
- 1通过设置PYTORCH_CUDA_ALLOC_CONF中的max_split_size_mb解决Pytorch的显存碎片化导致的CUDA:Out Of Memory问题
- 2Midjourney之外21款免费的AI Image画图网站集合
- 3Github上哪些好用的工具
- 4基于微信小程序医院预约挂号系统 (后台java+Springboot框架)答辩常规问题和如何回答(答辩指导)_基于微信小程序医院预约挂号系统的开题答辩
- 5基于asp.net考试系统
- 6基于微信小程序的购物系统的设计与实现(源码+lw+部署文档+讲解等)_基于微信小程序线上商城的设计与实现
- 7聊一下Nordic-NRF52832天线_nrf52832天线匹配
- 8java npoi_NPOI的使用
- 9CRNN原理详解、代码实现及BUG分析
- 10qt超市mysql_Qt实现小型的超市收银系统
无法将多信息文本转换为url_【深度好文】simhash文本去重流程
赞
踩
对于类似于头条客户端而言,推荐的每一刷的新闻都必须是不同的新闻,这就需要对新闻文本进行排重。传统的去重一般是对文章的url链接进行排重,但是对于抓取的网页来说,各大平台的新闻可能存在重复,对于只通过文章url进行排重是不靠谱的,为了解决这个痛点于是就提出了用simhash来解决这个难题。
1.简介
传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。即便是两个原始内容只相差一个字节,所产生的签名也很可能差别很大,所以传统的Hash是无法在签名的维度上来衡量原内容的相似度。而SimHash本身属于一种局部敏感hash,其主要思想是降维,将高维的特征向量转化成一个f位的指纹(fingerprint),通过算出两个指纹的海明距离(hamming distince)来确定两篇文章的相似度,海明距离越小,相似度越低(根据 Detecting Near-Duplicates for Web Crawling 论文中所说),一般海明距离为3就代表两篇文章相同。
simhash也有其局限性,在处理小于500字的短文本时,simhash的表现并不是很好,所以在使用simhash前一定要注意这个细节。
2.背景
如何设计一个比较两篇文章相似度的算法?可能你会回答几个比较传统点的思路:
- 一种方案是先将两篇文章分别进行分词,得到一系列特征向量,然后计算特征向量之间的距离(可以计算它们之间的欧氏距离、海明距离或者夹角余弦等等),从而通过距离的大小来判断两篇文章的相似度。
- 另外一种是传统hash,我们考虑为每一个web文档通过hash的方式生成一个指纹(finger print)。
下面我们来分析一下这两种方法:
- 采取第一种方法,若是只比较两篇文章的相似性还好,但如果是海量数据呢,有着数以百万甚至亿万的网页,要求你计算这些网页的相似度。你还会去计算任意两个网页之间的距离或夹角余弦么?那样做的话时间复杂度,空间复杂度可想而知。
- 而第二种方案中所说的传统加密方式md5,其设计的目的是为了让整个分布尽可能地均匀,但如果输入内容一旦出现哪怕轻微的变化,hash值就会发生很大的变化。
3.simhash与hash算法的区别
传统Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统hash算法产生的两个签名,如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大,所以传统Hash是无法在签名的维度上来衡量原内容的相似度。而SimHash本身属于一种局部敏感哈希算法,它产生的hash签名在一定程度上可以表征原内容的相似度。
我们主要解决的是文本相似度计算,要比较的是两个文章是否相似,当然我们降维生成了hash签名也是用于这个目的。看到这里,估计大家就明白了,即使把文章中的字符串变成 01 串,我们使用的simhash算法也还是可以用于计算相似度,而传统的hash却不行。我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
4.simhash原理
simhash是google用来处理海量文本去重的算法。 google出品,你懂的。 simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
算法过程大致如下:
- 对文本分词,得到N维特征向量(默认为64维)
- 为分词设置权重(tf-idf)
- 为特征向量计算哈希
- 对所有特征向量加权,累加(目前仅进行非加权累加)
- 对累加结果,大于零置一,小于零置零
- 得到文本指纹(fingerprint)
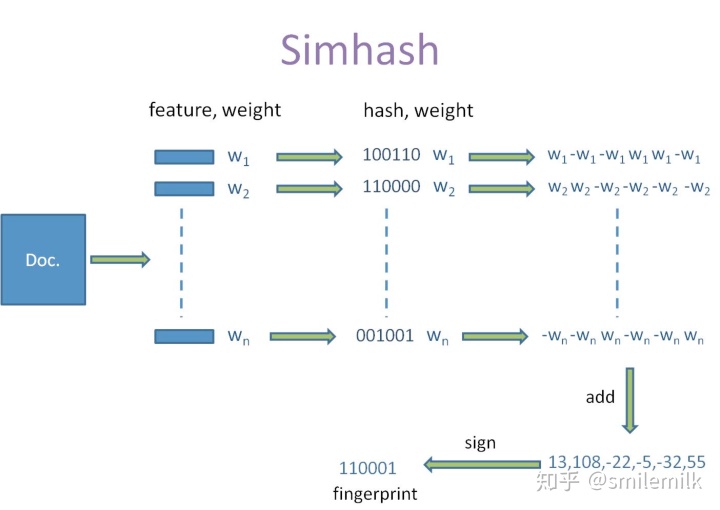
具体流程实现
simhash的算法具体分为5个步骤:分词、hash、加权、合并、降维,具体过程如下:
1.分词
- 给定一段语句或者一段文本,进行分词,得到有效的特征向量,然后为每一个特征向量设置一个5个级别(1—5)权值。例如给定一段语句:“生活本没有路,走的人多了就成了路,要相信阳光总在风雨后”,分词后结果为:生活 没有 成了 相信 阳光 风雨,然后为每个特征向量赋予权值: 生活(5) 没有(2) 成了(1) 相信(2) 阳光(3) 风雨(2),其中括号里的数字代表这个单词在整条语句中的重要程度,数字越大代表越重要。
2.hash
- 通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如“生活”的hash值Hash(生活)为110101,“没有”的hash值Hash(没有)为“101001”。就这样,字符串就变成了一系列数字。
3.加权
- 在hash值的基础上,给所有特征向量进行加权,即W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给“生活”的hash值“110101”加权得到:W(生活) = 110101 5 = 5 5 -5 5 -5 5,给“没有”的hash值“101001”加权得到:W(没有)=101001 2 = 2 -2 2 -2 -2 2,其余特征向量类似此般操作。
4.合并
- 将上述各个特征向量的加权结果累加,变成只有一个序列串。拿前两个特征向量举例,例如“生活”的“5 5 -5 5 -5 5”和“没有”的“2 -2 2 -2 -2 2”进行累加,得到“5+2 5-2 -5+2 5-2 -5-2 5+2”,得到“7 3 -3 3 -7 7”。
5.降维
- 对于n-bit签名的累加结果,如果大于0则置1,否则置0,从而得到该语句的simhash值,最后我们便可以根据不同语句simhash的海明距离来判断它们的相似度。例如把上面计算出来的“9 -9 1 -1 1 9”降维(某位大于0记为1,小于0记为0),得到的01串为:“1 1 0 1 0 1”,从而形成它们的simhash签名。
整个过程的流程图为:
5、simhash的签名距离计算
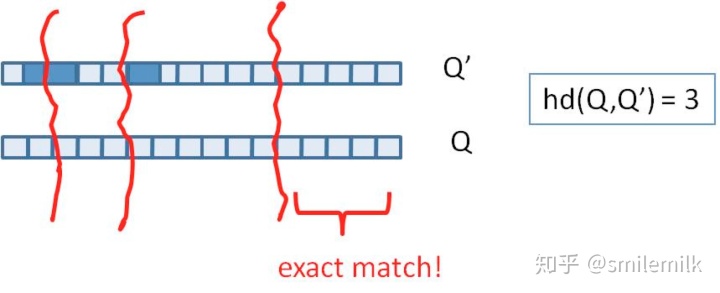
我们把库里的文本都转换为simhash签名,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?难道是比较两个simhash的01有多少个不同吗?对的,其实也就是这样,我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
我们可以把 64 位的二进制simhash签名均分成4块,每块16位。根据鸽巢原理(也称抽屉原理),如果两个签名的海明距离在 3 以内,它们必有一块完全相同。如下图所示:
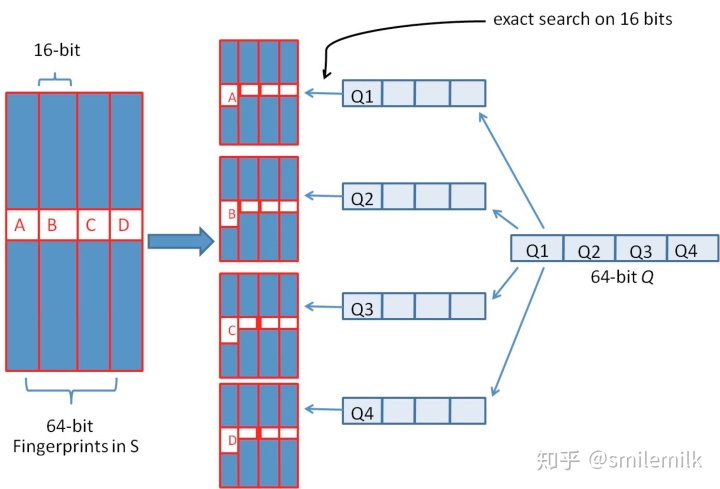
6、simhash的存储和查找
- 我们需要将64位simhash均分为4份,然后每份作为key存储到redis
- 采用精确匹配的方式查找前16位
- 找到则拿出来计算与被比较的simahsh距离,小于3则判断为相似(当然具体问题具体分析,这个值可以调整)
- 如果样本库中存有2^34(差不多10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果,大大减少了海明距离的计算成本
7、聊聊Jaccard相似度与汉明距离
7.1 Jaccard相似度
Jaccard 系数,又叫Jaccard相似性系数,用来比较样本集中的相似性和分散性的一个概率。 公式:
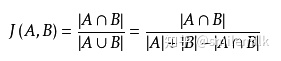
给定两个集合A,B jaccard 系数定义为A与B交集的大小与并集大小的比值,jaccard值越大说明相似度越高
7.2 汉明距离
在信息理论中,Hamming Distance 表示两个等长字符串在对应位置上不同字符的数目,我们以d(x, y)表示字符串x和y之间的汉明距离。从另外一个方面看,汉明距离度量了通过替换字符的方式将字符串x变成y所需要的最小的替换次数。
举例说明以下字符串间的汉明距离为:
- "karolin" and "kathrin" is 3.
- "karolin" and "kerstin" is 3.
- 1011101 and 1001001 is 2.
- 2173896 and 2233796 is 3.
8、【实战】新闻文本去重服务详细流程
上面陆陆续续讲了这么多理论知识想必大家也是一头雾水,接下来我们通过实战来讲述整体流程。

本文将文本排重做成了一个接口,首先给去重接口传一些必要的参数,针对新闻文本为例(url:链接 title:文本标题 content:内容)。依次是进行url排重、title排重、content排重,
如果三种都没有找到,则建立url、title、content索引存储到redis。具体流程图如下:
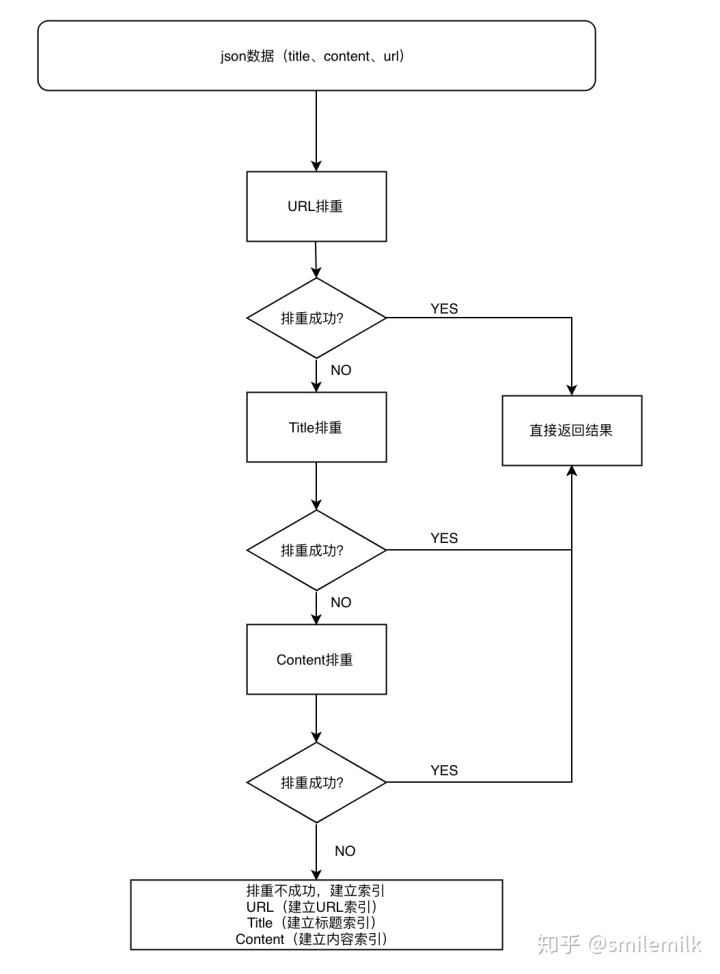
8.1、URL排重
1.建立URL索引:
- key: url_index_name+"_"+urlMD5。url_index_name为索引名字,urlMD5表示url的MD5值
- value: docId+"t"+url+"t"+storageTime。 docId为新闻的事件id,url表示新闻链接,storageTime表示存入redis的时间戳
2.根据urlMD5从redis查找数据,找到则排重成功返回docId,没有找到则排重失败。
8.2、Title排重
- 建立Title索引:
- key: title_index_name+"_"+titleMD5。title_index_name为索引名字,titleMD5表示title的MD5值
- value: docId+"t"+title+"t"+url+"t"+storageTime。 docId为新闻的事件id,title为新闻标题,url表示新闻链接,storageTime表示存入redis的时间戳
2. 根据titleMD5从redis查找数据,找到则排重成功返回docId,没有找到则排重失败。
8.3、Content排重
1. 建立Content索引:
- 先将64位simhash值均分为4份:
- simHashFragment1、simHashFragment2、simHashFragment3、simHashFragment4
- key: content_index_name+"_"+simHashFragment。content_index_name为索引名字,simHashFragment表示其中一段simhash值(16位)
- value: docId+"t"+title+"t"+simhash+"t"+url+"t"+storageTime。 docId为新闻的事件id,title为新闻标题,url表示新闻链接,storageTime表示存入redis的时间戳
1.然后将这4份索引存储到redis(LIST)
2.根据simHashFragment索引从redis里面查找(4份simhash索引都得一起召回)
3.将召回的值依次与带排重的文本比对
-
- hanmingDistance<=H 并且 jarccardSimilary>=J 召回(一般设置H=10,J=0.7 具体情况具体分析) 注:三天内新闻做法
- hanmingDistance<=3 并且 jarccardSimilary>=0.7 注:三天外新闻做法
4.将召回的新闻做rank(这里不细讲,方法很多),TOP1作为排重的新闻
9、总结
现如今是一个信息过载的时代,高效的从海量文本里面快速找到相似的文本是一个需要解决的一个痛点,simhash的存在就很好的解决了这个问题。
由于simhash是局部敏感的hash,其可能不适合做这种短标题的重复度判断,会存在一定的误差,文本越长判断的准确率越高。

