- 1Opencv 图像金字塔----高斯和拉普拉斯_高斯拉普拉斯金字塔
- 2ZeroTier软件原理与使用_zerotier moon原理 图
- 3二叉排序树和堆的区别_堆和二叉排序树的区别
- 4朴素贝叶斯分类器算法_朴素贝叶斯算法,rules-zeror分类器算法原理(最频繁类算法)以及决策树j48算法的优
- 5【vue2,3使用QRCode进行二维码的生成和下载】_vue3 qrcode
- 6PicGo+GitHub搭建免费图床
- 7Http请求状态码-416_http 416
- 8阿里开源的32B大模型到底强在哪里?_qwen 110b要多少显存
- 9值得收藏的25道Python练手题(附详细答案)_python编程题题库
- 10python绘图代码大全和用法,python海龟编程代码大全_python形状代码
大模型的RAG(检索增强生成) ----大模型外挂
赞
踩
目录
1 什么是RAG
检索增强生成(RAG)是一个概念,也可以称为一种范式,它旨在为大语言模型(Large Language Model,LLM)提供额外的、来自外部知识源的信息。
2020 年,Lewis 等人在论文《知识密集型 NLP 任务的检索增强生成》(Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks) 中,提出了一种更为灵活的技术——检索增强生成(Retrieval-Augmented Generation,RAG)。该研究将生成模型与检索模块结合起来,能够从易于更新的外部知识源中获取额外信息。
用一个简单的比喻来说, RAG 对大语言模型的作用,就像开卷考试对学生一样。在开卷考试中,学生可以带着参考资料进场,比如教科书或笔记,用来查找解答问题所需的相关信息。开卷考试的核心在于考察学生的推理能力,而非对具体信息的记忆能力。
在 RAG 中,事实性知识(知识库)与 LLM 的推理能力(模型)相分离,被存储在容易访问和及时更新的外部知识源中,具体分为两种:
- 参数化知识(Parametric knowledge): 模型在训练过程中学习得到的,隐式地储存在神经网络的权重中。
- 非参数化知识(Non-parametric knowledge): 存储在外部知识源,例如向量数据库中。
2 为什么需要RAG
仅依靠大模型已经可以完成很多任务,微调(Fine-tune) 也可以起到补充领域知识的作用,为什么 RAG 仍然如此重要呢?
- 幻觉问题:尽管大模型的参数量很大,但和人类的所有知识相比,仍然有非常大的差距。所以,大模型在生成内容时,很有可能会捏造事实。因此,对于 LLMs 而言,通过搜索召回相关领域知识来作为特定领域的知识补充是非常必要的。
- 语料更新时效性问题:大模型的训练数据存在时间截止的问题。尽管可以通过 Fine-tune 来为大模型加入新的知识,但大模型的的训练成本和时间依然是需要面对的严峻难题:通常需要大量的计算资源,时间也难做到天级别更新。在 RAG 模式下,向量数据库和搜索引擎数据的更新都更加容易,这有助于业务数据的实时性。
- 数据泄露问题:尽管可以利用 Fine-tune 的方式增强 LLM 在特定领域的处理能力。但是,用于 Fine-tune 的这些领域知识很可能包含个人或者公司的机密信息,且这些数据很可能通过模型而不经意间泄露出去。RAG 可以通过增加私有数据存储的方式使得用户的数据更加安全。
3 如何使用RAG
3.1 RAG技术原理
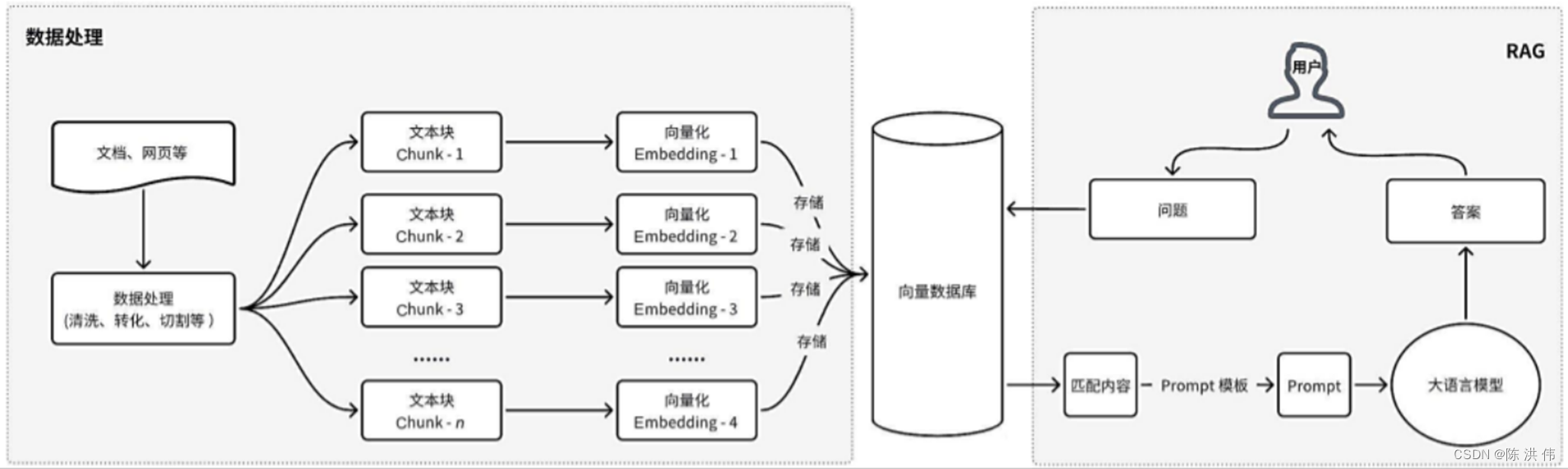
RAG 结合了信息检索和文本生成两种方法,旨在突破传统问答系统的局限。通过将外部数据检索的相关信息输入大语言模型,大语言模型能够基于这些信息生成回答,进而增强答案生成的能力。
RAG 主要有两个核心组件:信息检索和文本生成。
信息检索(Retrieve)的主要任务是在一个大型的知识库或文档集合中搜索与用户提出的问题相关的信息。这个过程类似人在图书馆中查找相关书籍以回答某个问题。通常,这一步骤依赖传统的信息检索技术,如倒排索引、TF-IDF 评分、BM25 算法等,或者采用更现代的基于向量的搜索方法。
文本生成(Generate)的职责是根据检索到的信息生成一个连贯、准确的回答。这个过程可以看作根据收集到的材料撰写一篇简短的文章或回答。这个功能通常采用预训练的生成式语言模型来实现,如 GPT 、LLama系列。仅加载外部文件是不够的。通常,外部文件非常大,而且 Embedding 模型和大语言模型都有长度限制,这时就需要将文件进一步切割成文本块(Chunk),才能精准地进行检索和生成。根据索引方式的不同、模型选择的不同,以及问答文本长度和复杂度的不同,切割的方法也有不同。

3.2 RAG工作流程
检索: 将用户的查询通过嵌入模型转化为向量,以便与向量数据库中的其他上下文信息进行比对。通过这种相似性搜索,可以找到向量数据库中最匹配的前 k 个数据。
增强: 将用户的查询和检索到的额外信息一起嵌入到一个预设的提示模板中。
生成: 最后,这个经过检索增强的提示内容会被输入到大语言模型 (LLM) 中,以生成所需的输出。
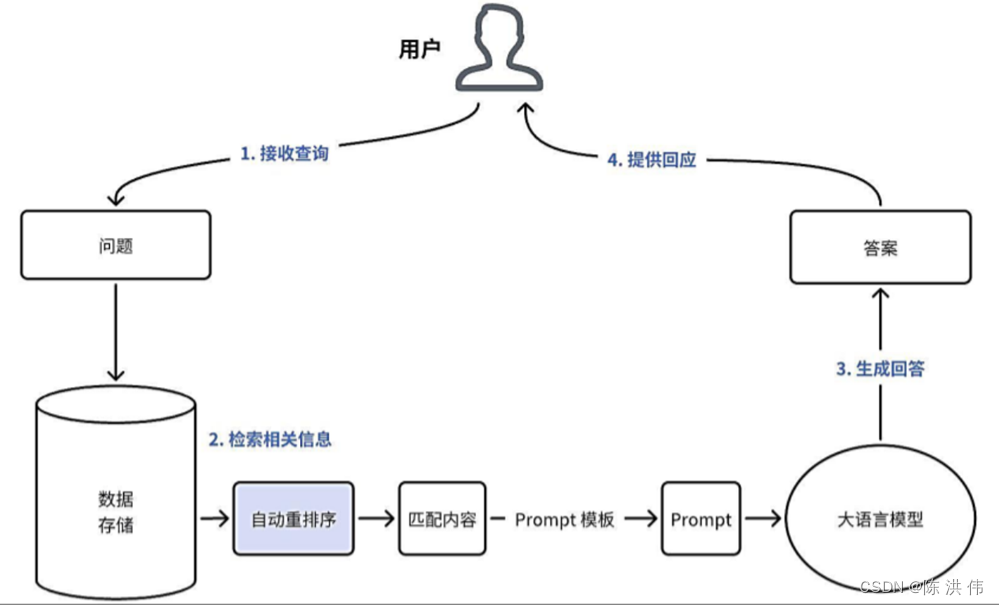
3.2.1 最基础的RAG流程
- 接收查询:系统收到用户的问题或查询。
- 检索相关信息:系统查询一个或多个外部知识库,查找与该问题相关的信息或文档。
- 生成回答:大语言模型利用检索到的信息和用户的原始查询生成回应。这个过程不是仅复制检索到的信息,而是根据用户的具体问题创造性地生成回应。
- 提供回应:系统将生成的回答呈现给用户。

3.2.2 增加预处理查询的 RAG
在用户提问环节,可以对问题进行进一步的预处理和理解查询。
- 问题预处理:系统先对用户输入进行预处理,如文本清洗、标准化等,确保输入数据的质量。
- 理解查询:系统运用自然语言处理技术理解查询的内容和意图。这个环节可以利用传统自然语言处理技术中的知识领域和意图识别,即根据用户的提问选择不同数据库中的内容,甚至可以对应不同匹配阈值及操作。

3.2.3 带有聊天历史的 RAG
在实际对话中,用户和系统的交流往往不是一句话,而是多句话,且上下文之间有指代关系。例如,用户说了两句话:
- 张三是北大的学生。
- 他今年多大了?
如果系统逐句处理接收的信息,则无法确定句子中的“他”指的是谁。系统需要将两句话结合起来,才能正确理解用户的提问是“张三多大了”。
在这个例子中,除了对问题进行基础的预处理,还有一步重要的操作就是把之前的历史记录输入系统。通用的做法之一是让大语言模型将当前的问题和先前的问题结合,使用 Prompt 引导大语言模型重写用户的问题,这样做可以有效地解决指代消除的问题。

3.2.4 增加自动排序的 RAG
尽管增加了聊天的历史记录,但由于在数据处理环节中系统内切割成的块数量很多,系统检索的维度不一定是最有效的,因此一次检索的结果在相关性上并不理想。这时,需要一些策略对检索的结果进行重新排序,或者重新调整组合相关度、匹配度等因素,使其更适合业务的场景。
对此,通常会设置内部触发器进行自动评审,触发自动重排序的逻辑。