
- 1数据库系统概论--课后习题_数据库系统概念题目 csdn
- 2SpringBoot和Maven版本对应关系_maven与springboot的对应版本
- 3EDA工具:基础知识及重要应用_eda工具大致可以分为哪几个模块?各模块的主要功能是什么?
- 4基于FPGA的一维卷积神经网络算法实现(1D-CNN、BNN的FPGA加速实现)_fpga 神经网络bn层
- 5git 修改远程仓库地址,用户名,地址_git remote修改
- 6【数据结构】树与二叉树、树与森林部分习题与算法设计例题
- 7IDEA忽略文件,防止git提交不想提交的文件_idea忽略文件不提交git
- 8基于arcpro3.0.2版的使用深度学习检测对象之椰子树
- 9百钱买百鸡
- 10什么是阿里ACP认证,ACP怎么考?
中文医疗领域自然语言处理相关数据集、经典论文资源蒸馏分享_clinicalbert
赞
踩
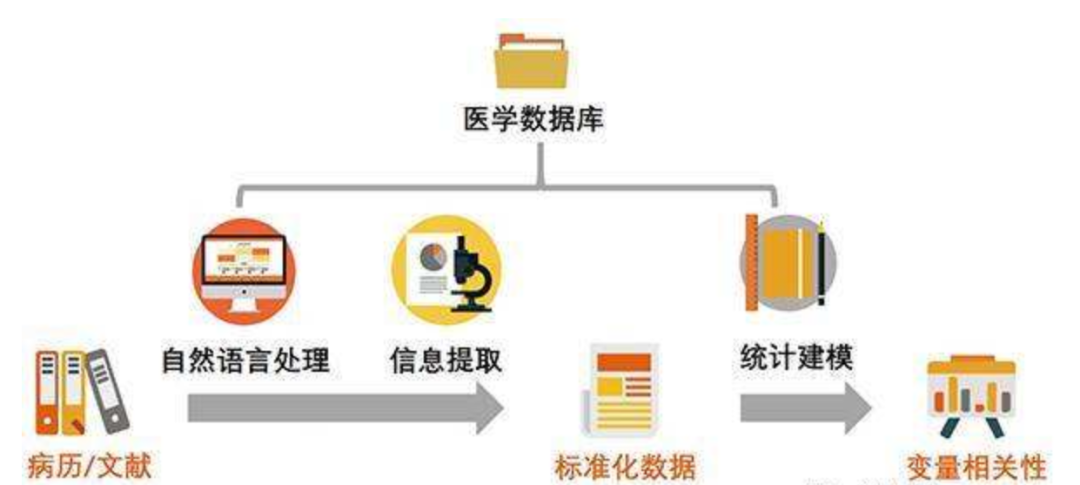
在医疗领域,一些应用已经从科幻小说变为现实。人工智能系统通过了中国和英国的医学执照考试 ,而且它们比普通医生考得更好。最新的系统比初级医生能更好地诊断出55种儿科疾病。但是,这些系统比第一批计算机视觉深度学习应用(例如研究一个图像)中的一些更难构建,因为它们需要具有更广泛常见的医学知识,要处理更多种类的输入,并且必须理解上下文。
最近几年随着自然语言处理技术的发展,医疗领域的NLP技术也有非常大进步。本资源主要整理医疗中文自然语言处理相关的评测数据集、论文等相关资源,分享给大家。
资源整理自网络,源地址:
https://github.com/lrs1353281004/Chinese_medical_NLP
资源目录

中文评测数据集
1. Yidu-S4K:医渡云结构化4K数据集
数据集描述:
Yidu-S4K 数据集源自CCKS 2019 评测任务一,即“面向中文电子病历的命名实体识别”的数据集,包括两个子任务:1)医疗命名实体识别:由于国内没有公开可获得的面向中文电子病历医疗实体识别数据集,本年度保留了医疗命名实体识别任务,对2017年度数据集做了修订,并随任务一同发布。本子任务的数据集包括训练集和测试集。2)医疗实体及属性抽取(跨院迁移):在医疗实体识别的基础上,对预定义实体属性进行抽取。本任务为迁移学习任务,即在只提供目标场景少量标注数据的情况下,通过其他场景的标注数据及非标注数据进行目标场景的识别任务。本子任务的数据集包括训练集(非目标场景和目标场景的标注数据、各个场景的非标注数据)和测试集(目标场景的标注数据
2.瑞金医院糖尿病数据集
数据集描述:
数据集来自天池大赛。此数据集旨在通过糖尿病相关的教科书、研究论文来做糖尿病文献挖掘并构建糖尿病知识图谱。参赛选手需要设计高准确率,高效的算法来挑战这一科学难题。第一赛季课题为“基于糖尿病临床指南和研究论文的实体标注构建”,第二赛季课题为“基于糖尿病临床指南和研究论文的实体间关系构建”。
官方提供的数据只包含训练集,真正用于最终排名的测试集没有给出。
3.Yidu-N7K:医渡云标准化7K数据集
数据集描述:
Yidu-N4K 数据集源自CHIP 2019 评测任务一,即“临床术语标准化任务”的数据集。临床术语标准化任务是医学统计中不可或缺的一项任务。临床上,关于同一种诊断、手术、药品、检查、化验、症状等往往会有成百上千种不同的写法。标准化(归一)要解决的问题就是为临床上各种不同说法找到对应的标准说法。有了术语标准化的基础,研究人员才可对电子病历进行后续的统计分析。本质上,临床术语标准化任务也是语义相似度匹配任务的一种。但是由于原词表述方式过于多样,单一的匹配模型很难获得很好的效果。
4.中文医学问答数据集
数据集描述:
中文医药方面的问答数据集,超过10万条。
数据说明:
questions.csv:所有的问题及其内容。answers.csv :所有问题的答案。train_candidates.txt, dev_candidates.txt, test_candidates.txt :将上述两个文件进行了拆分。
5.平安医疗科技疾病问答迁移学习比赛
数据集描述:
本次比赛是chip2019中的评测任务二,由平安医疗科技主办。chip2019会议详情见链接:http://cips-chip.org.cn/evaluation 迁移学习是自然语言处理中的重要一环,其主要目的是通过从已学习的相关任务中转移知识来改进新任务的学习效果,从而提高模型的泛化能力。本次评测任务的主要目标是针对中文的疾病问答数据,进行病种间的迁移学习。具体而言,给定来自5个不同病种的问句对,要求判定两个句子语义是否相同或者相近。所有语料来自互联网上患者真实的问题,并经过了筛选和人工的意图匹配标注。
6.天池新冠肺炎问句匹配比赛
数据集描述:
本次大赛数据包括:脱敏之后的医疗问题数据对和标注数据。医疗问题涉及“肺炎”、“支原体肺炎”、“支气管炎”、“上呼吸道感染”、“肺结核”、“哮喘”、“胸膜炎”、“肺气肿”、“感冒”、“咳血”等10个病种。数据共包含train.csv、dev.csv、test.csv三个文件,其中给参赛选手的文件包含训练集train.csv和验证集dev.csv,测试集test.csv 对参赛选手不可见。每一条数据由 Category,Query1,Query2,Label构成,分别表示问题类别、问句1、问句2、标签。Label表示问句之间的语义是否相同,若相同,标为1,若不相同,标为0。其中,训练集Label已知,验证集和测试集Label未知。示例 类别:肺炎 问句1:肺部发炎是什么原因引起的?问句2:肺部发炎是什么引起的 标签:1 类别:肺炎 问句1:肺部发炎是什么原因引起的?问句2:肺部炎症有什么症状 标签:0
7.中文医患问答对话数据
数据说明: 来自某在线求医产品的中文医患对话数据。
原始描述:The MedDialog dataset contains conversations (in Chinese) between doctors and patients. It has 1.1 million dialogues and 4 million utterances. The data is continuously growing and more dialogues will be added. The raw dialogues are from haodf.com. All copyrights of the data belong to haodf.com.
8.中文医学问答数据
数据说明: 包含六个科室的医学问答数据,来源不明。
中文医学知识图谱
CMeKG
地址
简介:CMeKG(Chinese Medical Knowledge Graph)是利用自然语言处理与文本挖掘技术,基于大规模医学文本数据,以人机结合的方式研发的中文医学知识图谱。CMeKG的构建参考了ICD、ATC、SNOMED、MeSH等权威的国际医学标准以及规模庞大、多源异构的临床指南、行业标准、诊疗规范与医学百科等医学文本信息。CMeKG 1.0包括:6310种疾病、19853种药物(西药、中成药、中草药)、1237种诊疗技术及设备的结构化知识描述,涵盖疾病的临床症状、发病部位、药物治疗、手术治疗、鉴别诊断、影像学检查、高危因素、传播途径、多发群体、就诊科室等以及药物的成分、适应症、用法用量、有效期、禁忌证等30余种常见关系类型,CMeKG描述的概念关系实例及属性三元组达100余万。
英文数据集
PubMedQA: A Dataset for Biomedical Research Question Answering
数据集描述:基于Pubmed提取的医学问答数据集。PubMedQA has 1k expert-annotated, 61.2k unlabeled and 211.3k artificially gen- erated QA instances.
相关论文
1.医疗领域预训练embedding
注:目前没有收集到中文医疗领域的开源预训练模型,以下列出英文论文供参考。
Bio-bert
论文题目:BioBERT: a pre-trained biomedical language representation model for biomedical text mining
论文概要:以通用领域预训练bert为初始权重,基于Pubmed上大量医疗领域英文论文训练。在多个医疗相关下游任务中超越SOTA模型的表现。
sci-bert
论文题目:SCIBERT: A Pretrained Language Model for Scientific Text
论文概要:AllenAI 团队出品.基于Semantic Scholar 上 110万+ 文章训练的 科学领域bert.
clinical-bert
论文题目:Publicly Available Clinical BERT Embeddings
项目地址
论文概要:出自NAACL Clinical NLP Workshop 2019.基于MIMIC-III数据库中的200万份医疗记录训练的临床领域bert.
clinical-bert(另一团队的版本)
论文题目:ClinicalBert: Modeling Clinical Notes and Predicting Hospital Readmission
项目地址
论文概要:同样基于MIMIC-III数据库,但只随机选取了10万份医疗记录训练的临床领域bert.
BEHRT
论文题目:BEHRT: TRANSFORMER FOR ELECTRONIC HEALTH RECORDS
论文概要:这篇论文中embedding是基于医学实体训练,而不是基于单词。
2.综述类文章
nature medicine发表的综述
论文题目:A guide to deep learning in healthcare
论文概要:发表于nature medicine,包含医学领域下CV,NLP,强化学习等方面的应用综述。
3.电子病历相关文章
Transfer Learning from Medical Literature for Section Prediction in Electronic Health Records
论文概要:发表于EMNLP2019。基于少量in-domain数据和大量out-of-domain数据进行EHR相关的迁移学习。
4.医学关系抽取
Leveraging Dependency Forest for Neural Medical Relation Extraction
论文概要:发表于EMNLP 2019. 基于dependency forest方法,提升对医学语句中依存关系的召回率,同时引进了一部分噪声,基于图循环网络进行特征提取,提供了在医疗关系抽取中使用依存关系,同时减少误差传递的一种思路。
5.医学知识图谱
Learning a Health Knowledge Graph from Electronic Medical Records
论文概要:发表于nature scientificreports(2017). 基于27万余份电子病历构建的疾病-症状知识图谱。
6.辅助诊断
Evaluation and accurate diagnoses of pediatric diseases using artificial intelligence
论文概要:该文章由广州市妇女儿童医疗中心与依图医疗等企业和科研机构共同完成,基于机器学习的自然语言处理(NLP)技术实现不输人类医生的强大诊断能力,并具备多场景的应用能力。据介绍,这是全球首次在顶级医学杂志发表有关自然语言处理(NLP)技术基于电子健康记录(EHR)做临床智能诊断的研究成果,也是利用人工智能技术诊断儿科疾病的重磅科研成果。
7.ACL2020医学领域相关论文列表
A Generate-and-Rank Framework with Semantic Type Regularization for Biomedical Concept Normalization
Biomedical Entity Representations with Synonym Marginalization
Document Translation vs. Query Translation for Cross-Lingual Information Retrieval in the Medical Domain
MIE: A Medical Information Extractor towards Medical Dialogues
Rationalizing Medical Relation Prediction from Corpus-level Statistics
8.医疗实体Linking(标准化)
Medical Entity Linking using Triplet Network
论文概要:发表于ACL2019,论文内容为疾病实体Linking研究。使用三元组数据,(mention,正例,负例),目标使distance(mention,负例)-distance(mention,正例)>alpha(人脸识别的经典方案),具体损失函数参看论文。论文主要包括两部分内容1)候选数据集生成,对给定mention,与标准疾病集合数据(标准词及同义词)计算余弦相似度及Jaccard overlap分数,取topK作为候选样例。2)网络结构基于Triplet Network。详见论文。
A Generate-and-Rank Framework with Semantic Type Regularization for Biomedical Concept Normalization
论文概要: 发表于ACL2020。基于list-wise排序学习方法。主要分为两部分:后续数据集生成 和 基于BERT的list-wise排序。较新颖的思路:1)在样本生成过程中,对标准词进行了基于同义词的扩展。2)在loss中引入了语义类型正则化。详见论文。
9. AAAI2020 医学NLP相关论文列表
On the Generation of Medical Question-Answer Pairs
LATTE: Latent Type Modeling for Biomedical Entity Linking
Learning Conceptual-Contextual Embeddings for Medical Text
Understanding Medical Conversations with Scattered Keyword Attention and Weak Supervision from Responses
Simultaneously Linking Entities and Extracting Relations from Biomedical Text without Mention-level Supervision
Can Embeddings Adequately Represent Medical Terminology? New Large-Scale Medical Term Similarity Datasets Have the Answer!
中文医疗领域语料
医学教材+培训考试
说明:由于版权原因,现在无法提供度盘下载链接了,请大家前往原豆瓣链接下载吧。
语料说明:根据此豆瓣链接整理。
数据预览:

哈工大《大词林》开放75万核心实体词及相关概念、关系列表(包含中药/医院/生物 类别)
语料说明:哈工大开源了《大词林》中的75万的核心实体词,以及这些核心实体词对应的细粒度概念词(共1.8万概念词,300万实体-概念元组),还有相关的关系三元组(共300万)。这75万核心实体列表涵盖了常见的人名、地名、物品名等术语。概念词列表则包含了细粒度的实体概念信息。借助于细粒度的上位概念层次结构和丰富的实体间关系,本次开源的数据能够为人机对话、智能推荐、等应用技术提供数据支持。
说明: 通过网上查询,这部分资源应该是被一些公司付费使用了,可能有版权问题,所以现在下载链接都失效了。后续如果再有开源的信息再进行更新。
医学embedding
开源英文医学embedding
项目说明:发表于AMIA 2016. 开源医学相关概念embedding.
开源工具包
分词工具
PKUSEG
项目说明:北京大学推出的多领域中文分词工具,支持选择医学领域。
工业级产品解决方案
灵医智慧
左手医生
blog分享
医疗领域构建自然语言处理系统的经验教训

