
热门标签
热门文章
- 1win11浏览器显示“你尚未连接,代理服务器可能有问题,或地址不正确”_为什么微软浏览器显示尚未连接是什么原因
- 2发布iis让外网也能看到自己的本地站点的方法_iis搭建网站别人可以搜到吗
- 3node.js--初识nodejs、安装方式、执行Node程序的几种方式、Node环境和浏览器环境区别_node客户端与安装包有区别吗
- 4Django学习笔记-ModelForm使用(完全依赖)
- 5如何写个众筹合约
- 6SQL:with as用法_with as 用法
- 7万字长文 | 多目标跟踪最新综述(基于Transformer/图模型/检测和关联/孪生网络)...
- 8鸿蒙系统怎么安装mate30,不让Mate30安装GMS,谷歌真不怕华为使用鸿蒙系统?
- 9蓝牙搜索不到App XXXX is scanning too frequently_scanning too free
- 10网络安全人才缺口超百万,如今的就业情况怎样?_网络安全人才缺口有多大
当前位置: article > 正文
人工智能_大模型015_RAG量化检索增强002_AIGC大模型_本地知识库实时问答_私域和实时场景_量化检索增强---人工智能工作笔记0151
作者:IT小白 | 2024-03-04 08:55:57
赞
踩
人工智能_大模型015_RAG量化检索增强002_AIGC大模型_本地知识库实时问答_私域和实时场景_量化检索增强---人工智能工作笔记0151
由于上一节我们提到的,关键词检索的局限性,现在我们引出向量检索,
关键词检索有语义上的缺陷,因为我们说法不一样,但是意思一样的话,那么,关键词如果在es库中没有,那么会导致,找不到答案的情况.所以我们引出向量检索,要求语义一样的词,去检索都能找到答案.

我们来说一下这个文本向量是什么意思?
可以看到左侧是一组句子,可以看到,每个数据,首先我们把它转换为向量也就是一组数,这一组数
可以是2维的,可以是多维度的,其实对于不同的模型,转换是不一样的,比如OpenAI是1536亿个特征对吧.有几个特征就转换成这样的一组数.
然后假如是2维的,可以看到在右边,红点,那么这几个句子,对应的在,2维空间中的距离,因为他们语义相近,那么距离肯定越近.
那么我们就可以利用这个特性,先去找到这个句子对应es中有没有,如果es库中没有,那么再去看
他对应的语义相近的,文档在es库中有没有对吧,这样一个过程.

那么现在我们需要的就是,如果我们有一个句子,我们如何能得到对应的
这个句子对应的一组数对吧?也就上面的参数
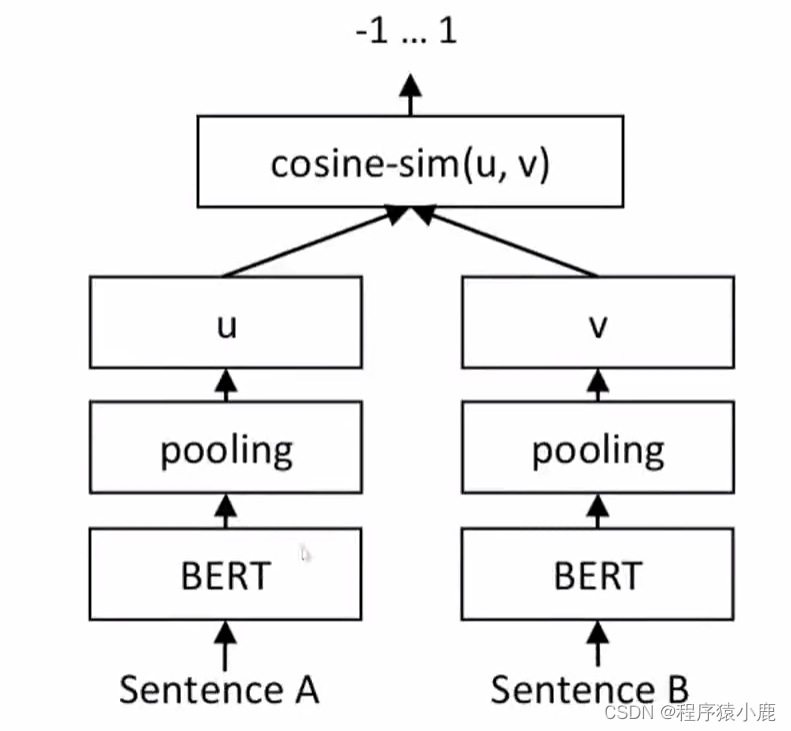
这个双塔式的训练模型是这个意思:
首先训练资料是以一对一对出现的,也就是训练数据,肯定是一块喂给这个模型两个句子,
可
推荐阅读
相关标签

