
- 1redis深入学习-05—redis中scan的用法_redis scan 匹配用法
- 2CentOS停服倒计时不到一个月喊话:“国产操作系统准备好了吗?”安排!_centos停止维护
- 3Mac本地安装部署Stable diffusion最全教程,AI绘画无痛入门指南_stable diffusion mac版
- 4ubuntu20.04系统4060安装cuda11.8和cudnn8.6_ubuntu安装cuda11.8
- 5Elasticsearch Aggregations使用总结_es aggregation 分页
- 6吴恩达深度解析Agent的四种工作方式
- 7菜鸟学习python之旅---基础入门(2)--- Python 运算符_a=9b=20编写运算符号
- 8小美的平衡矩阵
- 9uniapp开发微信小程序:提交审核不通过,提示AppSecret存在泄漏的安全风险。解决思路。_app代码中不应存在appsecret
- 10Android中View(视图)绘制不同状态背景图片原理深入分析以及StateListDrawable使用详解_使用statelistdrawable用户资源,显示不同状态的图片和文字颜色
聚类篇——(二)K-means聚类_kmeans聚类问题描述
赞
踩
上一篇博文介绍了什么是聚类分析以及其应用场景,本篇博文详细介绍常用聚类算法之一K-means聚类,将从以下几个方面展开介绍:
- K-means聚类基本思想及其优缺点,初步了解K-means聚类;
- K-means聚类逻辑计算过程,了解其内部实现逻辑;
- K-means聚类初始中心点选择的合理性,会直接影响聚类收敛和效果,详细介绍最大距离法、最大最小距离法、Huffman树三种确定初始中心点的方法;
- K-means聚类应用示例。
1. K-means聚类概述
K-means聚类也称快速聚类,属于覆盖型数值划分聚类算法。它得到的聚类结果,每个样本点都唯一属于一个类,而且聚类变量为数值型,并采用划分原理进行聚类。K-means聚类涉及两个主要方面的问题:第一,如何测度样本的“亲疏程度”;第二,如何进行聚类。
K-means聚类的基本思想:参数K用以决定结果中簇的数目,算法开始时,要在数据集中随机选择K个数据对象用来当做K个簇的初始中心,而将剩下的各个数据对象根据他们和每个聚类簇心的距离选择簇心最近的簇分配到其中。然后重新计算各个聚类簇中的所有数据对象的平均值,并将得到的结果作为新的簇心;逐步重复上述过程直至目标函数收敛为止。

K-means聚类算法的优缺点
- 优点:K均值算法伸缩性良好,且针对大型数据集效率高。
- 缺点:(1)初始聚类中心选择的好与坏将会对聚类结果的质量产生很大影响;(2)算法很容易陷入局部最优解,有时会产生较差的结果;(3)算法开始时要求用户给出聚类簇的个数K,而对于K值的选择还没有很好的准则可循;(4)对噪声敏感;(5)只能在可以定义聚类的平均值的条件下才可以应用,即适合处理数值属性的数据; (6)采用欧式距离来测量样本间的亲疏程度,没有考虑变量间的相关性,因此算法对变量间的相关性极度敏感,在聚类分析前需要对变量进行相关性分析。
2. K-means聚类逻辑计算过程
第一步,指定聚类数目K。
在K-means聚类中,应首先给出需聚成多少类。聚类数目的确定本身并不简单,既要考虑最终的聚类效果,也要根据研究问题的实际需要。聚类数目太大或太小都将失去聚类的意义。
第二步,确定K个初始类中心。
类中心是各类特征的典型代表,指定聚类数目K后,还应指定K个类的初始类中心点。初始类中心点指定的合理性,将直接影响聚类收敛的速度。常用的初始类中心点的指定方法为经验选择法、随机选择法、最大最小法、最大距离法、Huffman树法(后面详细介绍)。
第三步,根据最近原则进行聚类。
依次计算每个数据点到K个类中心点的欧式距离,并按照距K个中心点距离最近的原则,将所有样本划分到最近的类中,形成K个类。其中欧式距离为
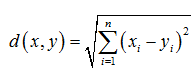
第四步,重新确定K个类中心。
中心点的确定原则是,依次计算各类中所有数据点变量的均值,并以均值点作为K个类中心,其计算公式为
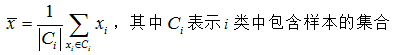
第五步,聚类终止。
判断是否已经满足终止聚类的条件,如果没有满足则返回到第三步,不断反复上述过程,直到满足迭代终止条件。聚类终止的条件:
- 迭代次数。当目前迭代次数等于指定的迭代次数时终止聚类;
- 目标函数收敛。其中目标函数为

即各样本到其所在类中心点的离差平方和小于某个指定值,即目标函数收敛,聚类终止。
3. K-means聚类初始中心点确定方法
由于K-均值算法初始中心点选取的随机性,可能出现选取的聚类种子过于邻近的情况,而导致聚类结果效果不好,也易陷入局部极小点。即初始类中心点指定的合理性,将直接影响聚类收敛的速度和效果。下面详细介绍确定初始聚类中心点的三种方法:最大距离法、最大最小法、Huffman树法。
(i)最大距离法
最大距离法是模式识别领域中一种基于试探的算法,思想是取尽可能离得远的对象作为聚类中心,提高了划分初始数据集的效率。最大距离法具体步骤为:
设
n
n
n个数据对象,其中每个数据对象为
d
d
d维,将
n
n
n个数据对象聚成
k
k
k类。
(1)有n 个样本
S
n
=
x
1
,
x
2
,
⋯
,
x
n
S_n={x_1,x_2,⋯,x_n }
Sn=x1,x2,⋯,xn ,计算每两点间的欧式距离,选取距离最大的两点
p
,
q
p,q
p,q,
d
p
q
=
max
{
d
i
j
,
i
,
j
∈
1
,
2
,
⋯
,
n
}
{{d}_{pq}}=\max \left\{ {{d}_{ij}},i,j\in 1,2,\cdots ,n \right\}
dpq=max{dij,i,j∈1,2,⋯,n},记
x
1
∗
=
p
,
x
2
∗
=
q
,
d
1
∗
=
d
p
q
x_{1}^{*}=p,x_{2}^{*}=q,d_{1}^{*}={{d}_{pq}}
x1∗=p,x2∗=q,d1∗=dpq ;
(2)将数据 S n S_n Sn中剩余的 n − 2 n-2 n−2个样本,以 x 1 ∗ x_{1}^{*} x1∗ 和 x 2 ∗ x_{2}^{*} x2∗ 为中心进行聚类,若 d i 1 < d i 2 , {{d}_{i1}}<{{d}_{i2}}, di1<di2, ∀ i ∈ { 1 , 2 , 3 , ⋯ , n / p , q } \forall i\in \left\{ 1,2,3,\cdots ,n/p,q \right\} ∀i∈{1,2,3,⋯,n/p,q},则将 x i {{x}_{i}} xi归于 x 1 ∗ x_{1}^{*} x1∗,否则归于 x 2 ∗ x_{2}^{*} x2∗,这样将 S n {{S}_{n}} Sn以 x 1 ∗ x_{1}^{*} x1∗和 x 2 ∗ x_{2}^{*} x2∗为中心分为两类;
(3)在已经聚成的
c
c
c个类中找出每个类中离中心点最远的点,这样就得到
c
c
c个点,在这
c
c
c个点中每次取一个点,与已经得到的
c
c
c个类的中心点组合成
c
+
1
c+1
c+1个点,把
S
n
{{S}_{n}}
Sn聚成
c
+
1
c+1
c+1个类,这样我们得到了
S
n
{{S}_{n}}
Sn的
c
c
c个不同划分,并分别计算
c
c
c个划分的准则函数,准则函数最小的那个划分为最优划分,并将形成最优划分的那个点作为第
c
+
1
c+1
c+1个中心点。
准则函数:
∑
i
=
1
k
∑
x
∈
C
i
d
i
s
t
(
C
i
,
x
i
)
2
\sum\limits_{i=1}^{k}{\sum\limits_{x\in {{C}_{i}}}{dist{{\left( {{C}_{i}},{{x}_{i}} \right)}^{2}}}}
i=1∑kx∈Ci∑dist(Ci,xi)2,对象到其簇质心的距离平方和;
(4)重复(3),直到找到 k k k 个聚类中心为止。
下面结合具体实例来详细说明最大距离算法来选取初始中心点的过程。
共有15个数据对象
(
x
1
,
x
2
,
⋯
,
x
15
)
\left( {{x}_{1}},{{x}_{2}},\cdots ,{{x}_{15}} \right)
(x1,x2,⋯,x15),
{
(
5
,
6
)
;
(
6
,
6
)
;
(
5
,
5
)
;
(
2
,
4
)
;
(
3
,
4
)
;
(
2
,
3
)
;
(
1
,
2
)
;
(
1
,
1
)
;
\left\{ \left( 5,6 \right);\left( 6,6 \right);\left( 5,5 \right);\left( 2,4 \right);\left( 3,4 \right);\left( 2,3 \right);\left( 1,2 \right); \right.\left( 1,1 \right);
{(5,6);(6,6);(5,5);(2,4);(3,4);(2,3);(1,2);(1,1);
(
2
,
2
)
;
(
5
,
1
)
;
(
5
,
2
)
;
(
6
,
3
)
;
(
6
,
2
)
;
(
6
,
1
)
;
(
6
,
0
)
}
\left( 2,2 \right);\left( 5,1 \right);\left( 5,2 \right);\left( 6,3 \right);\left. \left( 6,2 \right);\left( 6,1 \right);\left( 6,0 \right) \right\}
(2,2);(5,1);(5,2);(6,3);(6,2);(6,1);(6,0)},要将这15个点聚成3个类,具体步骤如下:
- 根据欧式距离求得
(
x
1
,
x
2
,
⋯
,
x
15
)
\left( {{x}_{1}},{{x}_{2}},\cdots ,{{x}_{15}} \right)
(x1,x2,⋯,x15)每两点间的距离,找出距离最远的两点
x
2
(
6
,
6
)
{{x}_{2}}\left( 6,6 \right)
x2(6,6),
x
8
(
1
,
1
)
{{x}_{8}}\left( 1,1 \right)
x8(1,1),
d
28
=
7.07
{{d}_{28}}=7.07
d28=7.07,令
x
1
∗
=
x
2
x_{1}^{*}={{x}_{2}}
x1∗=x2,
x
2
∗
=
x
8
x_{2}^{*}={{x}_{8}}
x2∗=x8;

- 以 x 2 {{x}_{2}} x2, x 8 {{x}_{8}} x8为聚类中心,依次比较 x 1 , x 2 , x 3 , x 4 , x 5 , x 6 , x 7 , x 8 , x 9 , x 10 , x 11 , x 12 , x 13 , x 14 , x 15 {{x}_{1}},{{x}_{2}},{{x}_{3}},{{x}_{4}},{{x}_{5}},{{x}_{6}},{{x}_{7}},{{x}_{8}},{{x}_{9}},{{x}_{10}},{{x}_{11}},{{x}_{12}},{{x}_{13}},{{x}_{14}},{{x}_{15}} x1,x2,x3,x4,x5,x6,x7,x8,x9,x10,x11,x12,x13,x14,x15到 x 2 , x 8 {{x}_{2}},{{x}_{8}} x2,x8的欧式距离 d i 2 , d i 8 {{d}_{i2}},{{d}_{i8}} di2,di8,若 d i 2 < d i 8 {{d}_{i2}}<{{d}_{i8}} di2<di8则归为 x 1 ∗ x_{1}^{*} x1∗,否则归为 x 2 ∗ x_{2}^{*} x2∗,最终将数据聚成两类, S 21 ∗ = { x 1 , x 2 , x 3 , x 12 , x 11 , x 13 , x 14 } S_{21}^{*}=\left\{ {{x}_{1}},{{x}_{2}},{{x}_{3}},{{x}_{12}},{{x}_{11}},{{x}_{13}},{{x}_{14}} \right\} S21∗={x1,x2,x3,x12,x11,x13,x14}, S 22 ∗ = { x 4 , x 5 , x 6 , x 7 , x 8 , x 9 , x 10 , x 15 } S_{22}^{*}=\left\{ {{x}_{4}},{{x}_{5}},{{x}_{6}},{{x}_{7}},{{x}_{8}},{{x}_{9}},{{x}_{10}},{{x}_{15}} \right\} S22∗={x4,x5,x6,x7,x8,x9,x10,x15};
- S 21 ∗ S_{21}^{*} S21∗中距离中心点 x 2 {{x}_{2}} x2最远的点为 x 14 {{x}_{14}} x14, S 22 ∗ S_{22}^{*} S22∗中离中心点 x 8 {{x}_{8}} x8最远的点为 x 15 {{x}_{15}} x15;
- 分别用
{
x
2
,
x
8
,
x
14
}
\left\{ {{x}_{2}},{{x}_{8}},{{x}_{14}} \right\}
{x2,x8,x14}和
{
x
2
,
x
8
,
x
15
}
\left\{ {{x}_{2}},{{x}_{8}},{{x}_{15}} \right\}
{x2,x8,x15}把15个对象聚成3类,并分别计算得到
{
x
2
,
x
8
,
x
14
}
\left\{ {{x}_{2}},{{x}_{8}},{{x}_{14}} \right\}
{x2,x8,x14}和
{
x
2
,
x
8
,
x
15
}
\left\{ {{x}_{2}},{{x}_{8}},{{x}_{15}} \right\}
{x2,x8,x15}聚类结果的准则函数值分别为43和55, 可知以
{
x
2
,
x
8
,
x
14
}
\left\{ {{x}_{2}},{{x}_{8}},{{x}_{14}} \right\}
{x2,x8,x14}为中心点得到的聚类结果更优。

(ii)最大最小距离法
最大最小距离算法的基本思想是取尽可能离得远的对象作为初始聚类中心,得到对数据集较好的初始划分,目的是避免K-means聚类算法初值选取的聚类中心过于邻近,多个聚类中心都被选择在同一个类中。最大最小距离法的具体步骤为:
设数据集为
S
=
{
X
1
,
X
2
,
X
3
,
⋯
,
X
n
}
S=\left\{ {{X}_{1}},{{X}_{2}},{{X}_{3}},\cdots ,{{X}_{n}} \right\}
S={X1,X2,X3,⋯,Xn},初始聚类中心集为
V
=
{
V
1
,
V
2
,
⋯
,
V
m
}
V=\left\{ {{V}_{1}},{{V}_{2}},\cdots ,{{V}_{m}} \right\}
V={V1,V2,⋯,Vm},对象间的相异度是基于欧式距离度量的。
(1) 从数据集
S
S
S中任意选取一个数据对象,将其作为第一个聚类中心点
v
1
{{v}_{1}}
v1,并将其放入
V
V
V中;
(2) 计算 v 1 {{v}_{1}} v1和数据集 S S S中剩余的所有数据对象之间的距离,把距离最远的数据对象放入 V V V中,将其作为第二个聚类中心点 v 2 {{v}_{2}} v2;
(3) 计算数据集 S S S中剩余的所有数据对象 X i {{X}_{i}} Xi,分别计算到 v 1 {{v}_{1}} v1和 v 2 {{v}_{2}} v2的距离 d i 1 {{d}_{i1}} di1和 d i 2 {{d}_{i2}} di2,选择其中较小的距离 m i n ( d i 1 , d i 2 ) min\left( {{d}_{i1}},{{d}_{i2}} \right) min(di1,di2),即找到剩余每个对象到已有聚类中心最近的距离;
(4) 计算 m i n ( d i 1 , d i 2 ) min\left( {{d}_{i1}},{{d}_{i2}} \right) min(di1,di2)的最大值,即 max ( m i n ( d i 1 , d i 2 ) ) \max \left( min\left( {{d}_{i1}},{{d}_{i2}} \right) \right) max(min(di1,di2)),与其对应的数据 X i {{X}_{i}} Xi即为第三个聚类中心 v 3 {{v}_{3}} v3;
(5) 假设已找到 r ( r < k ) r\left( r<k \right) r(r<k)个聚类中心 { v i , i = 1 , 2 , ⋯ , r } \left\{ {{v}_{i}},i=1,2,\cdots ,r \right\} {vi,i=1,2,⋯,r},现在确定第 r + 1 r+1 r+1个聚类中心, max { min ( d i 1 , d i 2 , ⋯ , d i r ) } , i = 1 , 2 , ⋯ , N \max \left\{ \min \left( {{d}_{i1}},{{d}_{i2}},\cdots ,{{d}_{ir}} \right) \right\},i=1,2,\cdots ,N max{min(di1,di2,⋯,dir)},i=1,2,⋯,N所对应的数据 X i {{X}_{i}} Xi即为第 r + 1 r+1 r+1个聚类中心;
(6) 重复第(5)步,直到
r
+
1
=
k
r+1=k
r+1=k为止。
说明:(1)~(2)步可以用最大距离法中的第(1)步进行简化,选取距离最远的两个对象。
下面给出一个具体实例来详细说明最大距离算法的过程,
共有10个点
(
x
1
,
x
2
,
⋯
,
x
10
)
\left( {{x}_{1}},{{x}_{2}},\cdots ,{{x}_{10}} \right)
(x1,x2,⋯,x10),具体步骤如下:
- 任选一个点作为第一个聚类中心, v 1 = x 1 {{v}_{1}}={{x}_{1}} v1=x1,坐标为 ( 0 , 0 ) \left( 0,0 \right) (0,0);
- 在剩余点中计算到 v 1 {{v}_{1}} v1距离最大的点作为第二个类的聚类中心, v 2 = x 5 {{v}_{2}}={{x}_{5}} v2=x5;
- 计算剩余点到
v
1
{{v}_{1}}
v1、
v
2
{{v}_{2}}
v2的最小距离;
x 2 {{x}_{2}} x2: min ( ∣ x 2 − v 1 ∣ , ∣ x 2 − v 2 ∣ ) = ∣ x 2 − v 1 ∣ \min \left( \left| {{x}_{2}}-{{v}_{1}} \right|,\left| {{x}_{2}}-{{v}_{2}} \right| \right)=\left| {{x}_{2}}-{{v}_{1}} \right| min(∣x2−v1∣,∣x2−v2∣)=∣x2−v1∣
x 3 {{x}_{3}} x3: min ( ∣ x 3 − v 1 ∣ , ∣ x 3 − v 2 ∣ ) = ∣ x 3 − v 1 ∣ \min \left( \left| {{x}_{3}}-{{v}_{1}} \right|,\left| {{x}_{3}}-{{v}_{2}} \right| \right)=\left| {{x}_{3}}-{{v}_{1}} \right| min(∣x3−v1∣,∣x3−v2∣)=∣x3−v1∣
x 4 {{x}_{4}} x4: min ( ∣ x 4 − v 1 ∣ , ∣ x 4 − v 2 ∣ ) = ∣ x 4 − v 2 ∣ \min \left( \left| {{x}_{4}}-{{v}_{1}} \right|,\left| {{x}_{4}}-{{v}_{2}} \right| \right)=\left| {{x}_{4}}-{{v}_{2}} \right| min(∣x4−v1∣,∣x4−v2∣)=∣x4−v2∣
x 6 {{x}_{6}} x6: min ( ∣ x 6 − v 1 ∣ , ∣ x 6 − v 2 ∣ ) = ∣ x 6 − v 2 ∣ \min \left( \left| {{x}_{6}}-{{v}_{1}} \right|,\left| {{x}_{6}}-{{v}_{2}} \right| \right)=\left| {{x}_{6}}-{{v}_{2}} \right| min(∣x6−v1∣,∣x6−v2∣)=∣x6−v2∣
x 7 {{x}_{7}} x7: min ( ∣ x 7 − v 1 ∣ , ∣ x 7 − v 2 ∣ ) = ∣ x 7 − v 2 ∣ \min \left( \left| {{x}_{7}}-{{v}_{1}} \right|,\left| {{x}_{7}}-{{v}_{2}} \right| \right)=\left| {{x}_{7}}-{{v}_{2}} \right| min(∣x7−v1∣,∣x7−v2∣)=∣x7−v2∣
x 8 {{x}_{8}} x8: min ( ∣ x 8 − v 1 ∣ , ∣ x 8 − v 2 ∣ ) = ∣ x 8 − v 2 ∣ \min \left( \left| {{x}_{8}}-{{v}_{1}} \right|,\left| {{x}_{8}}-{{v}_{2}} \right| \right)=\left| {{x}_{8}}-{{v}_{2}} \right| min(∣x8−v1∣,∣x8−v2∣)=∣x8−v2∣
x 9 {{x}_{9}} x9: min ( ∣ x 9 − v 1 ∣ , ∣ x 9 − v 2 ∣ ) = ∣ x 9 − v 2 ∣ \min \left( \left| {{x}_{9}}-{{v}_{1}} \right|,\left| {{x}_{9}}-{{v}_{2}} \right| \right)=\left| {{x}_{9}}-{{v}_{2}} \right| min(∣x9−v1∣,∣x9−v2∣)=∣x9−v2∣
x 10 {{x}_{10}} x10: min ( ∣ x 10 − v 1 ∣ , ∣ x 10 − v 2 ∣ ) = ∣ x 10 − v 2 ∣ \min \left( \left| {{x}_{10}}-{{v}_{1}} \right|,\left| {{x}_{10}}-{{v}_{2}} \right| \right)=\left| {{x}_{10}}-{{v}_{2}} \right| min(∣x10−v1∣,∣x10−v2∣)=∣x10−v2∣ - 计算
max ( ∣ x 2 − v 1 ∣ , ∣ x 3 − v 1 ∣ , ∣ x 4 − v 2 ∣ , ∣ x 6 − v 2 ∣ , ∣ x 7 − v 2 ∣ , ∣ x 8 − v 2 ∣ , ∣ x 9 − v 2 ∣ , ∣ x 10 − v 2 ∣ ) = ∣ x 9 − v 2 ∣ \max \left( \left| {{x}_{2}}-{{v}_{1}} \right|,\left| {{x}_{3}}-{{v}_{1}} \right|,\left| {{x}_{4}}-{{v}_{2}} \right|,\left| {{x}_{6}}-{{v}_{2}} \right|,\left| {{x}_{7}}-{{v}_{2}} \right|,\left| {{x}_{8}}-{{v}_{2}} \right|,\left| {{x}_{9}}-{{v}_{2}} \right|,\left| {{x}_{10}}-{{v}_{2}} \right| \right) =\left| {{x}_{9}}-{{v}_{2}} \right| max(∣x2−v1∣,∣x3−v1∣,∣x4−v2∣,∣x6−v2∣,∣x7−v2∣,∣x8−v2∣,∣x9−v2∣,∣x10−v2∣)=∣x9−v2∣
因此,第三个初始聚类中心的候选对象为 x 9 {{x}_{9}} x9,坐标 ( 6 , 3 ) \left( 6,3 \right) (6,3);

(iii)Huffman树
Huffman树简单的说就是带权路径长度之和最小的二叉树也称最优二叉树。给定n个数据点的权值,构造Huffman树的算法描述如下:
(1) 根据n个给定的权值
{
w
1
,
w
2
,
⋯
,
w
n
}
\left\{ {{w}_{1}},{{w}_{2}},\cdots ,{{w}_{n}} \right\}
{w1,w2,⋯,wn},构成n棵二叉树的集合
F
=
{
T
1
,
T
2
,
⋯
,
T
n
}
F=\left\{ {{T}_{1}},{{T}_{2}},\cdots ,{{T}_{n}} \right\}
F={T1,T2,⋯,Tn},每棵二叉树
T
i
{{T}_{i}}
Ti只有根节点;
(2) 在 F F F中选两棵根节点权值最小的树作为左右子树,构造一棵二叉树,新的二叉树根节点的权值等于其左右子树根节点权值之和;
(3) 在 F F F中删除这两棵子树,同时将新得到的二叉树加入 F F F中;
(4) 重复(2)和(3),直到 F F F中只剩一棵树为止。
基于Huffman树思想确实K-均值聚类的初始聚类中心具体步骤如下:
(1) 根据Huffman树的思想,采用欧式距离计算各数据点之间的相异度,对于构造树时,采用左右结点的算术平均值作为新的二叉树根结点的值(也可以采用左右子树根节点权值之和作为新的二叉树根结点);
(2) 对于构造出来的Huffman树,按构造结点的逆序找到 k − 1 k-1 k−1个结点,根据图论理论克制,去掉这 k − 1 k-1 k−1个结点可将该树分为 k k k个子树,这 k k k个子树的平均值即初始的 k k k个聚类中心。
下面举例说明构造树并得到初始中心的过程。假设有一组一维数据集 ( x 1 , x 2 , ⋯ , x 6 ) \left( {{x}_{1}},{{x}_{2}},\cdots ,{{x}_{6}} \right) (x1,x2,⋯,x6),它们对应的权值为 ( 12 , 34 , 56 , 78 , 8 , 98 ) \left( 12,34,56,78,8,98 \right) (12,34,56,78,8,98),需要将这六个点聚成3类,具体过程如下:
- 首先根据欧式距离计算6个对象之间的相异度,得到相异度矩阵;
- 找到矩阵中最小值即4,也就是数据点
x
1
(
12
)
,
x
5
(
8
)
{{x}_{1}}\left( 12 \right),{{x}_{5}}\left( 8 \right)
x1(12),x5(8)的相异度,计算这两个点的算术平均值为
x
11
=
x
1
+
x
5
2
=
10
{{x}_{11}}=\frac{{{x}_{1}}+{{x}_{5}}}{2}=10
x11=2x1+x5=10,并作为
x
1
,
x
5
{{x}_{1}},{{x}_{5}}
x1,x5的中间节点加入树。在数据集中删掉
x
1
,
x
5
{{x}_{1}},{{x}_{5}}
x1,x5,并将
x
11
{{x}_{11}}
x11加入到数据集得到新的数据集
(
x
11
,
x
2
,
x
3
,
x
4
,
x
6
)
\left( {{x}_{11}},{{x}_{2}},{{x}_{3}},{{x}_{4}},{{x}_{6}} \right)
(x11,x2,x3,x4,x6)对应的权值为
(
10
,
34
,
56
,
78
,
98
)
\left( 10,34,56,78,98 \right)
(10,34,56,78,98),计算它们的相异度矩阵;

- 重复第(2)步直到数据集中只剩下一个对象,剩下的迭代过程相异度矩阵变化如下。

- 将数据集聚成3类,即
k
=
3
k=3
k=3在已构造的树中按节点构造的逆序找出
k
−
1
k-1
k−1个点,即57.75和27.5,去掉这两点即可将构造树分为3个子树
(
x
1
,
x
5
)
(
x
2
,
x
3
)
(
x
4
,
x
6
)
\left( {{x}_{1}},{{x}_{5}} \right)\left( {{x}_{2}},{{x}_{3}} \right)\left( {{x}_{4}},{{x}_{6}} \right)
(x1,x5)(x2,x3)(x4,x6)对应树中
(
8
,
12
)
(
34
,
56
)
(
78
,
98
)
\left( 8,12 \right)\left( 34,56 \right)\left( 78,98 \right)
(8,12)(34,56)(78,98)。三个子树的平均值10,45,88即为3个簇的初始中心点。

4. K-means聚类应用示例
为研究不同地区的经济发展特点,根据各地区GDP、GDP指数、人均GDP指标数据,将北京市、天津市、江苏省等10个地区按照其经济水平分成3类。

- 对数据进行标准化,消除因指标量纲不同对聚类结果的影响。采用正向极差化法,公式如下:
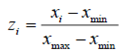

- 采用欧式距离,计算样本间亲疏程度;
两个样本之间的欧氏距离是样本各个变量值之差的平方和的平方根,计算公式为
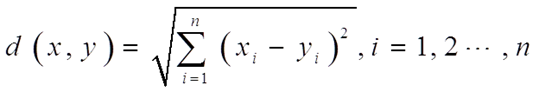
其中样本 x = ( x 1 , x 2 , . . . , x n ) , y = ( y 1 , y 2 , . . . , y n ) x=(x_1,x_2,...,x_n),y=(y_1,y_2,...,y_n) x=(x1,x2,...,xn),y=(y1,y2,...,yn) 。使用前一般需要将数据标准化,距离越大,差异度越大。 - 分别运用最大距离法、HUFFMAN树、最大最小距离法确定初始聚类中心;不同的方法得到的初始聚类中心不同。

- 运用SPSS,将上述初始聚类中心依次导入,分别进行聚类;

初始聚类中心的选择会对聚类结果产生一定影响。运用最大距离法、最大最小距离法确定初始聚类中心虽然不同,但是最终的聚类结果却是一样的;运用HUFFMAN树得到的初始聚类中心与其他两种方法不同,最终的聚类结果也有所差异。
总结
K-Means是聚类算法中最常用的一种,算法最大的特点是简单,好理解,运算速度快。但是,只能应用于连续型的数据;并且初始聚类中心选择的好与坏将会对聚类结果的质量产生很大影响;另外,对于聚类数K值的选择还没有很好的准则可循。所以,在实际应用中,要多次调整聚类数K值、初始聚类中心点等参数,结合自己的业务知识选择一个较优的结果。
ps:初衷是通过撰写博文记录自己所学所用,实现知识的梳理与积累;将其分享,希望能够帮到面临同样困惑的小伙伴儿。如发现博文中存在问题,欢迎随时交流~~

