
热门标签
热门文章
- 1飞企互联-FE企业运营管理平台uploadAttachmentServlet 任意文件上传漏洞_fe企业运营管理平台uploadattachmentservlet接口存在任意文件上传漏洞
- 2Linux内核中的常用宏container_of其实很简单_container_of(rt_se, struct task_struct, rt);
- 3Springboot2.0 实现进销存项目
- 4VMware Tools安装教程_vmware安装vmwaretools
- 5MSTP的原理以及实验_mstp中instance 10 vlan 10 100是什么意思
- 616 Android 数据库操作_apl怎么搜索类
- 7文献阅读(52)ICLR2021-Learnable Embedding Sizes for Recommender Systems
- 8Android Studio 如何连接第三方模拟器(如:雷电、MuMu)_android studio雷电模拟器调试
- 9Grafana通过监控nginx日志并配置监控大盘_grafna 监控nginx日志
- 10一文理解UART通信_uart协议的usb接口到底是usb通讯还是uart通讯?
当前位置: article > 正文
DeepFake终于要被打败!伯克利AI识别系统入门_akaros 操作系统
作者:Gausst松鼠会 | 2024-04-05 01:06:55
赞
踩
akaros 操作系统
本文存在的目的是更快速的提炼一些关于DeepFake的关键点,带你了解DeepFake。
1 关键点总结
- DeepFake假视频的泛滥早已经不只是恶搞和娱乐的问题了!这场斗法已经成为一场维护新闻真实性、甚至是关乎国家安全的一场军备竞赛。
- 刚开始的Deepfake生成的视频假视频有任务从不眨眼的缺陷,但是很快得到改善。
- 总而言之,deepfake的进步是非常快的,这可能是一个旷日持久的对抗。
2 目前先进的验证方法
- 前提假设:人说话的时候, 会做出不同的面部表情和动作
- 假设有一个视频,跟踪面部和头部运动,然后检测并提取特定动作单元的存在性和强度,来构建一个能够区分真假视频的模
- 通俗易懂的原理:不同的人在说话时会表现出相对不同的面部和头部运动模式。而Deepfake假视频往往会破坏这些模式,因为假视频中的这些模式的表达由模仿算法控制,可能导致嘴巴与脸部的其他部分不自然的分离。
举一个例子
上面所示是来自250帧剪辑片段中的五个等距帧,显示了对OpenFace的跟踪结果。下半部分为此视频剪辑上测量的一个动作单元AU01(眉毛抬起)的程度。
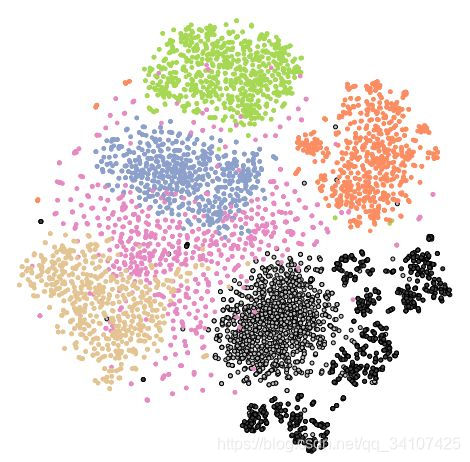
希拉里·克林顿(棕色),巴拉克·奥巴马(浅灰色带框),伯尼·桑德斯(绿色),唐纳德·特朗普(橙色),伊丽莎白·沃伦(蓝色)的190-D特征的二维可视化),随机任务(粉色),以及奥巴马的Deepfake假视频(深灰色带框)
可以发现每一个人的基本都是一个聚类
实验结果:总体识别率超过95%
3 局限性
本文提出的方法与现有的基于像素的检测方法相比,可以更好地抵御图像压缩的影响。不过我们也发现,**本方法的适用性容易受到人们说话的不同背景的影响(直面镜头正式讲话,与不看镜头的现场采访)。**我们建议通过以下两种方式来应对。
- 在各种多样化环境中收集更大、更多样化的视频集,或者构建几位名人基于特定环境下的讲话模型。
- 除了这种背景环境效应之外,我们发现当演讲人始终远离镜头时,动作单元的可靠性可能会受到严重影响。为了解决这些局限性,建议通过语言分析来增强模型性能,更好地捕获所说内容与说法方式之间的相关性。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/362342
推荐阅读
相关标签

