
- 1电脑技巧:分享五款办公文档密码解除小软件_删除文件密码的软件有什么
- 2网站部署证书 百度浏览器仍提示不安全网站怎么办_百度网址安全中心检测正常
- 3C/C++编程笔记:指针篇!从内存理解指针,让你完全搞懂指针_c++ 指针指向其他数组,原数组内存
- 4uniapp微信小程序video不显示,无法播放_uniapp video 提示当前视频没办法播放
- 5MySQL主备HA(keepalived)方案_mysql keepalive + vip的ha方案
- 6蓝桥杯第十四届电子类单片机组程序设计_csdn蓝桥杯十四
- 7数据可视化高级技术Echarts(桑基图&入门)_echart多维桑基图
- 8模拟退火——算法思想与实例_模拟退火算法例题
- 9Swift高级分享 - 使用Swift Package Manager管理依赖项_swift package manager 排除特定依赖
- 10自学Vue开发Dapp去中心化钱包(三)
哈希算法(哈希函数)基本
赞
踩
目录
一、什么是哈希(Hash)
哈希也称“散列”函数或“杂凑”函数。它是一个不可逆的单向映射,将任意长度的输入消息M(或文件F)映射成为一个较短的定长哈希值H(M),也叫散列值(HashValue)、杂凑值或消息摘要。可见,这是一种单向密码体制,只有加密过程,没有解密过程(因此Hash求逆很困难)。
二、哈希的原理和特点
- 单向性:从哈希值不能反向推导原始数据(计算不可行),即从哈希输出无法倒推输入的原始数值。这是哈希函数安全性的基础。
- 灵敏性:对输入数据敏感,哪怕只改了一个Bit,得到的哈希值也大不相同。换言之,消息M的任何改变都会导致哈希值H(M)发生改变。
- 易压易算:Hash本质上是把一个大范围集合映射到另一个小范围集合。故输入值的个数必须与小范围相当或者更小,不然冲突就会很多。所以,哈希算法执行效率要高,散列结果要尽量均衡。
- 抗碰撞性:理想Hash函数是无碰撞的,但实际上很难做到这一点。有两种抗碰撞性:一种是弱抗碰撞性,即对于给定的消息,要发现另一个消息,满足在计算上是不可行的;另一种是强抗碰撞性,即对于任意一对不同的消息,使得在计算上也是不可行的。
也可以这么理解:正向快速、逆向困难、输入敏感、冲突避免
三、哈希的实际用途
Hash能把一个大范围映射到一个小范围,能对输入数据或文件进行校验,还可用于查找等。具体的:
- 唯一标识或数据检验:能够对输入数据或文件进行校验,判断是否相同或是否被修改。如图片识别,可针对图像二进制流进行摘要后MD5,得到的哈希值作为图片唯一标识;如文件识别,服务器在接受文件上传时,对比两次传送文件的哈希值,若相同则无须再次上传(传统的奇偶校验和CRC校验一定程度上能检测并纠正数据传输中的信道误码,但没有抗数据篡改的能力)。
- 安全加密:对于敏感数据比如密码字段进行MD5或SHA加密传输。哈希算法还可以检验信息的拥有者是否真实。如,用保存密码的哈希值代替保存密码,基本可以杜绝泄密风险。
- 数字签名。由于非对称算法的运算速度较慢,所以在数字签名协议中,单向散列函数扮演了一个重要的角色。对Hash值,又称“数字摘要”进行数字签名,在统计上可以认为与对文件本身进行数字签名是等效的。
- 散列函数:是构造散列表的关键。它直接决定了散列冲突的概率和散列表的性质。不过相对哈希算法的其他方面应用,散列函数对散列冲突要求较低,出现冲突时可以通过开放寻址法或链表法解决冲突。对散列值是否能够反向解密要求也不高。反而更加关注的是散列的均匀性,即是否散列值均匀落入槽中以及散列函数执行的快慢也会影响散列表性能。所以散列函数一般比较简单,追求均匀和高效。
- *负载均衡:常用的负载均衡算法有很多,比如轮询、随机、加权轮询。如何实现一个会话粘滞的负载均衡算法呢?可以通过哈希算法,对客户端IP地址或会话SessionID计算哈希值,将取得的哈希值与服务器列表大小进行取模运算,最终得到应该被路由到的服务器编号。这样就可以把同一IP的客户端请求发到同一个后端服务器上。
- *数据分片:比如统计1T的日志文件中“搜索关键词”出现次数该如何解决?我们可以先对日志进行分片,然后采用多机处理,来提高处理速度。从搜索的日志中依次读取搜索关键词,并通过哈希函数计算哈希值,然后再跟n(机器数)取模,最终得到的值就是应该被分到的机器编号。这样相同哈希值的关键词就被分到同一台机器进行处理。每台机器分别计算关键词出现的次数,再进行合并就是最终结果。这也是MapReduce的基本思想。再比如图片识别应用中给每个图片的摘要信息取唯一标识然后构建散列表,如果图库中有大量图片,单机的hash表会过大,超过单机内存容量。这时也可以使用分片思想,准备n台机器,每台机器负责散列表的一部分数据。每次从图库取一个图片,计算唯一标识,然后与机器个数n求余取模,得到的值就是被分配到的机器编号,然后将这个唯一标识和图片路径发往对应机器构建散列表。当进行图片查找时,使用相同的哈希函数对图片摘要信息取唯一标识并对n求余取模操作后,得到的值k,就是当前图片所存储的机器编号,在该机器的散列表中查找该图片即可。实际上海量数据的处理问题,都可以借助这种数据分片思想,突破单机内存、CPU等资源限制。
- *分布式存储:一致性哈希算法解决缓存等分布式系统的扩容、缩容导致大量数据搬移难题。
四、典型的哈希函数
常见Hash算法有MD5和SHA系列,目前MD5和SHA1已经被破解,一般推荐至少使用SHA2-256算法。
(一)MD5
MD5属于Hash算法中的一种,它输入任意长度的信息,在处理过程中以512位输入数据块为单位,输出为128位的信息(数字指纹)。常用场景:
1、防篡改,保障文件传输可靠性:如SVN中对文件的控制;文件下载过程中,网站提供MD5值供下载后判断文件是否被篡改;BT中对文件块进行校验的功能。
2、增强密码保存的安全性:例如网站将用户密码的MD5值保存,而不是存储明文用户密码,当然,还会加SALT,进一步增强安全性。
3、数字签名:在部分网上赌场中,使用MD5算法来保证过程的公平性,并使用随机串进行防碰撞,增加解码难度。
算法实现过程:
第一步:消息填充,补长到512的倍数。最后64位为消息长度(填充前的长度)的低64位,一定要补长(64+1~512),内容为100…0(如若消息长448,则填充512+64)。
第二步:分割,把结果分割为512位的块:Y0,Y1,…(每一个有16个32比特长字)。
第三步:计算,初始化MD buffer,128位常量(4个32bit字),进入循环迭代,共L次。每次一个输入128位,另一个输入512位,结果输出128位,用于下一轮输入。
第四步:输出,最后一步的输出即为散列结果128位。
(二)SHA-1 Secure Hash Algorithm
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64b的消息,SHA-1将输入流按照每块512b(64B)进行分块,并产生20B或160b的信息摘要。
1.补位
消息补位使其长度在对512取模以后的余数是448。也就是说,(补位后的消息长度)% 512 = 448。即使长度已经满足对512取模后余数是448,补位也必须要进行。
补位是这样进行的:先补一个1,然后再补0,直到长度满足对512取模后余数是448。总而言之,补位是至少补一位,最多补512位。还是以前面的“abc”为例显示补位的过程。
原始信息: 011000010110001001100011
补位第一步:0110000101100010011000111,首先补一个“1”
补位第二步:01100001011000100110001110…..0,然后补423个“0”
我们可以把最后补位完成后的数据用16进制写成下面的样子,确保是448b:
61626380000000000000000000000000
00000000000000000000000000000000
00000000000000000000000000000000
0000000000000000
2.补长度
补长度是将原始数据的长度补到已经进行了补位操作的消息后面。通常用一个64位的数据来表示原始消息的长度。如果消息长度不大于2^64,那么第一个字就是0。
在进行了补长度的操作以后,整个消息就变成下面这样了(16进制格式):
61626380000000000000000000000000
00000000000000000000000000000000
00000000000000000000000000000000
00000000000000000000000000000018
如果原始的消息长度超过了512,我们需要将它补成512的倍数。然后我们把整个消息分成一个一个512位的数据块。分别处理每一个数据块,从而得到消息摘要。
3.使用的常量
一系列的常量字K(0),K(1),...,K(79),如果以16进制给出。它们如下:
Kt=0x5A827999(0<=t<=19)
Kt=0x6ED9EBA1(20<=t<=39)
Kt=0x8F1BBCDC(40<=t<=59)
Kt=0xCA62C1D6(60<=t<=79).
4.需要使用的函数
在SHA1中我们需要一系列的函数。每个函数ft(0<=t<=79)都操作32位字B,C,D并且产生32位字作为输出。
ft(B,C,D)可以如下定义:
ft(B,C,D)=(BANDC)or((NOTB)ANDD)(0<=t<=19)
ft(B,C,D)=BXORCXORD(20<=t<=39)
ft(B,C,D)=(BANDC)or(BANDD)or(CANDD)(40<=t<=59)
ft(B,C,D)=BXORCXORD(60<=t<=79).
5.计算消息摘要
必须使用进行了补位和补长度后的消息来计算消息摘要。计算需要两个缓冲区,每个都由5个32位的字组成,还需要一个80个32位字的缓冲区。第一个5个字的缓冲区被标识为A,B,C,D,E。第一个5个字的缓冲区被标识为H0,H1,H2,H3,H4。80个字的缓冲区被标识为W0,W1,...,W79。
另外还需要一个一个字的TEMP缓冲区。
为了产生消息摘要,在第4部分中定义的16个字的数据块M1,M2,...,Mn会依次进行处理,处理每个数据块Mi包含80个步骤。
在处理每个数据块之前,缓冲区{Hi}被初始化为下面的值(16进制)
H0=0x67452301
H1=0xEFCDAB89
H2=0x98BADCFE
H3=0x10325476
H4=0xC3D2E1F0.
现在开始处理M1,M2,...,Mn。为了处理Mi,需要进行下面的步骤
(1)将Mi分成16个字W0,W1,...,W15,W0是最左边的字
(2)对于t=16到79令Wt=S1(Wt-3XORWt-8XORWt-14XORWt-16).
(3)令A=H0,B=H1,C=H2,D=H3,E=H4.
(4)对于t=0到79,执行下面的循环
TEMP=S5(A)+ft(B,C,D)+E+Wt+Kt;
E=D;D=C;C=S30(B);B=A;A=TEMP;
(5)令H0=H0+A,H1=H1+B,H2=H2+C,H3=H3+D,H4=H4+E.
在处理完所有的Mn,后,消息摘要是一个160位的字符串,以下面的顺序标识H0H1H2H3H4。
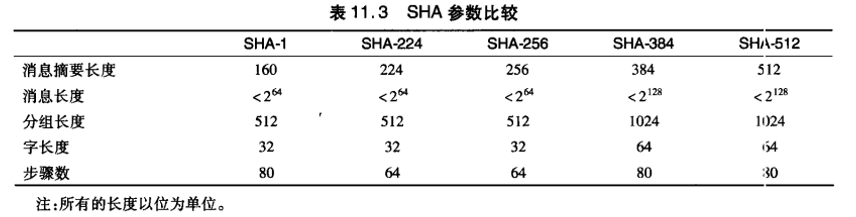
(三)SHA-2系列
SHA-2是六个不同算法的合称,包括:SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256。除了生成摘要的长度、循环运行的次数等一些微小差异外,这些算法的基本结构是一致的。对于任意长度的消息,SHA256都会产生一个256bit长的消息摘要。
详细参见:sha256算法原理 - Practical - 博客园
至今尚未出现对SHA-2有效的攻击,SHA-2和SHA-1并没有接受公众密码社区的详细检验,所以它们的密码安全性还不被广泛信任。
总体上,HAS-256与MD4、MD5以及HSA-1等哈希函数的操作流程类似,在哈希计算之前首先要进行以下两个步骤:
- 对消息进行补位处理,最终的长度是512位的倍数;
- 以512位为单位对消息进行分块为M1,M2,…,Mn
- 处理消息块:从一个初始哈希H0开始,迭代计算:Hi = Hi-1 + CMi(Hi-1)
其中C是SHA256的压缩函数,+是mod 2^32加法,Hn是消息区块的哈希值。
五、Hash构造函数的方法
1.直接定址法(极少用)
以数据元素关键字k本身或它的线性函数作为它的哈希地址,即:H(k)=k或H(k)=a×k+b;(其中a,b为常数)。
此法仅适合于:地址集合的大小==关键字集合的大小,其中a和b为常数。
2.数字分析法
假设关键字集合中的每个关键字都是由s位数字组成(u1,u2,…,us),分析关键字集中的全体,并从中提取分布均匀的若干位或它们的组合作为地址。数字分析法是取数据元素关键字中某些取值较均匀的数字位作为哈希地址的方法。即当关键字的位数很多时,可以通过对关键字的各位进行分析,丢掉分布不均匀的位,作为哈希值。它只适合于所有关键字值已知的情况。通过分析分布情况把关键字取值区间转化为一个较小的关键字取值区间。
此法适于:能预先估计出全体关键字的每一位上各种数字出现的频度。
3.折叠法
将关键字分割成若干部分,然后取它们的叠加和为哈希地址。两种叠加处理的方法:移位叠加:将分割后的几部分低位对齐相加;边界叠加:从一端沿分割界来回折叠,然后对齐相加。
所谓折叠法是将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位),这方法称为折叠法。这种方法适用于关键字位数较多,而且关键字中每一位上数字分布大致均匀的情况。
折叠法中数位折叠又分为移位叠加和边界叠加两种方法,移位叠加是将分割后是每一部分的最低位对齐,然后相加;边界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
此法适于:关键字的数字位数特别多。
4.平方取中法
这是一种常用的哈希函数构造方法。这个方法是先取关键字的平方,然后根据可使用空间的大小,选取平方数是中间几位为哈希地址。哈希函数H(key)=“key2的中间几位”因为这种方法的原理是通过取平方扩大差别,平方值的中间几位和这个数的每一位都相关,则对不同的关键字得到的哈希函数值不易产生冲突,由此产生的哈希地址也较为均匀。
此法适于:关键字中的每一位都有某些数字重复出现频度很高的现象。
5.减去法
6.基数转换法
将十进制数X看作其他进制,比如十三进制,再按照十三进制数转换成十进制数,提取其中若干为作为X的哈希值。一般取大于原来基数的数作为转换的基数,并且两个基数应该是互素的。
7.除留余数法
假设哈希表长为m,p为小于等于m的最大素数,则哈希函数为h(k)=k%p,其中%为模p取余运算。除留余数法的模p取不大于表长且最接近表长m素数时效果最好,且p最好取1.1n~1.7n之间的一个素数(n为存在的数据元素个数)。
8.随机数法
设定哈希函数为:H(key)=Random(key)其中,Random为伪随机函数
此法适于:对长度不等的关键字构造哈希函数。
9.随机乘数法
亦称为“乘余取整法”。随机乘数法使用一个随机实数f,0≤f<1,乘积f*k的分数部分在0~1之间,用这个分数部分的值与n(哈希表的长度)相乘,乘积的整数部分就是对应的哈希值,显然这个哈希值落在0~n-1之间。其表达公式为:Hash(k)=「n*(f*k%1)」其中“f*k%1”表示f*k的小数部分,即f*k%1=f*k-「f*k」
此方法的优点是对n的选择不很关键。通常若地址空间为p位就是选n=2p.Knuth对常数f的取法做了仔细的研究,他认为f取任何值都可以,但某些值效果更好。如f=(-1)/2=0.6180329...比较理想。
10.字符串数值哈希法
把字符串的前10个字符的ASCⅡ值之和对N取摸作为Hash地址,只要N较小,Hash地址将较均匀分布[0,N]区间内。对于N很大的情形,可使用ELFHash(ExecutableandLinkingFormat,ELF,可执行链接格式)函数,它把一个字符串的绝对长度作为输入,并通过一种方式把字符的十进制值结合起来,对长字符串和短字符串都有效,这种方式产生的位置可能不均匀分布。
11.旋转法
旋转法是将数据的键值中进行旋转。旋转法通常并不直接使用在哈希函数上,而是搭配其他哈希函数使用。

