
- 1Ubuntu crontab 遇到的sh脚本一些问题(手动执行可以,自动执行不行)_crontab sh 不执行
- 2Github pages 同步到Gitee pages 并自动更新Gitee pages_gitee pages怎么自动更新
- 3堆栈相关面试题(详解)_c语言面试 堆栈
- 4新书《Kali Linux2020 渗透测试指南》星球福利及最终目录&概要公布
- 5【可运行jar】Windows、linux下让JAR在后台运行的方法_windows运行nohup java -jar脚本
- 6【python 时间戳】python获取13位时间戳以及时间戳转换_python13位数字转日期函数
- 7Python 基础| Python 直接赋值、深拷贝和浅拷贝_python深拷贝、浅拷贝、赋值
- 8ES多个字段聚合分组,在结果上执行二次统计分析_es查询结果按字段分组查询
- 9idea 左下角的Git(Version Control)中显示Local Changes窗口_idea localchanges
- 10eclipse+pydev 怎么导入已有的python项目_pydev 导入python依赖
selenium绕过检测,规避检测_selenium被淘宝检测到了
赞
踩
规避检测
1.介绍
我们在使用Python Selenium进行自动化测试或爬虫时,有时会遇到被网站检测到并阻止的情况。这些网站通常会使用各种技术手段来检测和阻止自动化脚本,例如检测浏览器指纹、检查页面元素是否被自动化程序操作、检测用户行为模式等。本文将介绍一些常见的技术手段,以及如何利用Python Selenium来绕过这些检测。
2.常见的检测手段
-
检测浏览器指纹
浏览器指纹是由浏览器的各种属性组成的标识符,例如User-Agent、Accept-Language、屏幕分辨率等。网站可以通过检测这些属性来判断用户是否使用真实浏览器,而不是自动化程序。 -
检查页面元素是否被自动化程序操作
网站可以在页面中插入一些隐藏的元素,然后通过检测这些元素是否被自动化程序操作来判断用户是否使用自动化程序。 -
检测用户行为模式
网站可以通过分析用户的鼠标移动、点击、滚动等行为模式来判断用户是否使用自动化程序。例如,用户使用自动化程序时,鼠标移动可能会呈现直线或者间隔相等的模式。
3.为何要规避
- 现在不少大网站有对selenium采取了监测机制。比如正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为 undefined或者为false。
而使用selenium访问则该值为true。那么如何解决这个问题呢?
4.绕过检测的方案
1. 修改浏览器指纹
我们可以通过修改Selenium WebDriver的User-Agent、Accept-Language等属性,来模拟真实浏览器的指纹。以下是一个修改User-Agent的示例代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36")
driver = webdriver.Chrome(chrome_options=chrome_options)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2. 模拟人类操作行为
为了模拟人类操作行为,我们可以在自动化脚本中添加一些随机的等待时间、随机的鼠标移动、随机的滚动等操作,以使自动化程序的行为更加随机化。以下是一个添加随机等待时间的示例代码:
import random
from time import sleep
# 在操作之前添加随机的等待时间
def random_sleep():
sleep(random.uniform(1, 3))
# 模拟人类操作行为
def simulate_human_behavior():
# 具体的操作代码...
random_sleep()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3. 处理页面元素检测
有些网站会在页面中插入一些隐藏的元素,然后通过检测这些元素是否被自动化程序操作来判断用户是否使用自动化程序。我们可以使用Selenium的execute_script方法来修改页面元素的属性,或者通过JavaScript代码来删除这些元素。以下是一个通过JavaScript代码删除页面元素的示例代码:
from selenium import webdriver
driver = webdriver.Chrome()
# 执行JavaScript代码删除元素
driver.execute_script("var elem = document.getElementById('element_id'); elem.parentElement.removeChild(elem);")
- 1
- 2
- 3
- 4
- 5
- 6
4. 使用Selenium的headless模式
Selenium可以在headless模式下运行,即在后台运行浏览器而不显示界面。使用headless模式可以减少被检测到的可能性。以下是一个使用headless模式的示例代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") # 使用headless模式
driver = webdriver.Chrome(chrome_options=chrome_options)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.使用js注入,绕过检测
我们正常浏览器登录查看,window.navigator.webdriver的值为false
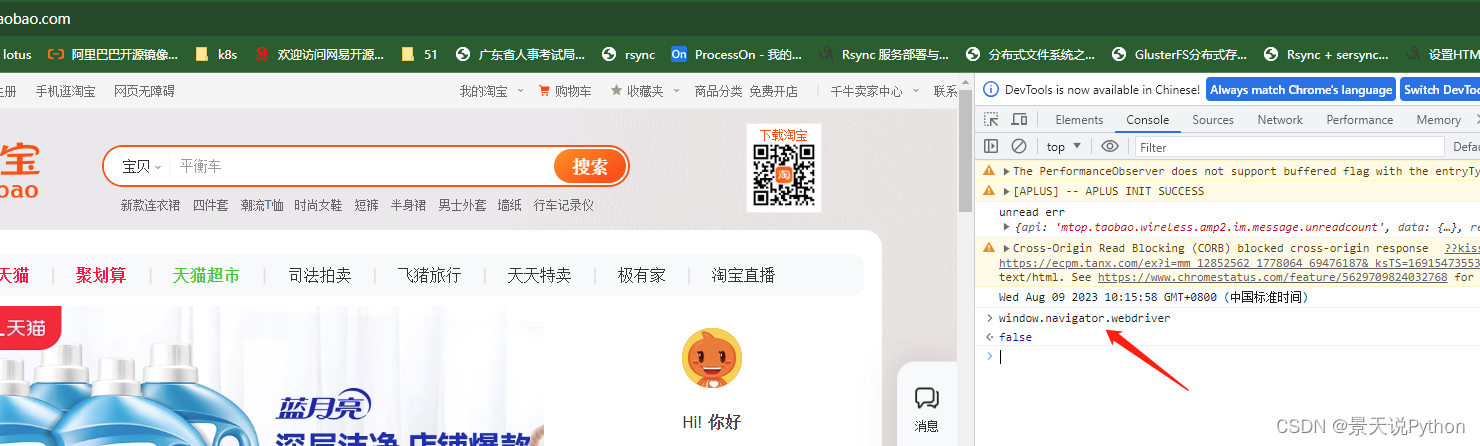
我们通过selenium打开的网页,测试,可见window.navigator.webdriver的值为true
说明,已经淘宝监控到使用selenuim,如果使用selenium爬数据,可能会有问题
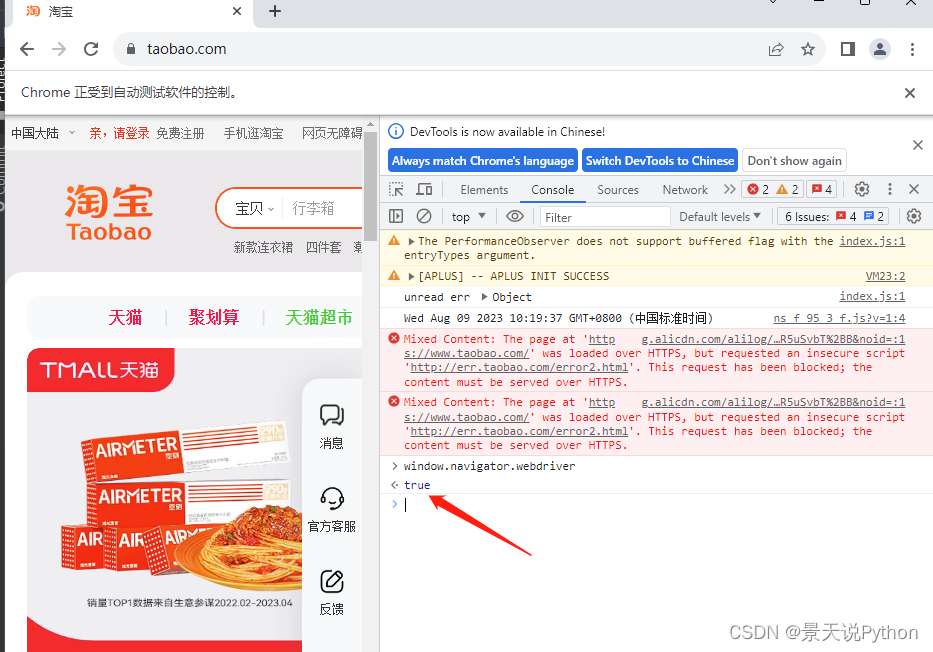
这样,只要网站监测到使用了爬虫程序,就拒绝访问,或者不返回数据。这样就爬取不到数据
js代码: 在本地保存着
from selenium.webdriver import ActionChains
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
#规避检测环节1
chrome_options = Options()
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36')
#驱动路径
path = r'D:\downloads\chromedriver_win32\chromedriver.exe'
driver = Chrome(path,options=chrome_options)
#规避检测环节2
#Selenium在打开任何页面之前,先运行这个Js文件。
with open('./stealth.min.js') as f:
js = f.read()
#进行js注入,绕过检测
#execute_cdp_cmd执行cdp命令(在浏览器开发者工具中执行相关指令,完成相关操作)
#Page.addScriptToEvaluateOnNewDocument执行脚本
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://www.jd.com')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
这样,当我们通过selenium打开的网站,就不会被检测到是用selenium打开的
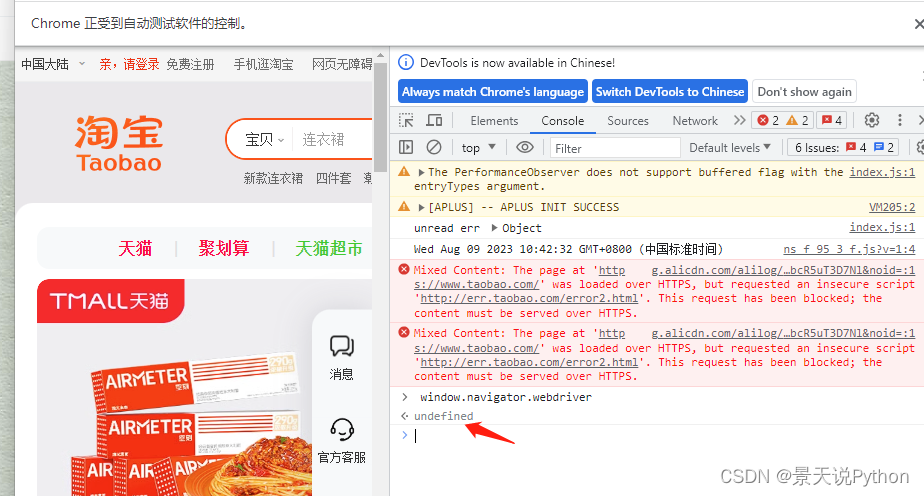
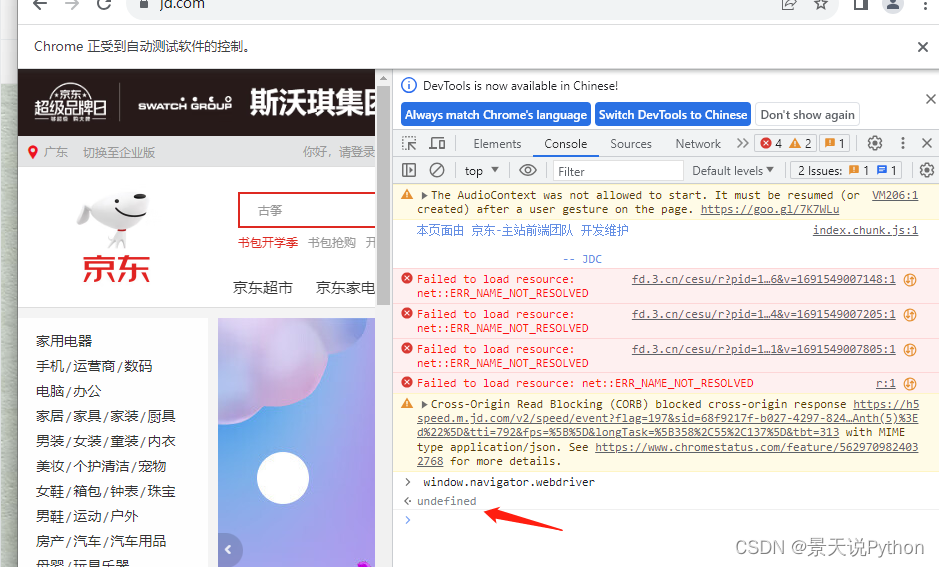
起到了规避检测的效果
这段js代码下载地址:https://download.csdn.net/download/littlefun591/88677768
当然这种规避方法,可能过一年半载就不好使了,此时需要重新钻研怎么规避检测。目前这种方式还可以用


