
- 1C语言基础知识理论版(很详细)_c语言的理论
- 2最新 | Ask Me Anything 一种提示(Prompt)语言模型的简单策略(斯坦福大学 & 含源码)_llm prompt
- 3聚类篇——(二)K-means聚类_kmeans聚类问题描述
- 4【C/C++】【学生成绩管理系统】深度剖析
- 5TTS 语音合成技术学习
- 6独立开发变现周刊(第119期):一个自学开发者创建一个月收入12.5万美元的软件公司...
- 7Python_tkinter(按钮,文本框,多行文本组件)_tkinter button边上加字
- 8Redis进阶 - 朝生暮死之Redis过期策略_redis 定时 过期
- 9Git -- reset 详解_git reset 文件
- 10李宏毅2023机器学习作业HW06解析和代码分享
全文检索 Elasticsearch(简称es)_es全文检索
赞
踩
全文检索 Elasticsearch 研究
1. ElasticSearch 介绍
1.1 介绍
**Elasticsearch**是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。Elasticsearch是用Java开发的,并在Apache许可证下作为开源软件发布。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。

Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。
另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
**官方网址:**https://www.elastic.co/cn/products/elasticsearch
**Github :**https://github.com/elastic/elasticsearch
总结:
- elasticsearch是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
- elasticsearch隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
- 支持多用户访问,多用户的环境下共享相同的系统或程序组件,并且仍可确保各用户间数据的隔离性。
突出优点:
- 扩展性好,可部署上百台服务器集群,处理PB级数据。
- 近实时的去索引数据、搜索数据。
es和solr选择哪个?
- 如果你公司现在用的solr可以满足需求就不要换了。
- 如果你公司准备进行全文检索项目的开发,建议优先考虑elasticsearch,因为像Github这样大规模的搜索都在用它.
1.2 原理与应用
1.2.1 索引结构
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。

逻辑结构部分是一个倒排索引表:
-
将要搜索的文档内容分词,所有不重复的词组成分词列表。
-
将搜索的文档最终以Document方式存储起来。
-
每个词和docment都有关联。
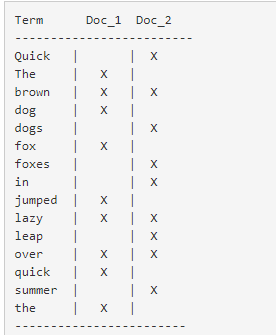
现在,如果我们想搜索 quick brown,我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,
那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
1.2.2 RESTful应用方法
Elasticsearch提供 RESTful Api接口进行索引、搜索,并且支持多种客户端。

下图是es在项目中的应用方式:

- 用户在前端搜索关键字
- 项目前端通过http方式请求项目服务端
- 项目服务端通过Http RESTful方式请求ES集群进行搜索
- ES集群从索引库检索数据。
2. ElasticaSearch 安装
2.1 安装
安装配置:
-
新版本要求至少jdk1.8以上。
-
支持tar、zip、rpm等多种安装方式。
在windows下开发建议使用ZIP安装方式。
-
支持docker方式安装
详细参见:https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
下载 ES: Elasticsearch 6.2.1,地址:https://www.elastic.co/downloads/past-releases
解压 elasticsearch-6.2.1.zip
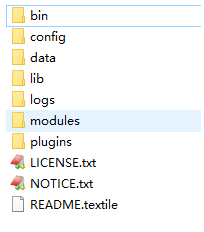
bin:脚本目录,包括:启动、停止等可执行脚本
config:配置文件目录
data:索引目录,存放索引文件的地方
logs:日志目录
modules:模块目录,包括了es的功能模块
plugins :插件目录,es支持插件机制
2.2 配置文件
2.2.1 三个配置文件
ES的配置文件的位置根据安装形式的不同而不同:
使用zip、tar安装,配置文件的地址在安装目录的config下。
使用RPM安装,配置文件在/etc/elasticsearch下。
使用MSI安装,配置文件的地址在安装目录的config下,并且会自动将config目录地址写入环境变量ES_PATH_CONF。
本教程使用的zip包安装,配置文件在ES安装目录的config下。
配置文件如下:
- elasticsearch.yml : 用于配置Elasticsearch运行参数
- jvm.options : 用于配置Elasticsearch JVM设置
- log4j2.properties: 用于配置Elasticsearch日志
2.2.2 elasticsearch.yml
配置格式是YAML,可以采用如下两种方式:
方式1:层次方式
path: data: /var/lib/elasticsearch logs: /var/log/elasticsearch
方式2:属性方式
path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch
本项目采用方式2,例子如下:
cluster.name: xuecheng
node.name: xc_node_1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
#discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: false
node.max_local_storage_nodes: 1
path.data: D:\ElasticSearch\elasticsearch‐6.2.1\data
path.logs: D:\ElasticSearch\elasticsearch‐6.2.1\logs
http.cors.enabled: true
http.cors.allow‐origin: /.*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意path.data和path.logs路径配置正确。
常用的配置项如下:
-
cluster.name:配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
-
node.name:节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
-
path.conf: 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/elasticsearch
-
path.data: 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。
-
path.logs: 设置日志文件的存储路径,默认是es根目录下的logs文件夹
-
path.plugins: 设置插件的存放路径,默认是es根目录下的plugins文件夹
-
bootstrap.memory_lock: true 设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。
-
network.host: 设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。
-
http.port: 9200 设置对外服务的http端口,默认为9200。
-
transport.tcp.port: 9300 集群结点之间通信端口
-
node.master: 指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新的master。
-
node.data: 指定该节点是否存储索引数据,默认为true。
-
discovery.zen.ping.unicast.hosts: [“host1:port”, “host2:port”, “…”] 设置集群中master节点的初始列表。
-
discovery.zen.ping.timeout: 3s 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。
-
discovery.zen.minimum_master_nodes:主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。
-
node.max_local_storage_nodes:单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1.
2.2.3 jvm.options
设置最小及最大的JVM堆内存大小,在jvm.options中设置 -Xms和-Xmx:
- 两个值设置为相等
- 将 Xmx 设置为不超过物理内存的一半。
2.2.4 log4j2.properties
日志文件设置,ES使用log4j,注意日志级别的配置。
2.2.5 系统配置
在linux上根据系统资源情况,可将每个进程最多允许打开的文件数设置大些。
su limit -n 查询当前文件数
使用命令设置 limit:
先切换到root,设置完成再切回elasticsearch用户。
sudo su
ulimit ‐n 65536
su elasticsearch
- 1
- 2
- 3
也可通过下边的方式修改文件进行持久设置
/etc/security/limits.conf
将下边的行加入此文件:
elasticsearch ‐ nofile 65536
- 1
2.3 启动ES
进入bin目录,在cmd下运行:elasticsearch.bat

浏览器输入:http://localhost:9200
{
"name": "xc_node_1",
"cluster_name": "xuecheng",
"cluster_uuid": "3BkN4p2_QhqOLHNN5jX3DQ",
"version": {
"number": "6.2.1",
"build_hash": "7299dc3",
"build_date": "2018-02-07T19:34:26.990113Z",
"build_snapshot": false,
"lucene_version": "7.2.1",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.4 head插件安装
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等,head的项目地址在https://github.com/mobz/elasticsearch-head 。
从ES6.0开始,head插件支持使得node.js运行。
- 安装node.js
- 下载head并运行
# 下载head插件
git clone git://github.com/mobz/elasticsearch-head.git
# 进入head插件目录
cd elasticsearch-head
# 安装head
npm install
# 启动
npm run start
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
运行
-
注意事项
如果浏览器报跨域请求的错误,原因是head插件作为客户端要连接ES服务(localhost:9200),此时存在跨域问题,elasticsearch默认不允许跨域访问。
解决方案:
设置elasticsearch允许跨域访问。
在config/elasticsearch.yml 后面增加以下参数:
开启cors跨域访问支持,默认为false http.cors.enabled: true #跨域访问允许的域名地址,(允许所有域名)以上使用正则 http.cors.allow-origin: /.*/
注意:将config/elasticsearch.yml另存为utf-8编码格式。
成功连接ES图示:

3. ES 快速入门
ES作为一个索引及搜索服务,对外提供丰富的REST接口,快速入门部分的实例使用head插件来测试,目的是对ES的使用方法及流程有个初步的认识。
3.1 创建索引库
ES的索引库是一个逻辑概念,它包括了分词列表及文档列表,同一个索引库中存储了相同类型的文档。它就相当于MySQL中的表,或相当于Mongodb中的集合。
关于索引这个语:
**索引(名词):**ES是基于Lucene构建的一个搜索服务,它要从索引库搜索符合条件索引数据。
例如:
创建索引库…创建表
搜索索引库…查询表
**索引(动词):**索引库刚创建起来是空的,将数据添加到索引库的过程称为索引。
例如:
添加索引…给表中添加记录
下边介绍两种创建索引库的方法,它们的工作原理是相同的,都是客户端向ES服务发送命令。
-
使用postman或curl这样的工具创建
put http://localhost:9200/索引库名称
参数:
{ "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
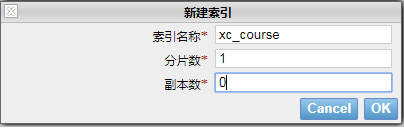
number_of_shards:设置分片的数量,在集群中通常设置多个分片,表示一个索引库将拆分成多片分别存储不同的结点,提高了ES的处理能力和高可用性,入门程序使用单机环境,这里设置为1。
number_of_replicas:设置副本的数量,设置副本是为了提高ES的高可靠性,单机环境设置为0.
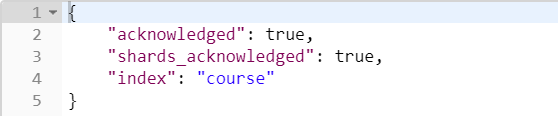
如下是创建的例子,创建course索引库,共1个分片,0个副本:

结果:
- 使用head插件创建

3.2 创建映射
3.2.1 概念说明
在索引中每个文档都包括了一个或多个field,创建映射就是向索引库中创建field的过程,下边是document和field与关系数据库的概念的类比:
文档(Document)----------------Row记录
字段(Field)-------------------Columns 列
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES官方将在ES9.0版本中彻底删除type。上边讲的创建索引库相当于关系数据库中的数据库还是表?
- 如果相当于数据库就表示一个索引库可以创建很多不同类型的文档,这在ES中也是允许的。
- 如果相当于表就表示一个索引库只能存储相同类型的文档,ES官方建议 在一个索引库中只存储相同类型的文档。
3.2.2 创建映射
我们要把课程信息存储到ES中,这里我们创建课程信息的映射,先来一个简单的映射,如下:
发送:post http://localhost:9200/索引库名称 /类型名称/_mapping
创建类型为xc_course的映射,共包括三个字段:name、description、studymondel
由于ES6.0版本还没有将type彻底删除,所以暂时把type起一个没有特殊意义的名字。
post 请求:http://localhost:9200/xc_course/doc/_mapping
表示:在 xc_course索引库下的doc类型下创建映射。doc是类型名,可以自定义,在ES6.0中要弱化类型的概念,给它起一个没有具体业务意义的名称。
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
映射创建成功,查看head界面:

3.3 创建文档
ES中的文档相当于MySQL数据库表中的记录。
发送:put 或Post http://localhost:9200/xc_course/doc/id值
(如果不指定id值ES会自动生成ID)
访问:http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
使用PostMan测试:

通过head查询数据:

3.4 搜索文档
-
根据id查询文档
发送:get http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
使用 postman测试:

-
查询所有记录
-
查询名称中包括spring 关键字的的记录
发送:get http://localhost:9200/xc_course/doc/_search?q=name:bootstrap
-
查询学习模式为201001的记录
发送 get http://localhost:9200/xc_course/doc/_search?q=studymodel:201001
查询结果分析
{ "took": 35, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "xc_course", "_type": "doc", "_id": "i5c0R2kBvET-EWpazR_T", "_score": 1, "_source": { "name": "Bootstrap开发框架", "description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。", "studymodel": "201001" } } ] } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
took:本次操作花费的时间,单位为毫秒。
timed_out:请求是否超时
_shards:说明本次操作共搜索了哪些分片
hits:搜索命中的记录
hits.total : 符合条件的文档总数 hits.hits :匹配度较高的前N个文档
hits.max_score:文档匹配得分,这里为最高分
_score:每个文档都有一个匹配度得分,按照降序排列。
_source:显示了文档的原始内容。
4. IK分词器
4.1 测试分词器
在添加文档时会进行分词,索引中存放的就是一个一个的词(term),当你去搜索时就是拿关键字去匹配词,最终找到词关联的文档。
测试当前索引库使用的分词器:
post 发送:localhost:9200/_analyze
{"text":"测试分词器,后边是测试内容:spring cloud实战"}
- 1
结果如下:

4.2 安装IK分词器
使用IK分词器可以实现对中文分词的效果。
下载IK分词器:(Github地址:https://github.com/medcl/elasticsearch-analysis-ik)
下载zip:

解压,并将解压的文件拷贝到ES安装目录的plugins下的ik目录下

测试分词效果:
发送:post localhost:9200/_analyze
{"text":"测试分词器,后边是测试内容:spring cloud实战","analyzer":"ik_max_word" }
- 1

4.3 两种分词模式
ik分词器有两种分词模式:ik_max_word和ik_smart模式。
-
ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
-
ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
测试两种分词模式:
发送: post localhost:9200/_analyze
{“text”:“中华人民共和国人民大会堂”,“analyzer”:“ik_smart” }
总结:
- 针对文档添加索引库时,最好使用ik_max_work分词,就能够获得当前文档最多的词条
- 针对搜索条件如果要分词的话,最好使用ik_smart分词,能够更贴近用户的需求.
4.4 自定义词库
如果要让分词器支持一些专有词语,可以自定义词库。
iK分词器自带一个main.dic的文件,此文件为词库文件。

在上边的目录中新建一个my.dic文件(注意文件格式为utf-8(不要选择utf-8 BOM))
可以在其中自定义词汇:
比如定义:
配置文件中配置my.dic

重启ES,测试分词效果:
发送:post localhost:9200/_analyze
{“text”:“测试分词器,后边是测试内容:spring实战”,“analyzer”:“ik_max_word” }

5. 映射
上边章节安装了ik分词器,如果在索引和搜索时去使用ik分词器呢?如何指定其它类型的field,比如日期类型、数值类型等。
本章节学习各种映射类型及映射维护方法。
5.1 映射维护方法
-
查询所有索引的映射
-
创建映射
post 请求:http://localhost:9200/xc_course/doc/_mapping
例如:
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
更新映射
映射创建成功可以添加新字段,已有字段不允许更新。
-
删除映射
通过删除索引来删除映射。
5.2 常用映射类型

字符串包括 text和keyword两种类型
5.2.1 text文本字段
-
analyzer
通过analyzer属性指定分词器。
下边指定name的字段类型为text,使用ik分词器的ik_max_word分词模式。
"name": {
"type": "text",
"analyzer":"ik_max_word"
}
- 1
- 2
- 3
- 4
-
index
通过index属性指定是否索引。
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置为false。
删除索引,重新创建映射,将pic的index设置为false,尝试根据pic去搜索,结果搜索不到数据
"pic": {
"type": "text",
"index":false
}
- 1
- 2
- 3
- 4
-
store
是否在source之外存储,每个文档索引后会在 ES中保存一份原始文档,存放在"_source"中,一般情况下不需要设置store为true,因为在_source中已经有一份原始文档了。
测试
删除xc_course/doc下的映射
创建新映射:Post http://localhost:9200/xc_course/doc/_mapping
{ "properties": { "name": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "description": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "pic": { "type": "text", "index": false }, "studymodel": { "type": "text" } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
插入文档:http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
{
"name": "Bootstrap开发框架",
"description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"pic": "group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"studymodel": "201002"
}
- 1
- 2
- 3
- 4
- 5
- 6
查询测试:
Get http://localhost:9200/xc_course/_search?q=name:开发
Get http://localhost:9200/xc_course/_search?q=description:开发
Get http://localhost:9200/xc_course/_search?q=pic:group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg
Get http://localhost:9200/xc_course/_search?q=studymodel:201002
通过测试发现: name和description都支持全文检索,pic不可作为查询条件。
5.2.2 keyword关键字字段
上边介绍的 text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
测试
更改映射:
{
"properties": {
"studymodel": {
"type": "keyword"
},
"name": {
"type": "keyword"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
插入文档:
{
"name": "java编程基础",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"pic": "group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"studymodel": "201001"
}
- 1
- 2
- 3
- 4
- 5
- 6
根据studymodel查询文档
搜索:http://localhost:9200/xc_course/_search?q=name:java
name 是keyword类型,所以查询方式是精确查询。
5.2.3 date日期类型
日期类型不用设置分词器。
通常日期类型的字段用于排序。
通过format设置日期格式。
例子:
下边的设置允许date字段存储年月日时分秒、年月日及毫秒三种格式。
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy‐MM‐ddHH:mm:ss||yyyy‐MM‐dd"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
插入文档:
Post :http://localhost:9200/xc_course/doc/3
{
"name": "spring开发基础",
"description": "spring在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic": "group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"timestamp": "2018‐07‐0418:28:58"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.2.4 数值类型
下边是ES支持的数值类型

- 尽量选择范围小的类型,提高搜索效率
- 对于浮点数尽量用比例因子,比如一个价格字段,单位为元,我们将比例因子设置为100这在ES中会按分存储,映射如下:
"price":{
"type":"scaled_float",
"scaling_factor":100
},
- 1
- 2
- 3
- 4
由于比例因子为100,如果我们输入的价格是23.45则ES中会将23.45乘以100存储在ES中。
如果输入的价格是23.456,ES会将23.456乘以100再取一个接近原始值的数,得出2346。
使用比例因子的好处是整型比浮点型更易压缩,节省磁盘空间。
如果比例因子不适合,则从下表选择范围小的去用:

更新已有映射,并插入文档:
POST:http://localhost:9200/xc_course/doc/3
{
"name": "spring开发基础",
"description": "spring在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic": "group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"timestamp": "2018‐07‐0418:28:58",
"price": 38.6
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.2.5 综合例子
post:http://localhost:9200/xc_course/doc/_mapping
{ "properties": { "description": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "name": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "pic": { "type": "text", "index": false }, "price": { "type": "float" }, "studymodel": { "type": "keyword" }, "timestamp": { "type": "date", "format": "yyyy‐MM‐ddHH:mm:ss||yyyy‐MM‐dd||epoch_millis" } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
插入文档
Post: http://localhost:9200/xc_course/doc/1
{
"name": "Bootstrap 开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"studymodel": "201002",
"price": 38.6,
"timestamp": "2018-04-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6 集群管理
6.1 集群结构
ES通常以集群方式工作,这样做不仅能够提高 ES的搜索能力还可以处理大数据搜索的能力,同时也增加了系统的索能力还可以处理大数据搜索的能力,同时也增加了系统的容错能力及高可用,ES可以实现PB级数据的搜索。
下图是ES集群结构的示意图:

从上图总结以下概念:
-
结点
ES集群由多个服务器组成,每个服务器即为一个Node结点(该服务只部署了一个ES进程)。
-
分片
当我们的文档量很大时,由于内存和硬盘的限制,同时也为了提高ES的处理能力、容错能力及高可用能力,我们将索引分成若干分片,每个分片可以放在不同的服务器,这样就实现了多个服务器共同对外提供索引及搜索服务。
一个搜索请求过来,会分别从各各分片去查询,最后将查询到的数据合并返回给用户。
-
副本
为了提高ES的高可用同时也为了提高搜索的吞吐量,我们将分片复制一份或多份存储在其它的服务器,这样即使当前的服务器挂掉了,拥有副本的服务器照常可以提供服务。
-
主结点
一个集群中会有一个或多个主结点,主结点的作用是集群管理,比如增加节点,移除节点等,主结点挂掉后ES会重新选一个主结点。
-
结点转发
每个结点都知道其它结点的信息,我们可以对任意一个结点发起请求,接收请求的结点会转发给其它结点查询数据。
6.2 搭建集群
下边的例子实现创建一个2结点的集群,并且索引的分片我们设置2片,每片一个副本。
6.2.1 结点的三个角色
-
主结点:master节点主要用于集群的管理及索引 比如新增结点、分片分配、索引的新增和删除等。
-
数据结点:data 节点上保存了数据分片,它负责索引和搜索操作。
-
客户端结点:client 节点仅作为请求客户端存在,client的作用也作为负载均衡器,client 节点不存数据,只是将请求均衡转发到其它结点。
通过下边两项参数来配置结点的功能:
node.master: #是否允许为主结点
node.data: #允许存储数据作为数据结点
node.ingest: #是否允许成为协调节点,
四种组合方式:
master=true,data=true:即是主结点又是数据结点
master=false,data=true:仅是数据结点
master=true,data=false:仅是主结点,不存储数据
master=false,data=false:即不是主结点也不是数据结点,此时可设置ingest为true表示它是一个客户端。
6.2.2 创建结点 -1
解压elasticsearch-6.2.1.zip 到 F:\devenv\elasticsearch\es-cloud-1\elasticsearch-6.2.1
结点1对外服务的http端口是:9200
集群管理端口是9300
配置elasticsearch.yml
结点名:node_1
elasticsearch.yml内容如下
cluster.name: node
node.name: node_1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301"]
discovery.zen.minimum_master_nodes: 1
node.ingest: true
node.max_local_storage_nodes: 2
path.data: D:\ElasticSearch\elasticsearch‐6.2.1‐1\data
path.logs: D:\ElasticSearch\elasticsearch‐6.2.1‐1\logs
http.cors.enabled: true
http.cors.allow‐origin: /.*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
启动结点1
6.2.3 创建结点-2
解压elasticsearch-6.2.1.zip 到 F:\devenv\elasticsearch\es-cloud-2\elasticsearch-6.2.1
结点1对外服务的http端口是:9201
集群管理端口是9302
结点名:node_2
elasticsearch.yml内容如下
cluster.name: node
node.name: node_2
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9301
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301"]
discovery.zen.minimum_master_nodes: 1
node.ingest: true
node.max_local_storage_nodes: 2
path.data: D:\ElasticSearch\elasticsearch‐6.2.1‐2\data
path.logs: D:\ElasticSearch\elasticsearch‐6.2.1‐2\logs
http.cors.enabled: true
http.cors.allow‐origin: /.*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
启动结点2
6.2.4 创建索引库
- 使用head连上其中一个结点

上图表示两个结点已经创建成功。
- 下边创建索引库,共2个分片,每个分片一个副本。
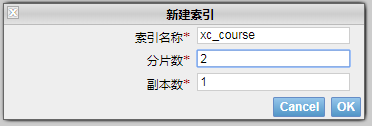
创建成功,刷新head:

上图可以看到共有4个分片,其中两个分片是副本。
6.2.5 集群的健康
通过访问 GET /_cluster/health 来查看Elasticsearch 的集群健康情况。
用三种颜色来展示健康状态: green 、 yellow 或者 red 。
- green:所有的主分片和副本分片都正常运行。
- yellow:所有的主分片都正常运行,但有些副本分片运行不正常。
- red:存在主分片运行不正常。
Get请求:http://localhost:9200/_cluster/health
响应结果:
{ "cluster_name": "node", "status": "green", "timed_out": false, "number_of_nodes": 2, "number_of_data_nodes": 2, "active_primary_shards": 2, "active_shards": 4, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 0, "delayed_unassigned_shards": 0, "number_of_pending_tasks": 0, "number_of_in_flight_fetch": 0, "task_max_waiting_in_queue_millis": 0, "active_shards_percent_as_number": 100 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.3 测试
-
创建映射并写入文档
连接 其中任意一台结点,创建映射写入文档。
{
"name": "spring开发基础",
"description": "spring在java领域非常流行,java软件开发人员都在用。",
"studymodel": "201001",
"price": 66.6
}
- 1
- 2
- 3
- 4
- 5
- 6
响应结果:
{
"_index": "xc_course",
"_type": "doc",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
从上边的提示可看出,两个分片都保存成功。
-
搜索
向其它一个结点发起搜索请求,查询全部数据。
-
关闭一个结点
ES会重新选中一个主结点(前提在配置结点时允许它可以为主结点)

此时向活的结点发起搜索请求,仍然正常。
-
添加一个结点
添加结点3,端口设置为:
http端口是:9202
集群管理端口:9302
结点名:node_3
此结点的配置:
node.master: false node.data: true
启动结点3,刷新head,下图显示ES将分片分在了3个结点

向结点 3发起搜索请求:
Get: http://127.0.0.1:9202/course/doc/_search
全部数据可被正常搜索到。


{kind=link}