
热门标签
热门文章
- 1DA-2-Unsupervised Multi-source Domain Adaptation Without Access to Source Data
- 213 双口 RAM IP 核_pipeline stages within mux
- 3网络安全(黑客)—-2024自学手册
- 4云和恩墨首次亮相SIGMOD大会,数据库研发负责人张皖川详解MogDB
- 51.Redis的缓存策略
- 6.Net Core下自定义JsonResult_net core jsonresult
- 7(三)小程序样式和组件
- 8关于android开发的一些基础知识_安卓开发基础知识
- 9如何查看CSDN积分_csdn的积分在哪里看
- 10Git 合并多次 commit 、 删除某次 commit_合并多次commit
当前位置: article > 正文
【Spark编程基础】实验5 Spark Structured Streaming编程实践
作者:Gausst松鼠会 | 2024-05-19 12:19:07
赞
踩
spark structured streaming编程实践
实验5 Spark Structured Streaming编程实践
实验内容和要求
0.结构化流练习任务
0.1 讲义文件源-json数据任务。按照讲义中json数据的生成及分析,复现实验,并适当分析。
- (1)创建程序生成JSON格式的File源测试数据
- (讲义1000个,本实验只生成200个)
import os import shutil import random import time TEST_DATA_TEMP_DIR = '/tmp/' TEST_DATA_DIR = '/tmp/testdata/' ACTION_DEF = ['login', 'logout', 'purchase'] DISTRICT_DEF = ['fujian', 'beijing', 'shanghai', 'guangzhou'] JSON_LINE_PATTERN = '{{"eventTime": {}, "action": "{}", "district": "{}"}}\n‘ # 测试的环境搭建,判断文件夹是否存在,如果存在则删除旧数据,并建立文件夹 def test_setUp(): if os.path.exists(TEST_DATA_DIR): shutil.rmtree(TEST_DATA_DIR, ignore_errors=True) os.mkdir(TEST_DATA_DIR) # 测试环境的恢复,对文件夹进行清理 def test_tearDown(): if os.path.exists(TEST_DATA_DIR): shutil.rmtree(TEST_DATA_DIR, ignore_errors=True) # 生成测试文件 def write_and_move(filename, data): with open(TEST_DATA_TEMP_DIR + filename, "wt", encoding="utf-8") as f: f.write(data) shutil.move(TEST_DATA_TEMP_DIR + filename, TEST_DATA_DIR + filename) if __name__ == "__main__": test_setUp() # 这里生成200个文件 for i in range(200): filename = 'e-mall-{}.json'.format(i) content = '' rndcount = list(range(100)) random.shuffle(rndcount) for _ in rndcount: content += JSON_LINE_PATTERN.format( str(int(time.time())), random.choice(ACTION_DEF), random .choice(DISTRICT_DEF)) write_and_move(filename, content) time.sleep(1)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
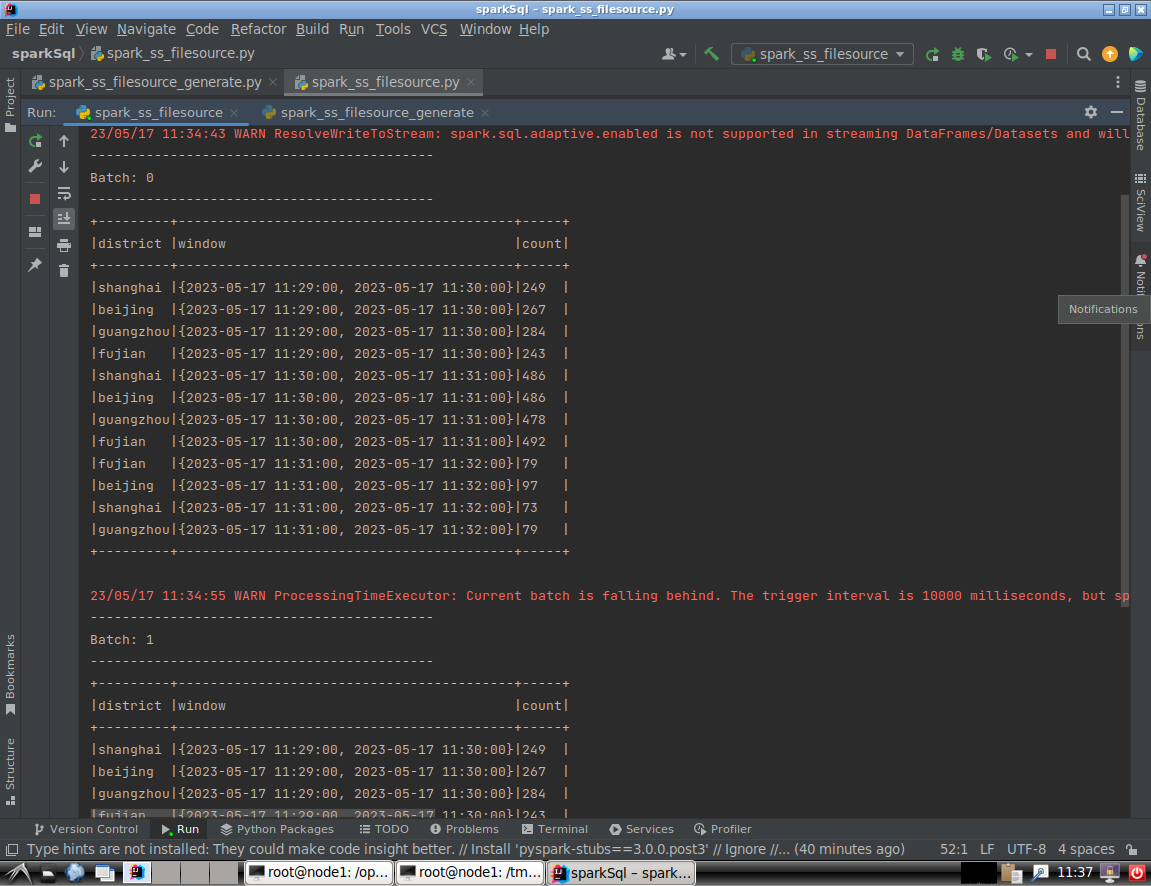
- (2)创建程序对数据进行统计
# 导入需要用到的模块 import os import shutil from pprint import pprint from pyspark.sql import SparkSession from pyspark.sql.functions import window, asc from pyspark.sql.types import StructType, StructField from pyspark.sql.types import TimestampType, StringType # 定义JSON文件的路径常量(此为本地路径) TEST_DATA_DIR_SPARK = '/tmp/testdata/' if __name__ == "__main__": # 定义模式,为时间戳类型的eventTime、字符串类型的操作和省份组成 schema = StructType([ StructField("eventTime", TimestampType(), True), StructField("action", StringType(), True), StructField("district", StringType(), True)]) spark = SparkSession \ .builder \ .appName("StructuredEMallPurchaseCount") \ .getOrCreate() spark.sparkContext.setLogLevel('WARN') lines = spark \ .readStream \ .format("json") \ .schema(schema) \ .option("maxFilesPerTrigger", 100) \ .load(TEST_DATA_DIR_SPARK) # 定义窗口 windowDuration = '1 minutes' windowedCounts = lines \ .filter("action = 'purchase'") \ .groupBy('district', window('eventTime', windowDuration)) \ .count() \ .sort(asc('window')) query = windowedCounts \ .writeStream \ .outputMode("complete") \ .format("console") \ .option('truncate', 'false') \ .trigger(processingTime="10 seconds") \ .start() query.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- (3)测试运行程序
0.2 讲义kafka源,2字母单词分析任务按照讲义要求,复现kafka源实验。
-
- 安装kafka
- 下载安装zookeeper(新版kafka自带)
- 下载地址:https://archive.apache.org/dist/zookeeper/
- 安装路径:/usr/lcoal/zookeeper
- 下载安装kafka
- 下载地址:https://kafka.apache.org/downloads
- 解压安装路径:/usr/local/kafka
- (idea运行大概率会报错,解决方法:)在idea终端执行命令:pip install python-kafka
-
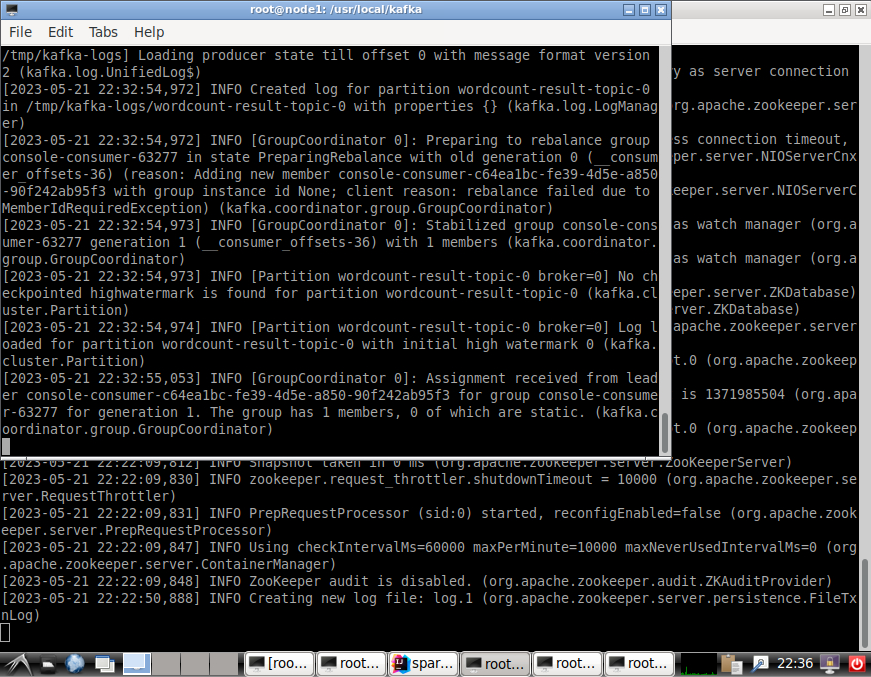
- 启动Kafka
- 在Linux系统中新建一个终端(记作“Zookeeper终端”),输入下面命令启动Zookeeper服务:
cd /usr/local/kafka./bin/zookeeper-server-start.sh config/zookeeper.properties
- 新建第二个终端(记作“Kafka终端”),然后输入下面命令启动Kafka服务:
cd /usr/local/kafka./bin/kafka-server-start.sh config/server.properties
- 新建第三个终端(记作“监控输入终端”),执行如下命令监控Kafka收到的文本:
cd /usr/local/kafka./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wordcount-topic
- 新建第四个终端(记作“监控输出终端”),执行如下命令监控输出的结果文本:
cd /usr/local/kafka./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wordcount-result-topic
-
- 编写生产者(Producer)程序
# spark_ss_kafka_producer.py import string import random import time from kafka import KafkaProducer if __name__ == "__main__": producer = KafkaProducer(bootstrap_servers=['localhost:9092']) while True: s2 = (random.choice(string.ascii_lowercase) for _ in range(2)) word = ''.join(s2) value = bytearray(word, 'utf-8') producer.send('wordcount-topic', value=value) \ .get(timeout=10) time.sleep(0.1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
- 编写消费者(Consumer)程序
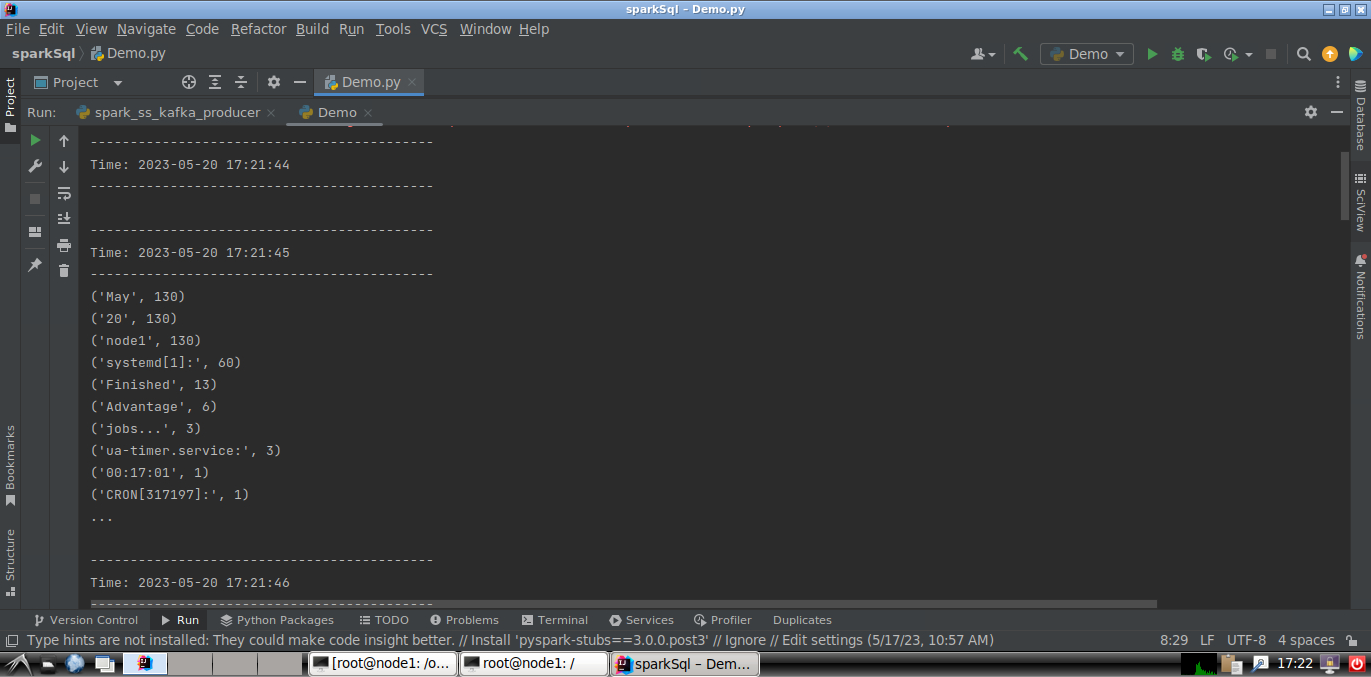
# spark_ss_kafka_consumer.py from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession \ .builder \ .appName("StructuredKafkaWordCount") \ .getOrCreate() spark.sparkContext.setLogLevel('WARN') lines = spark \ .readStream \ .format("kafka") \ .option("kafka.bootstrap.servers", "localhost:9092") \ .option("subscribe", 'wordcount-topic') \ .load() \ .selectExpr("CAST(value AS STRING)") wordCounts = lines.groupBy("value").count() query = wordCounts \ .selectExpr("CAST(value AS STRING) as key", "CONCAT(CAST(value AS STRING), ':', CAST(count AS STRING)) as value") \ .writeStream \ .outputMode("complete") \ .format("kafka") \ .option("kafka.bootstrap.servers", "localhost:9092") \ .option("topic", "wordcount-result-topic") \ .option("checkpointLocation", "file:///tmp/kafka-sink-cp") \ .trigger(processingTime="8 seconds") \ .start() query.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 在终端中执行运行消费者程序:

0.3 讲义socket源,结构化流实现词频统计。按照讲义要求,复现socket源实验。
- 编写文件:StructuredNetworkWordCount.py:
# StructuredNetworkWordCount.py # 步骤1:导入pyspark模块 from pyspark.sql import SparkSession from pyspark.sql.functions import split from pyspark.sql.functions import explode # 步骤2:创建SparkSession对象 # 创建一个SparkSession对象,代码如下: if __name__ == "__main__": spark = SparkSession \ .builder \ .appName("StructuredNetworkWordCount") \ .getOrCreate() spark.sparkContext.setLogLevel('WARN') # 步骤3:创建输入数据源 # 创建一个输入数据源,从“监听在本机(localhost)的9999端口上的服务”那里接收文本数据,具体语句如下: lines = spark \ .readStream \ .format("socket") \ .option("host", "localhost") \ .option("port", 9999) \ .load() # 步骤4:定义流计算过程 # 有了输入数据源以后,接着需要定义相关的查询语句,具体如下: words = lines.select( explode( split(lines.value, " ") ).alias("word") ) wordCounts = words.groupBy("word").count() # 步骤5:启动流计算并输出结果 # 定义完查询语句后,下面就可以开始真正执行流计算,具体语句如下: query = wordCounts \ .writeStream \ .outputMode("complete") \ .format("console") \ .trigger(processingTime="8 seconds") \ .start() query.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 启动hadoop:
cd /opt/module/hadoop./sbin/start-dfs.sh
- 新建一个终端(记作“数据源终端”):
nc -lk 9999
- 再新建一个终端(记作“流计算终端”)【idea运行会强制退出 ( - _ - !) _】:
- cd ~/IdeaProjects/sparkSql/
- /opt/module/spark/bin/spark-submit StructuredNetworkWordCount.py
- 在“数据源终端”内用键盘不断敲入一行行英文语句:
0.4(不选)使用rate源,评估系统性能。
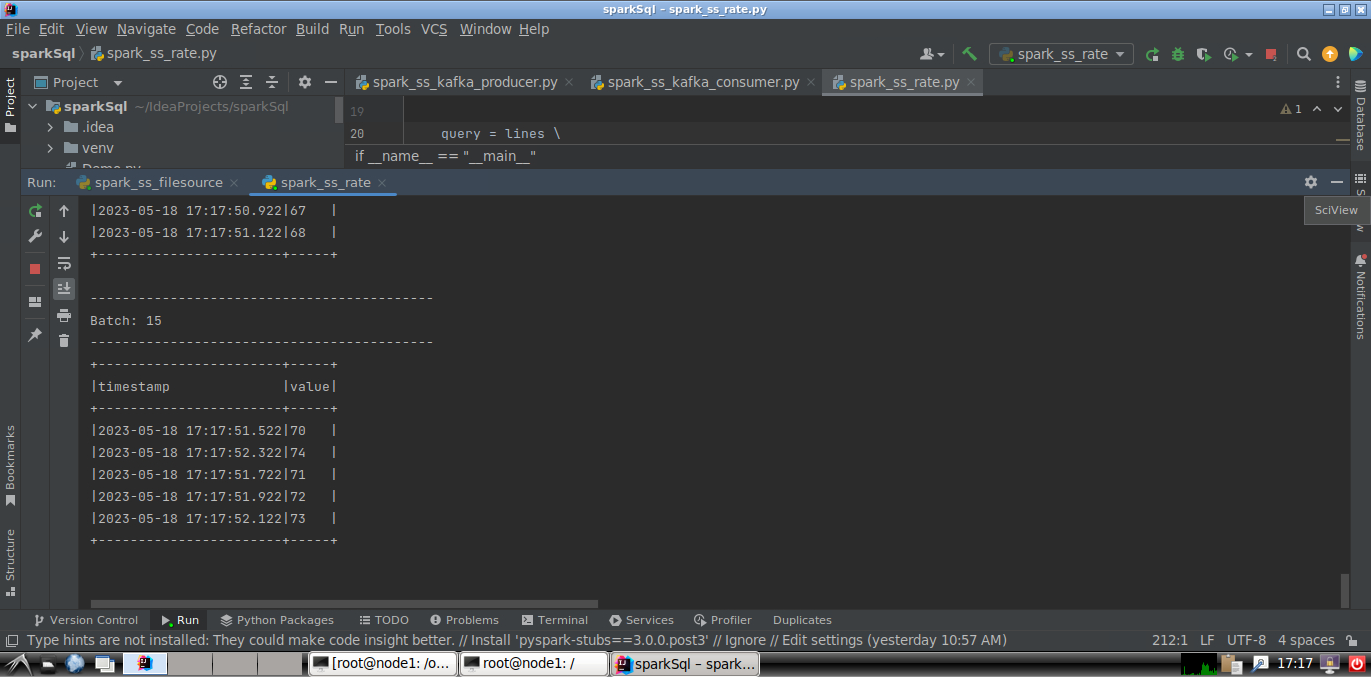
- 代码文件spark_ss_rate.py
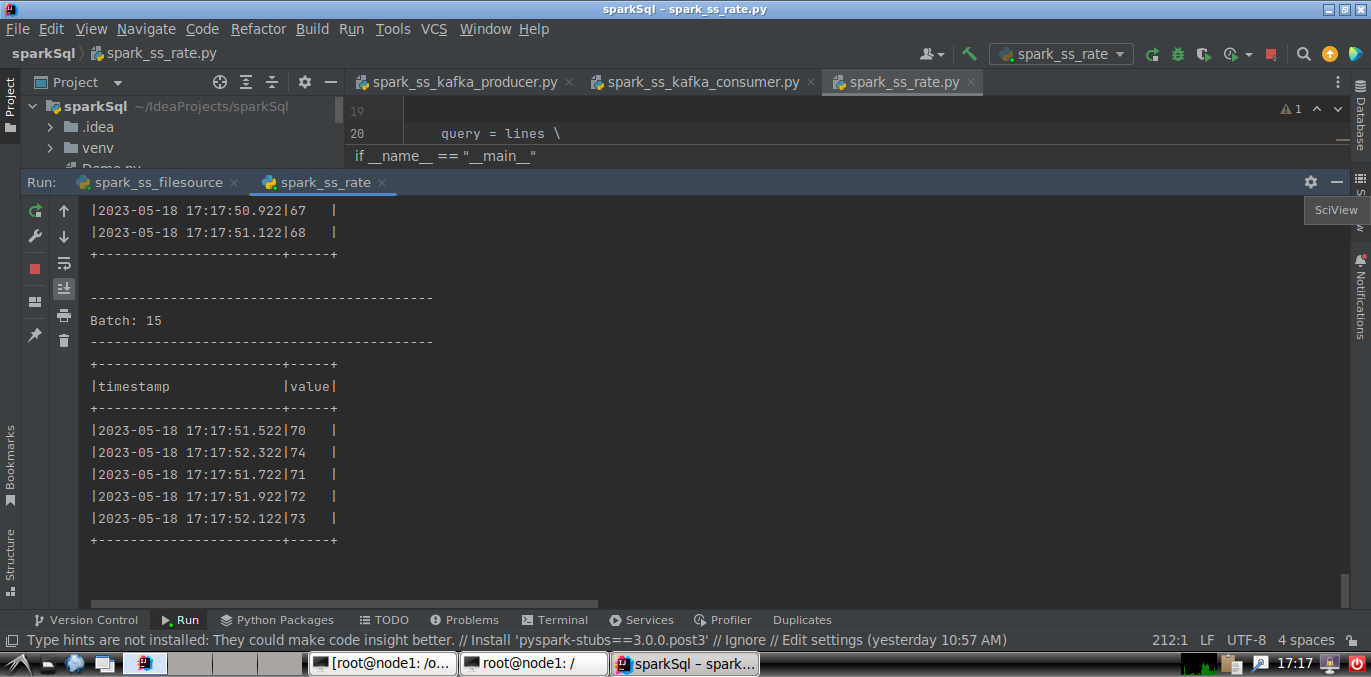
# spark_ss_rate.py from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession \ .builder \ .appName("TestRateStreamSource") \ .getOrCreate() spark.sparkContext.setLogLevel('WARN') lines = spark \ .readStream \ .format("rate") \ .option('rowsPerSecond', 5) \ .load() print(lines.schema) query = lines \ .writeStream \ .outputMode("update") \ .format("console") \ .option('truncate', 'false') \ .start() query.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 在Linux终端中执行spark_ss_rate.py
1.日志分析任务
1.1通过Socket传送Syslog到Spark日志分析是一个大数据分析中较为常见的场景。
- 实验原理:
- 在Unix类操作系统里,Syslog广泛被应用于系统或者应用的日志记录中。
- Syslog通常被记录在本地文件内,比如Ubuntu内为/var/log/syslog文件名,也可以被发送给远程Syslog服务器。
- Syslog日志内一般包括产生日志的时间、主机名、程序模块、进程名、进程ID、严重性和日志内容。
- 日志一般会通过Kafka等有容错保障的源发送,本实验为了简化,直接将Syslog通过Socket源发送。
- 实验过程:
- 新建一个终端,执行如下命令:
tail -n+1 -f /var/log/syslog | nc -lk 9988“tail -n+1 -f /var/log/syslog”- 表示从第一行开始打印文件syslog的内容
- “-f”表示如果文件有增加则持续输出最新的内容。
- 然后,通过管道把文件内容发送到nc程序(nc程序可以进一步把数据发送给Spark)。
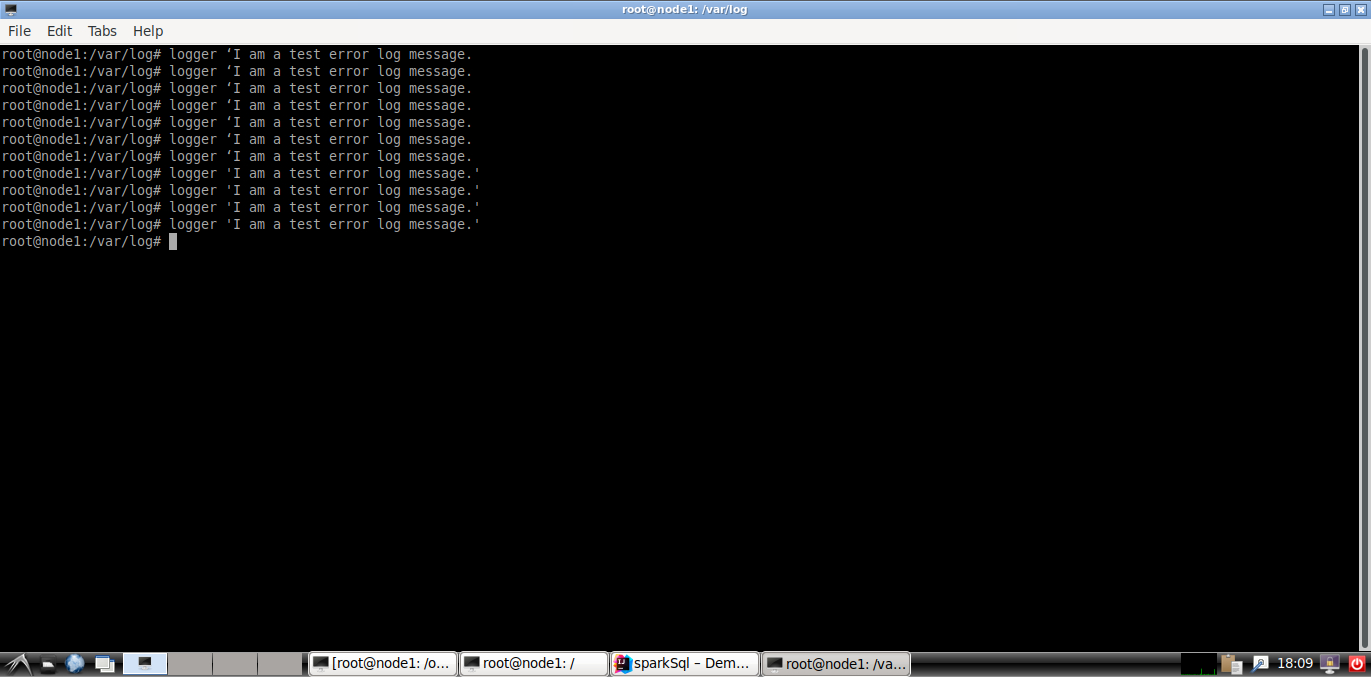
- 如果/var/log/syslog内的内容增长速度较慢,可以再新开一个终端(计作“手动发送日志终端”),手动在终端输入如下内容来增加日志信息到/var/log/syslog内:
logger ‘I am a test error log message.
from pyspark import SparkContext from pyspark.streaming import StreamingContext # 创建SparkContext和StreamingContext sc = SparkContext(appName="SyslogAnalysis") ssc = StreamingContext(sc, 1) # 创建一个DStream,接收来自Socket的数据流 lines = ssc.socketTextStream("localhost", 9988) # 在数据流上应用转换和操作 word_counts = lines.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda x, y: x + y) # 输出结果到控制台 word_counts.pprint() # 启动StreamingContext ssc.start() ssc.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
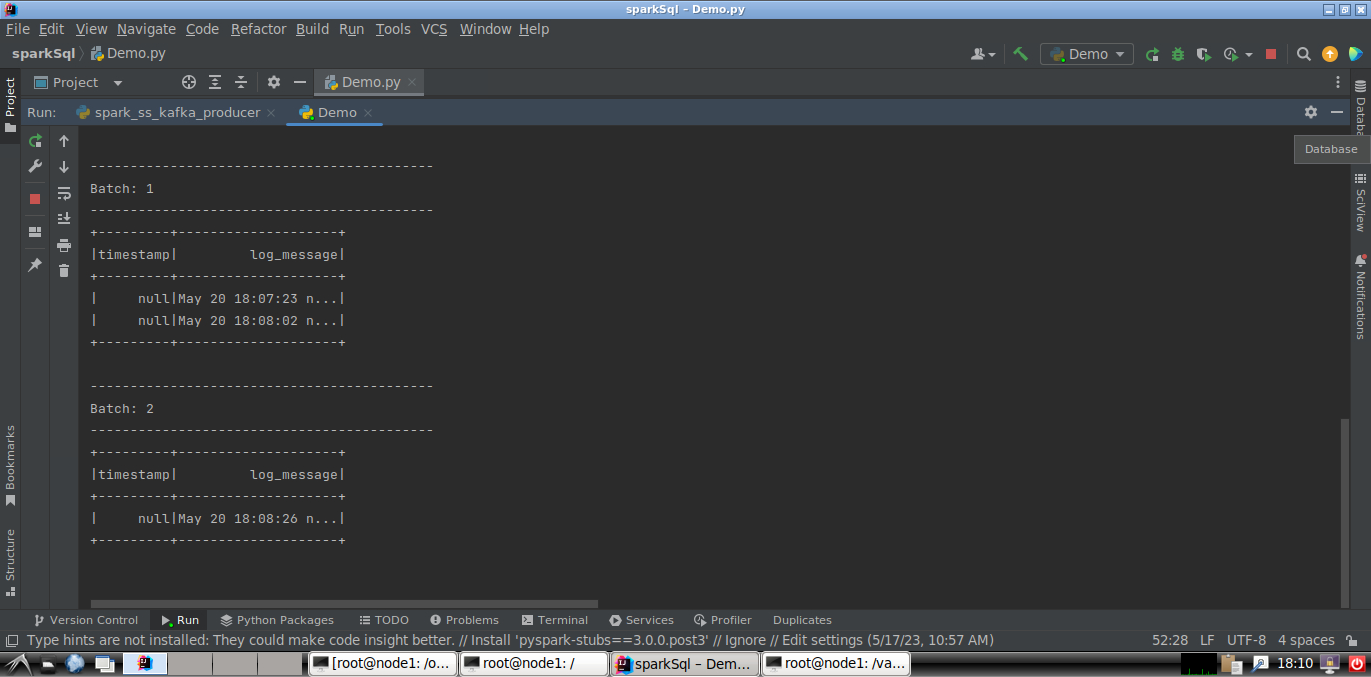
1.2对Syslog进行查询
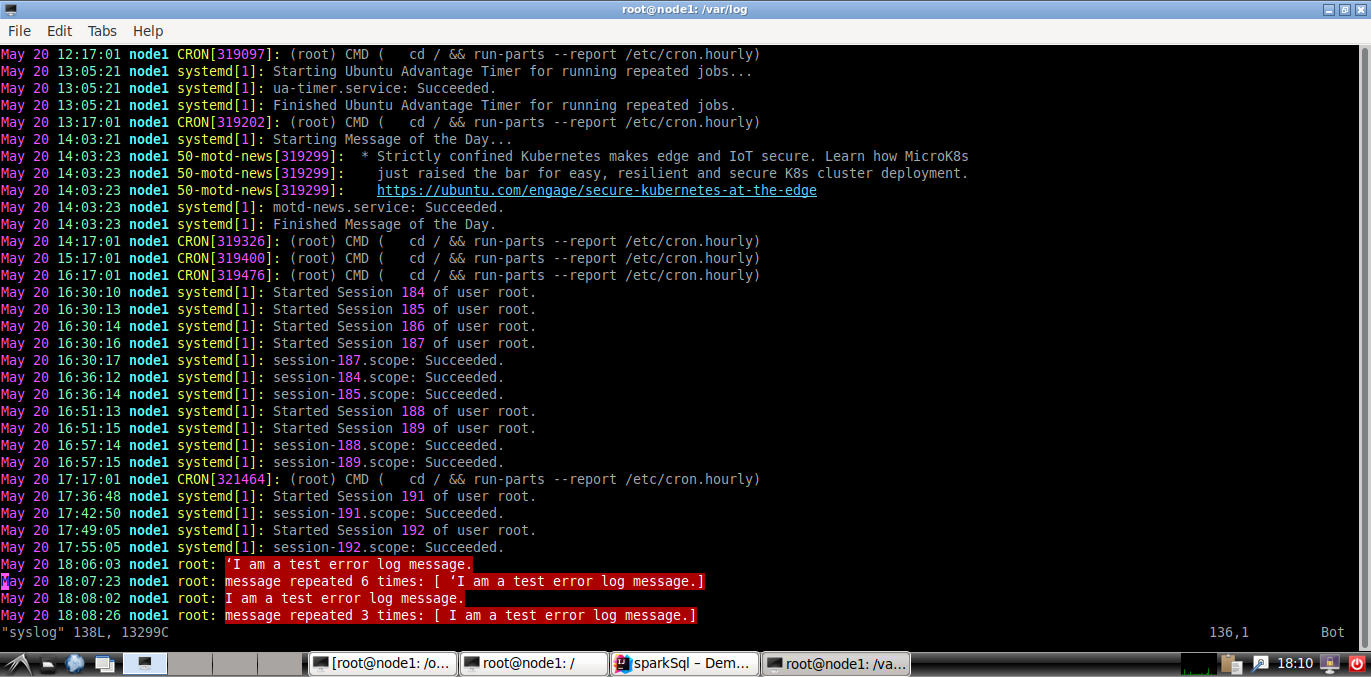
- 由Spark接收nc程序发送过来的日志信息,然后完成以下任务:
- 统计CRON这个进程每小时生成的日志数,并以时间顺序排列,水印设置为1分钟。
- 统计每小时的每个进程或者服务分别产生的日志总数,水印设置为1分钟。
- 输出所有日志内容带error的日志。
from pyspark.sql.functions import window from pyspark.sql import SparkSession from pyspark.sql.functions import col from pyspark.sql.types import StructType, StructField, StringType, TimestampType # 创建SparkSession spark = SparkSession.builder \ .appName("LogAnalysis") \ .getOrCreate() # 定义日志数据的模式 schema = StructType([ StructField("timestamp", TimestampType(), True), StructField("message", StringType(), True) ]) # 从socket接收日志数据流 logs = spark.readStream \ .format("socket") \ .option("host", "localhost") \ .option("port", 9988) \ .load() # 将接收到的日志数据流应用模式 logs = logs.selectExpr("CAST(value AS STRING)") \ .selectExpr("to_timestamp(value, 'yyyy-MM-dd HH:mm:ss') AS timestamp", "value AS message") \ .select(col("timestamp"), col("message").alias("log_message")) # 统计CRON进程每小时生成的日志数,并按时间顺序排列 cron_logs = logs.filter(col("log_message").contains("CRON")) \ .groupBy(window("timestamp", "1 hour")) \ .count() \ .orderBy("window") # 统计每小时每个进程或服务产生的日志总数 service_logs = logs.groupBy(window("timestamp", "1 hour"), "log_message") \ .count() \ .orderBy("window") # 输出所有带有"error"的日志内容 error_logs = logs.filter(col("log_message").contains("error")) # 设置水印为1分钟 cron_logs = cron_logs.withWatermark("window", "1 minute") service_logs = service_logs.withWatermark("window", "1 minute") error_logs = error_logs.withWatermark("timestamp", "1 minute") # 启动流式处理并输出结果 query_cron_logs = cron_logs.writeStream \ .outputMode("complete") \ .format("console") \ .start() query_service_logs = service_logs.writeStream \ .outputMode("complete") \ .format("console") \ .start() query_error_logs = error_logs.writeStream \ .outputMode("append") \ .format("console") \ .start() # 等待流式处理完成 query_cron_logs.awaitTermination() query_service_logs.awaitTermination() query_error_logs.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
2.股市分析任务(进阶任务)
- 数据集采用dj30数据集,见教学平台。
- 实验说明:
- 本实验将使用两个移动均线策略,短期移动均线为10天,长期移动均线为40天。
- 当短期移动均线越过长期移动均线时,这是一个买入信号,因为它表明趋势正在向上移动。这就是所谓的黄金交叉。
- 同时,当短期移动均线穿过长期移动均线下方时,这是一个卖出信号,因为它表明趋势正在向下移动。这就是所谓的死亡交叉。
- 两种叉形如下图所示:dj30.csv包含了道琼斯工业平均指数25年的价格历史。
- 实验要求:
- 1.设置流以将数据输入structed streaming。
- 2.使用structed streaming窗口累计 dj30sum和dj30ct,分别为价格的总和和计数。
- 3.将这两个structed streaming (dj30sum和dj30ct)分开产生dj30avg,从而创建10天MA和40天MA的移动平均值。
- 4.比较两个移动平均线(短期移动平均线和长期移动平均线)来指示买入和卖出信号。
- 您的输出[dj30-feeder只有一个符号的数据:DJI,这是隐含的。
- 这个问题的输出将是[(<日期>买入DJI),(<日期>卖出DJI),等等]。
- 应该是[(<日期>买入<符号>),(<日期>卖出<符号>),等等]的形式。
1.设置流以将数据输入structed streaming。
- 使用pandas进行数据处理
import pandas as pd
# 读取数据文件
data = pd.read_csv('/usr/local/data/dj30.csv')
# 选择需要的列
selected_data = data[['Long Date', 'Close']]
# 输出数据到控制台
print(selected_data)
# 保存数据到文件
selected_data.to_csv('/usr/local/data/dj.csv', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 设置流以将数据输入structed streaming
from pyspark.sql import SparkSession from pyspark.sql.functions import * from pyspark.sql.types import * # 创建SparkSession spark = SparkSession.builder \ .appName("StructuredStreamingExample") \ .getOrCreate() # 定义数据模式 schema = StructType([ StructField("Long Date", StringType()), StructField("Close", DoubleType()) ]) # 读取数据流 data_stream = spark.readStream \ .format("csv") \ .option("header", True) \ .schema(schema) \ .load("/usr/local/dj30.csv") # 处理数据流 processed_stream = data_stream.select("Long Date", "Close") # 输出到控制台 query = processed_stream.writeStream \ .format("console") \ .outputMode("append") \ .start() # 等待流处理完成 query.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
2.使用structed streaming窗口累计 dj30sum和dj30ct,分别为价格的总和和计数
3.将这两个structed streaming (dj30sum和dj30ct)分开产生dj30avg,从而创建10天MA和40天MA的移动平均值
4.比较两个移动平均线(短期移动平均线和长期移动平均线)来指示买入和卖出信号。
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

