
目标检测新范式!扩散模型用于目标检测,代码即将开源
赞
踩
大家好,今天和大家分享一篇最新的论文 DiffusionDet: Diffusion Model for Object Detection 论文和代码地址已公布
https://arxiv.org/abs/2211.09788
https://github.com/ShoufaChen/DiffusionDet
是的,这个算法和今年最火的 AI 绘画类似,都是基于扩散模型去实现。最近我身边也有一些人在研究这个,可能明年大家又开始沿着这个方向开一堆坑!
所以我们一起来了解一下这篇论文
论文细节
摘要:
本文提出了DiffusionDet,这是一个新的框架,它将目标检测表述为从噪声框到目标框的去噪扩散过程。在训练阶段,目标框从ground-truth boxes扩散到随机分布,模型学习如何逆转这种噪声过程。在推理中,模型以渐进的方式将一组随机生成的框细化为输出结果。对标准基准(包括MS-COCO和LVIS)的广泛评估表明,与之前成熟的检测器相比,DiffusionDet具有良好的性能。我们的工作带来了目标检测方面的两个重要发现。首先,随机框虽然与预定义的锚点或学习查询有很大不同,但也是有效的对象候选。第二,目标检测是代表性的感知任务之一,可以通过生成的方式来解决。
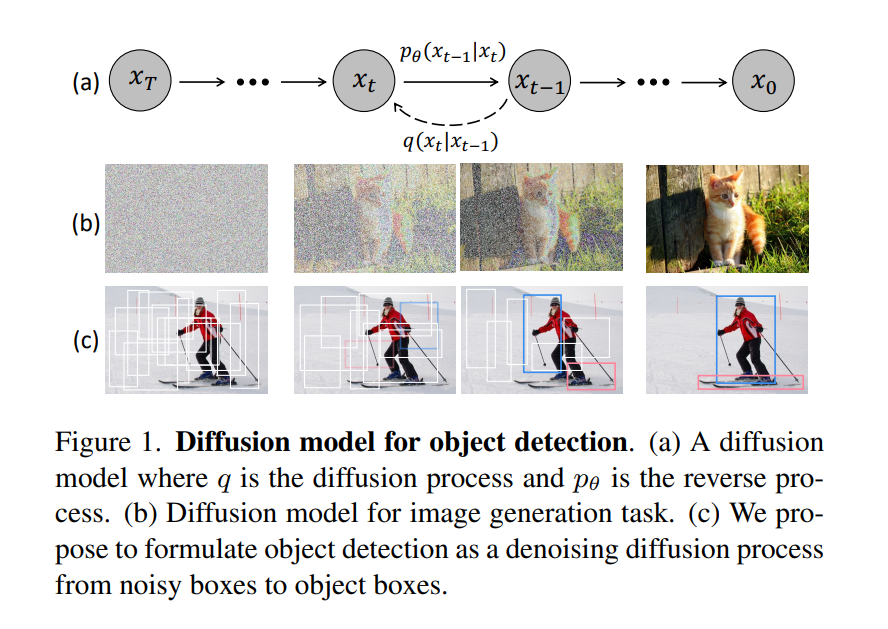
(a)扩散模型:有扩散和逆扩散组成
(b)扩散模型用于图像生成任务
(c)提出将目标检测构造成去噪扩散过程,从噪声框到目标框
在这项工作中,它解决检测任务的方案是通过将图像中边界框的位置(中心坐标)和大小(宽度和高度)转换为空间上的生成任务,利用扩散模型处理对象检测任务。在训练阶段,由方差策略控制的高斯噪声被添加到ground truth框以获得噪声框。然后,使用这些噪声盒从backbone编码器的输出特征图(例如ResNet[34]、Swin Transformer[54])中裁剪感兴趣区域(RoI)的[33,66]特征。最后,这些RoI特征被发送到检测解码器,该解码器被训练来预测没有噪声的ground truth框。有了这个训练目标,DiffusionDet能够从随机盒子中预测 ground truth boxes。在推断阶段,DiffusionDet通过反转学习的扩散过程来生成边界框,该过程将噪声先验分布调整为边界框上的学习分布。
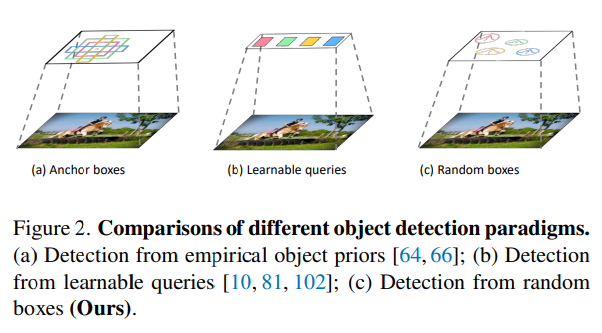
与之前的目标检测范式相比:
整体框架:
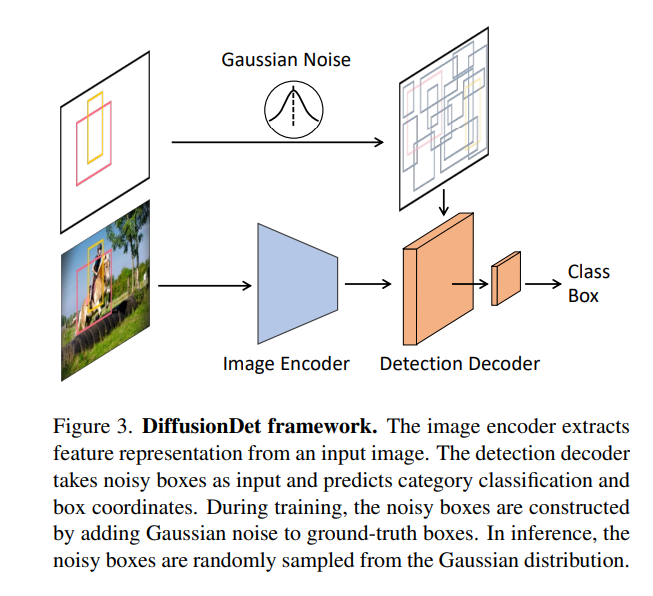
建议将整个模型分成两个部分,图像编码器和检测解码器,其中前者仅运行一次以从原始输入图像x中提取深度特征表示,而后者将此深度特征作为条件,而不是原始图像,以从有噪盒zt中逐步细化盒预测。
伪代码:

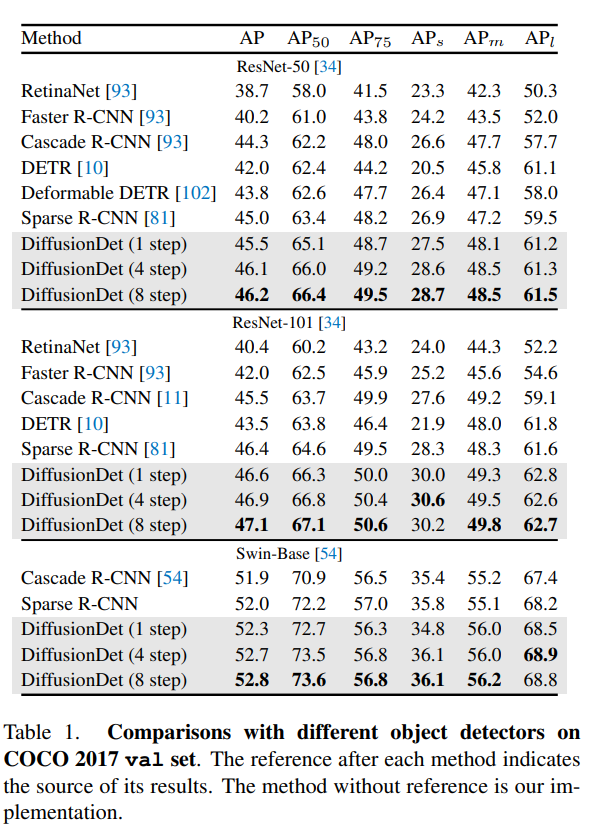
实验结果:
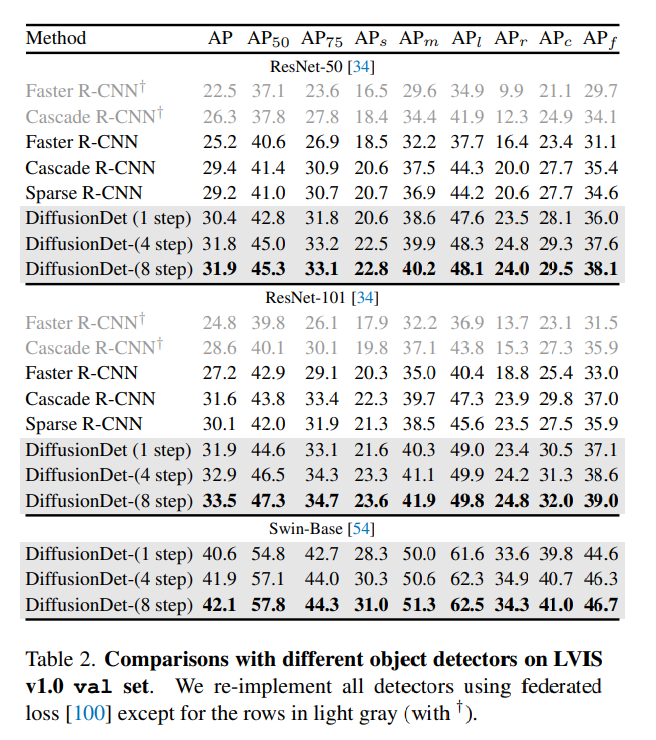
总结
在这项工作中,我们提出了一种新的检测范式,即DiffusionDet,通过将对象检测视为从噪声盒到对象盒的去噪扩散过程。我们的噪声到盒管道具有几个吸引人的特性,包括动态盒和渐进式细化,使我们能够使用相同的网络参数来获得所需的速度-精度权衡,而无需重新训练模型。在标准检测基准上的实验表明,与成熟的检测器相比,DiffusionDet实现了良好的性能。
为了进一步探索扩散模型解决对象级识别任务的潜力,未来的几项工作是有益的。一种尝试是将DiffusionDet应用于视频级任务,例如,对象跟踪和动作识别。另一种是将DiffusionDet从封闭世界扩展到开放世界或开放词汇对象检测。
更多细节参考论文原文和代码
最后也希望大家能够多多分享,分享感谢!

