
- 1Gartner发布中国采用GhatGPT等生成式AI应用的安全问答_gartner智能问答
- 2AIgents时代 - (二.) Agents 能力解密_agent react 推理
- 3物联网实战--驱动篇之(五)TEA和AES加密算法_tea aes谁安全
- 49道软件测试面试题,刷掉90%的软件测试员_设计测试用例,这是一个n选一宝箱,玩家不会直接获得奖励
- 5AI绘画:Stable Diffusion的高效操作界面,ComfyUI:安装和使用篇_comfyui_custom_nodes_alekpet
- 6智能零售柜商品识别从零开始使用YOLOv5+PyQt5+OpenCV实现(支持图片、视频、摄像头实时检测)_零售柜ai动态识别算法
- 7Linux在线终端模拟器_linux在线模拟器
- 8【Git】 使用问题记录_git push密码错误
- 91000道 Java面试题及答案整理(2023最新版)_java面试题大全及答案2023
- 10基于多目标粒子群算法的综合能源优化问题 建立了含冷热电的综合能源系统
Transformer量化部署初步探讨_transformer 部署
赞
踩
随着transformer模型在各个领域大杀四方,包括我常接触的检测,追踪,语音识别等各种领域都取得了远超先辈的成就,因此,开始有越来越多的厂商讨论如何将transformer模型部署起来,但是我们都知道,由于transformer中有大量的matmul等操作,致使其计算量远超普通的cnn网络,给部署带来困难(这部分后面再说)。
综上考虑,我们大致介绍一下部署方面的点
Transformer模型部署方式
目前大家框架各种各样,据我了解总结下来大致分为这么几种:
1. mnn等
这种方式看到一篇写的不错也比较详细的文章:
记录使用 Swin Transformer主干网络去实现分类,并转化NCNN、TNN、MNN模型以及部署
但是这种方式更多的比较常用于手机等arm端,对于很多比如fpga,npu等嵌入式场景支持比较少(只是比较少,不是不支持奥)
2. TurboTransformers
同样是腾讯开源的一款非常不错的工具,本人已经亲测了,各方面都还不错。
怎么说呢,turbotransformers可以说是一个专为transformer定制化的工具,我们都知道mnn这些工具都是首先把encoder转成matmul,softmax等一个个算子的组合,然后再顺序执行。
而turbotransformers可以简单理解为把整个encoder或者decoder等看成一整个算子(你可以简单这么理解哈哈),内部使用指令集及存取优化等对这个算子进行优化,这样就消除了算子与算子之间的延迟
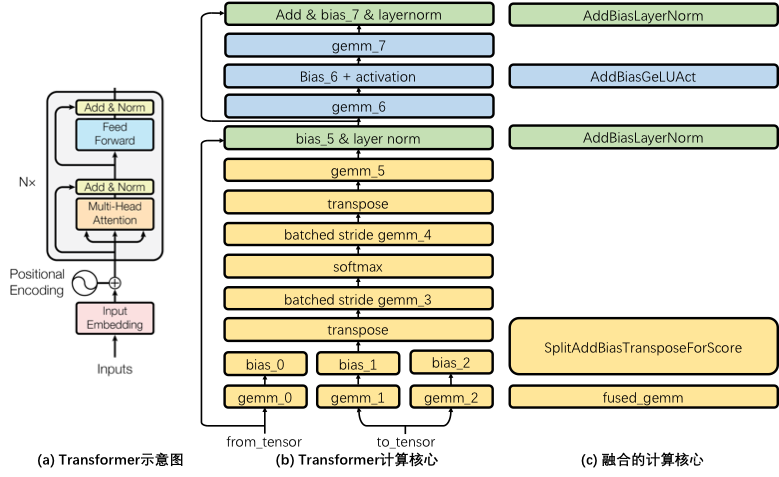
说到这里就不得不说,TVM还是真的一个天才的想法,基本你看到这些turbotransformers都可以看成是autotvm的初始手工设计学习样本,但是他可以从中学习后碰到类似的自己推理出最优组合,或许图中这几个直接组合并不是最优呢,对吧
3. TVM
这种方式我还没试过,等实测与mnn的performance对比后再来补上
4. onnxruntime
下面介绍一个我当前正在使用的工具onnxruntime,当时之所以选择ort原因也比较简单,因为大部分框架都会选择onnx作为中间键,比如首先将torch等模型转到onnx后,再统一接到后端生成寄存器列表或者调用后端接口,那么既然我使用了onnx,就理所当然的去看了下对onnx支持最好的ort
使用ort有这么几个好处:
- 基本不会存在说一个onnx模型拿过来某些层不支持导致跑不起来这种说法,除非你有customer op
- 同样对于transformer有优化,onnxruntime-tools除了流程优化外,还会将其转成fp16以提升推理速度(众所周知,fp16精度与fp32基本相同)
- ort对于异构支持的还是比较好的,可以调用的硬件也就是providers非常多,arm,gpu,npu等等都支持,甚至可以接tvm,这样可以将ort当作callback实现器配合npu等使用可以省去许多工作量
performance对比
正在整合,计划半个月内完成

