解 score 估计不准确的问题,但是这样同时也会导致加噪之后的数据分布严重偏离原始数据分布;反之,噪声加的小,虽然能够保持加噪前后数据分布的一致性,但是不能很好的“填充”低密度区域,解决前述存在的问题。

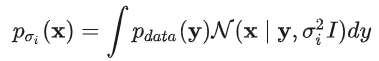



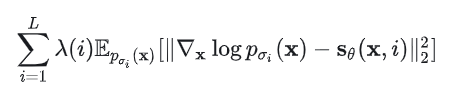

得到训练完成的 noise-conditional score-based model之后,就可以按照 i=L,L−1,…,1的递减次序,串联进行多轮不同噪声程度下的朗之万动力学采样,并最终生成新样本了。这种采样方法因为越往后,噪声越小(退火),所以也叫退火朗之万动力学采样(annealed Langevin dynamics)。
2 利用噪声尺度逐渐减小的退火朗之万采样,生成的样本逐渐落到目标分布区域(从右往左)
直观来看,按照噪声递减的顺序来采样是因为,一开始噪声先大一些,能够让数据先移动到高密度区域,之后噪声再小一些,可以让数据在高密度区域能更精准地移动到更加符合数据分布的位置。
总结一下退火朗之万动力学采样(annealed Langevin dynamics)的算法流程:

Trick
一些具体实现中的技巧

效果展示
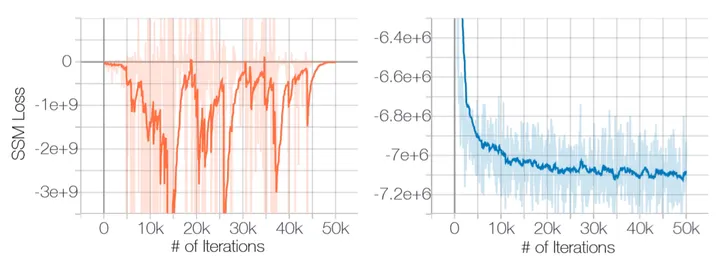
可以看到,原始的没有加噪声扰动的 sliced score matching 实际训练时容易出现 loss 不收敛的问题(下图左),而加噪声扰动之后,就能很好的收敛了(下图右)
基于退火朗之万采样,用 NCSN 生成新样本的示例:
3CelebA数据集
4CIFAR-10数据集
讨论
DDPM 和 NCSN 有什么区别?

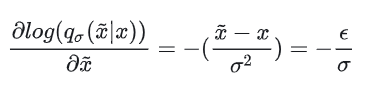
也就是说 score 的方向就是噪声ϵ的反方向,在采样生成时沿着 score 的方向走,就是往噪声的反方向走,这样就会走回原来数据样本的位置。所以 NCSN 也可以看成是一个去噪的过程。
宋飏在 ICLR 2021 上获得 Outstanding Paper Award 的论文“Score-based generative modeling through stochastic differential equations”从 SDE 的视角对 NCSN 和 DDPM 给出了更加完善的分析,证明了它们的内在统一性。
Appendix
naive score-based model 的 score matching objective 的化简与推导
进行如下变形,先打开括号:
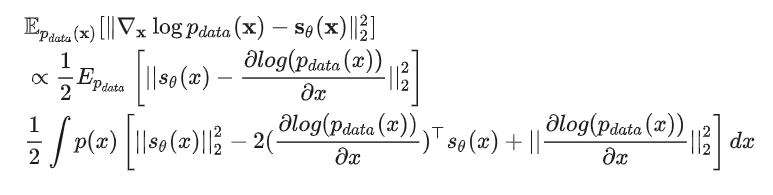

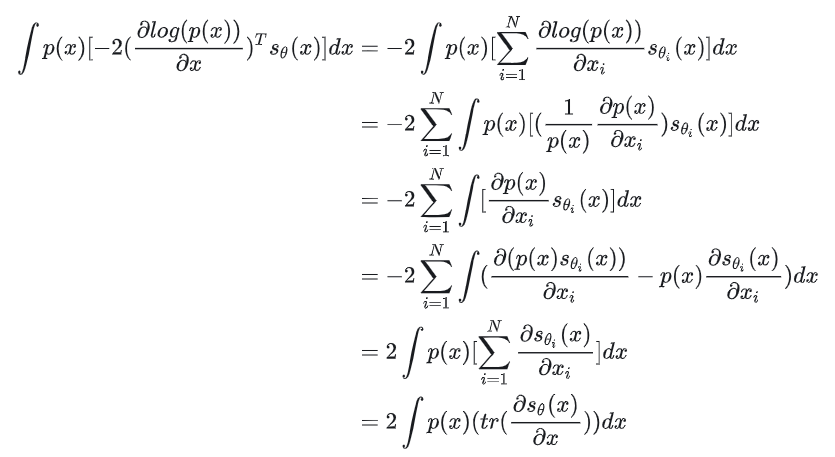
代入原式我们有:
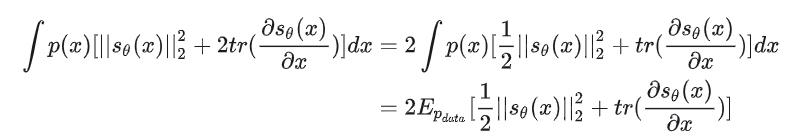
将之前的1/2代入就有我们变形过之后的目标函数:
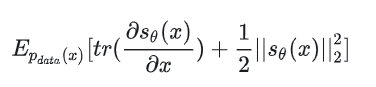
NCSN 的 score matching objective 的化简与推导
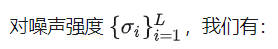
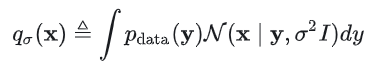
其中就是被加噪之后的数据分布,其对应的 score 函数即为:

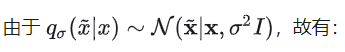
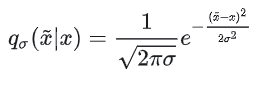
因此,我们可以计算偏导:
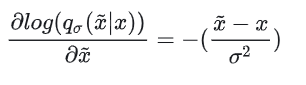
代入先前的目标函数得到:
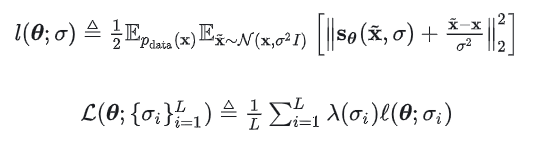
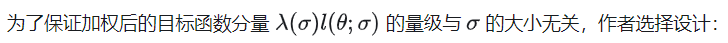
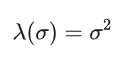

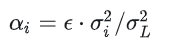
具体推导可以参考原论文。
Reference
Generative Modeling by Estimating Gradients of the Data Distribution(score-based model,NCSN) - 知乎
Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song
[^1]: Song, Y., & Ermon, S. (2019). Generative modeling by estimating gradients of the data distribution. Advances in Neural Information Processing Systems, 11895–11907.
[^2]: Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. In Advances in neural information processing systems, 2020.
[^3]: Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2021. Score-based generative modeling through stochastic differential equations. In International conference on learning representations, 2021.
[^4]: U. Grenander, M.I. Miller. 1994. Representations of knowledge in complex systems. Journal of the Royal Statistical Society: Series B (Methodological), Vol 56(4), pp. 549--581
[^5]: A. Hyvärinen. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(Apr):695–709, 2005.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2400人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


