
- 1计算 MTK中程序占用的ROM 及 RAM_怎么计算程序的rom和ram
- 2手工测试1年经验面试,张口要18K,我真是服了····
- 3Python在使用pip安装某个库时报错 Could not find a version that satisfies the requirement numpy
- 4【Perl语言】Perl语言基础入门指南_perl脚本
- 5如何使用JavaScript在静态页面插入PDF文件(附带效果图)?_ts引入静态pdf并展示
- 6【AI 大模型】提示工程 ① ( 通用人工智能 和 专用人工智能 | 掌握 提示工程 的优势 | 提示工程目的 | 提示词组成、迭代、调优及示例 | 思维链 | 启用思维链的指令 | 思维链原理 )_提示词工程与ai智能体
- 7SQL时间转换
- 8大型语言模型在专业领域应用的关键技术挑战_通用人工智能大模型在处理自然语言时,通常依赖于哪种技术?
- 9Redis实战——分布式锁&Redisson_redisson分布式锁实战
- 10fast-livo运行官方数据集踩坑记录(Ubuntu2004,虚拟机)
spark学习(6)之SparkSQL基础_spark.sql
赞
踩
一、Spark SQL的基础:
1、Spark SQL的简介
Spark SQL is Apache spark’s module for working with structured data
Spark SQL 是apache spark用来出来结构化数据的模块
特点:
(1)容易集成成,安装好spark后就带有spark sql了
(2)统一的数据访问接口DataFrame
(3)兼容hive
(4)支持标准的数据访问方式:JDBC,ODBC
2、SparkSQL的核心数据模型是DataFrame:它的表现形式其实也是RDD
表(DataFrame) = 表结构(Schema) + 数据(RDD)
3、创建DataFrame:DataFrame仅支持DSL语句
(1)样本类case class
示例(使用员工表):
a、创建样本类型
case class Emp(empno:Int,ename:String,job:String,mgr:Int,hiredate:String,sal:Int,comm:Int,deptno:Int)

返回一个defined class Emp表示这个类已经定义好了
b、 读一一个数据(我们可以从hdfs上读取,因为是示例所以我们直接本地文件上读取了)
val lines=sc.textFile("/root/training/emp.csv").map(_.split(","))
- 1

我们可以看到RDD里边是一个数组类型
c、把数组类型的RDD映射成RDD[Emp]
val emp=lines.map(x=>Emp(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))
- 1

d、转化成Spark SQL的核心数据模型DataFrame
val df=emp.toDF
- 1

然后我们可以查看表结构,可以使用DSL语句操作DataFrame
//查看表结构
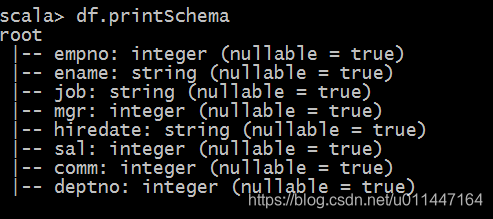
df.printSchema
- 1
- 2
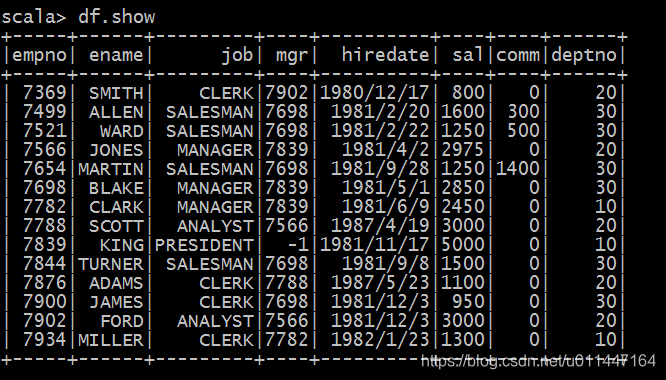
查询所有的数据
df.show
- 1
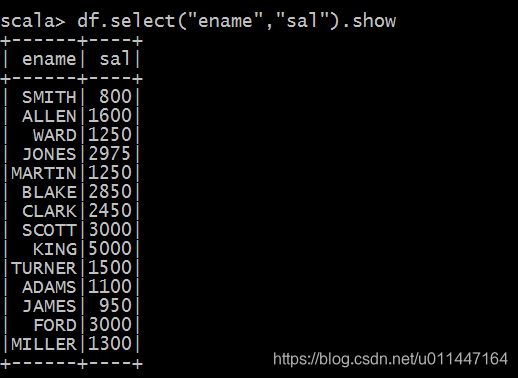
也可查询具体的几个字段
df.select("ename","sal").show
- 1
(2)sparksession
4、创建视图(要用到sparksession对象)
在sparkShell客户端打开的时候就自动创建了俩个对象,一个SparkContext对象叫sc,一个是SparkSession对象叫spark
创建视图是为了我们使用标准的sql语句来操作DataFrame,因为DataFrame仅支持DSL语句,所以我们需要把DataFrame转换成视图来用标准语句进行操作。
视图又分为局部视图和全局视图
局部视图:仅在当前session中有效
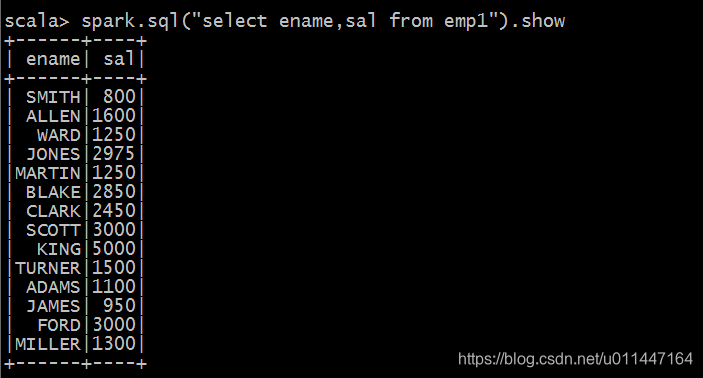
df.createOrReplaceTempView("emp1")
spark.sql("select * from emp1").show
spark.sql("select ename,sal from emp1").show
- 1
- 2
- 3

全局视图:可以在不同的session中访问,单独创建在global_temp的命名空间中
df.df.createGlobalTempView("emp2")
- 1
但是这里查询语句稍微和局部视图有点区别,因为他是创建在global_temp命名空间下的
我们先看一下异常语句
spark.sql("select * from emp2").show
- 1
org.apache.spark.sql.AnalysisException: Table or view not found: emp2; line 1 pos 14
他就会报一个这样的错,这是我们写的sql语句的问题
spark.sql("select * from global_temp.emp2").show
- 1
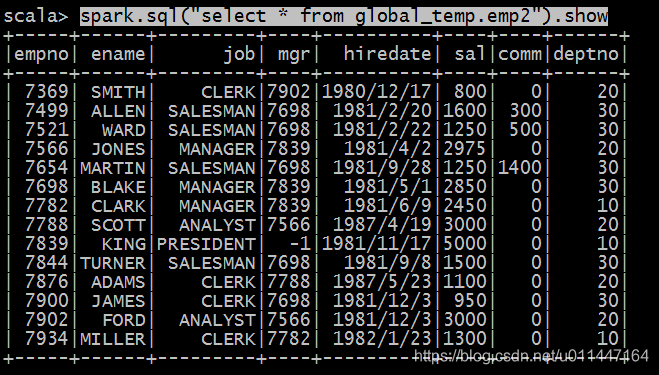
这样就正常了。然后我们看看局部视图和全局视图的区别,然后我们在当前spark-shell下重新的开启一个session
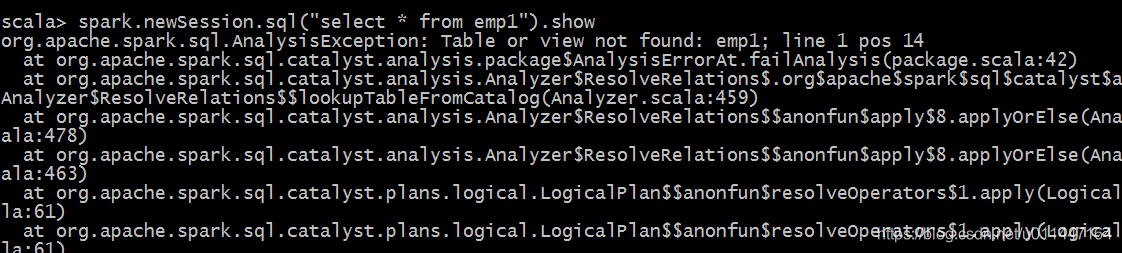
spark.newSession.sql("select * from emp1").show
- 1
我们执行局部视图的语句的时候就会出现这样的错误
然后我们新开个session执行全局视图查询
spark.newSession.sql("select * from global_temp.emp2").show
- 1
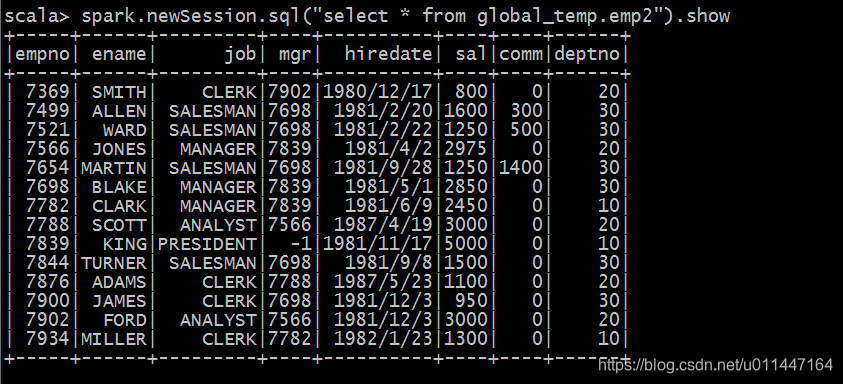
这回就正常了

