
- 1#3,Android Studio Android开发APP的开发语言和APP连接的数据库 总结_android studio开发语言
- 2mac清理垃圾的软件有哪些?这三款我最推荐_mac清理软件
- 3人工智能(1)- 三类机器学习算法_人工智能三大算法
- 4开源浪潮下,Apache APISIX 如何成为全球最活跃 API 网关
- 5HarmonyOS 应用开发入门_兼容js的类web开发范式 next 版本不支持么
- 6初识vue2.0_vue2.0官网介绍
- 714个开源免费的人工智能项目,人脸识别依旧很受欢迎_目前开源可以离线运行的人工智能项目
- 8数据集成、数据变换、维度归约、属性子集选择_属性子集选择举例
- 9oracle中查找指定字符串位置_oracle获取第一个出现位置
- 10ubuntu20更换节点_手摸手教程之ubuntu20.04更改国内镜像源(附其他版本ubuntu换源教程,最新详细教程)...
经典的卷积神经网络(VGG、ResNet、InceptionNet、MobileNet)_vgg,resnet,inception
赞
踩
1、卷积网络发展
卷积神经网络的起源是神经认知机模型(neocongnitron),之后在1989年出现了卷积神经与网络的模型。直到2012年随着一些技术的成熟带来的机遇,卷积神经网络迎来了历史性的突破,AlexNet获得ImageNet大赛冠军引起了人们的注意,之后的卷积网络朝着四个方向发展

AlexNet:通过数据增强、Dropout来防止过拟合,所谓数据增强就是在原有的图片样本的基础上,通过对图片进行裁剪、反转、调整得到新的样本数据。Dropout是指在全连接层随机去掉某些神经元,从而产生不同的网络结构,相应的缺点是需要更多的训练时间。此外它还采用了非线性激活函数ReLU。以及在120万张大数据图像上进行训练。AlexNet在横向上通普通卷积网络一样经过多个卷积池化全连接操作,在纵向将一张图片数据分别在两个GPU上进行独立运算,并在第三个卷积层将数据交叉,这样可以极大增加数据运算的规模。

2、VGGNet
在AlexNet的基础上对卷积网络的层数进行加深就形成了多种VGG模型,最常用的是16层或19层的模型,此时已经达到了准确率提升的瓶颈,再增加层数已经无法提升正确率。如下左图所示,在VGG中使用两个3×3的叠代网络代替单个5×5网络的视野域,不仅可以学习到更多的内容,而且降低了参数。

下面在Cifar数据集上对VggNet进行实现
2.1、数据处理
首先定义一个类用于实现Cifar训练与测试数据集的读入,在初始化一个数据集对象时传入数据文件路径列表与是否需要重洗数据,对于训练集可以打乱数据顺序重用,而测试集则不需要。训练集数据有五个批次,依次遍历每个路径列表中的五个文件,通过load_data()函数读入五个批次中的所有数据。再将标签与数据值分别合并到_data与_labels变量中。对象可以通过next_batch()方法每次返回batch_size个数据。
- import tensorflow as tf
- import os
- import pickle
- import numpy as np
-
- CIFAR_DIR='D:\Temp\MachineLearning\data\cifar-10-batches-py'
-
- class CifarData:
- def __init__(self,filelist,shuffle):
- all_data=[]
- all_labels=[]
- #循环读取多个批次的数据集文件
- for filename in filelist:
- data,labels=self.load_data(filename)
- all_data.append(data)
- all_labels.append(labels)
- # 将所有data以纵向的方式合并到_data
- self._data=np.vstack(all_data)
- # 数据归一化处理
- self._data=self._data/127.5 - 1
- # 将所有label以横向方式合并到_label
- self._labels=np.hstack(all_labels)
- # 数据中样本个数
- self._example_num=self._data.shape[0]
- print(self._example_num)
- # 定位数据集遍历的位置指针
- self._indicator=0
- # 根据传入的shuffle决定是否对数据进行打乱
- self._shuffle=shuffle
- if self._shuffle:
- self.shuffle_data()
-
- def load_data(self,filename):
- """读取一个批文件中的数据"""
- with open(filename,'rb') as f:
- data=pickle.load(f,encoding='bytes')
- return data[b'data'],data[b'labels']
-
- def shuffle_data(self):
- # 返回一个打乱的序号列表,例如将0~5 随机打乱为 [5,3,2,4,0,1]
- shuffle_list=np.random.permutation(self._example_num)
- # 根据随机列表重排数据和对应的标签值
- self._data=self._data[shuffle_list]
- self._labels=self._labels[shuffle_list]
-
- def next_batch(self,batch_size ):
- '''返回当前指针self._indicator之后batch_size个数据'''
- end_indicator=self._indicator+batch_size
- # 如果相加结果超过了样本个数
- if end_indicator>self._example_num:
- # 如果可以洗牌,打乱数据并从0开始重新取数据
- if self._shuffle:
- self.shuffle_data()
- self._indicator=0
- end_indicator=batch_size
- else:
- raise Exception("没有更多数据了!")
- # 返回从_indicator到end_indicator的data和labels,并将指针后移到end_indicator
- batch_data=self._data[self._indicator:end_indicator]
- batch_labels=self._labels[self._indicator:end_indicator]
- self._indicator=end_indicator
- return batch_data,batch_labels
-
- # 拼接训练数据的路径名
- train_file=[os.path.join(CIFAR_DIR,'data_batch_%d'%i) for i in range (1,6)]
- test_file=[os.path.join(CIFAR_DIR,'test_batch')]
- # 创建训练数据对象
- train_data=CifarData(train_file,True)

2.2、模型图的构建,
首先定义占位符x,y,并对x进行数据处理
- x=tf.placeholder(tf.float32,[None,3072])
- y=tf.placeholder(tf.int64,[None])
- # 将一维向量x转化为具有三通道的多维图片,并交换向量通道
- x_img=tf.reshape(x,[-1,3,32,32])
- x_img=tf.transpose(x_img,[0,2,3,1])
接下来定义卷积网络,vgg的关键特点就是在普通卷积网络的基础上,增加了卷积层的数量,例如可以定义两个卷积层,在定义一个池化层,依次类推定义三个这样的结构
- # 卷积层1_1
- conv1_1=tf.layers.conv2d(x_img, #输入
- 32, #输出通道数
- (3,3), #卷积核大小
- padding='same', #填充使图小大小不变
- activation=tf.nn.relu, #激活函数
- name='conv1_1'
- )
- # VggNet两个卷积层,一个池化层
- conv1_2=tf.layers.conv2d(conv1_1,32,(3,3),padding='same',activation=tf.nn.relu,name='conv1_2')
- # 池化层,步长至少为2才能缩小图像,32×32输出为16×16
- pool1=tf.layers.max_pooling2d(conv1_2, #输入
- (2,2), #池化核
- (2,2), #步长
- name='pool1')
- # 卷积层2_1、2_2与第二个池化层
- conv2_1=tf.layers.conv2d(pool1,32,(3,3),padding='same',activation=tf.nn.relu,name='conv2_1')
- conv2_2=tf.layers.conv2d(conv2_1,32,(3,3),padding='same',activation=tf.nn.relu,name='conv2_2')
- pool2=tf.layers.max_pooling2d(conv2_2,(2,2),(2,2),name='pool2')
- # 卷积层3_1、3_2与第三个池化层
- conv3_1=tf.layers.conv2d(pool2,32,(3,3),padding='same',activation=tf.nn.relu,name='conv3_1')
- conv3_2=tf.layers.conv2d(conv3_1,32,(3,3),padding='same',activation=tf.nn.relu,name='conv3_2')
- pool3=tf.layers.max_pooling2d(conv3_2,(2,2),(2,2),name='pool3')
2.3、进行训练
定义损失函数、准确率、优化方法:
- # 将输出的张量扁平化
- flatten=tf.layers.flatten(pool3)
- y_predict=tf.layers.dense(flatten,10)
- # 使用交叉熵作为损失函数
- loss=tf.losses.sparse_softmax_cross_entropy(y,y_predict)
-
- # 将标签预测向量中最大的下标作为预测值,例如[0.1,0.8...0.01],则预测为第二类
- predict=tf.math.argmax(y_predict,1)
- # 通过equal函数逐一比较predict,y_reshape的每一个元素
- correction=tf.equal(predict,y)
- accuracy=tf.reduce_mean(tf.cast(correction,tf.float64))
- #定义优化方法
- with tf.name_scope('train_op'):
- train_op=tf.train.AdamOptimizer(1e-3).minimize(loss)
接下来便可以开始训练:
- with tf.Session() as sess:
- sess.run(init)
- for i in range(train_steps):
- batch_data,batch_labels=train_data.next_batch(batch_size)
- loss_val,acc_val,_=sess.run([loss,accuracy,train_op],feed_dict={x:batch_data,y:batch_labels})
- if (i+1) % 500==0:
- print("第%d步:损失:%.5f,精确度:%.5f"%(i,loss_val,acc_val))
- #每训练1000次,在test数据集上进行一次测试
- if (i+1)%1000==0:
- # 定义测试集数据对象
- test_data=CifarData(test_file,False)
- all_acc=[]
- for j in range(test_steps):
- test_batch_data,test_batch_labels=test_data.next_batch(batch_size)
- test_acc=sess.run([accuracy],feed_dict={x:test_batch_data,y:test_batch_labels})
- all_acc.append(test_acc)
- # 将测得的多个准确率求均值
- test_acc_mean=np.mean(all_acc)
- print("第%d步测试集准确率%.4f"%(i,test_acc_mean))
3、ResNet
ResNet结合了Vgg与GoogleNet的特点。随着其卷积层深度增加,出现了训练误差反而增加的问题,这是由于梯度消失导致的后面的网络层无法对前面的层进行调整。为了解决这个问题,ResNet提出了shortcut捷径连接,将输入跳过中间多层与卷积核结果相加,这一层的神经网络可以不用学习整个上一层的输出,而是学习上一个网络输出的残差,因此ResNet又叫做残差网络。
如下左图所示,本层输出H(x)=F(x)+x,F(x)为残差函数,通过F去学习模型与目标的差距,如果模型以及很好地拟合目标,则F(x)=0,即H(x)=0+x,本层实现恒等输出。如果模型和目标存在差距,则通过F(x)学习再加上输入x,与直接用H(x)拟合更为方便。
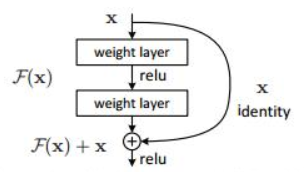

在上面VggNet的基础上修改网络模型,实现ResNet对Cifar数据集的训练,残差网络最重要的是残差连接块的定义,通过函数res_block()定义残差块。输出结果由两部分相加组成,一部分进行卷积操作,另一部分恒等变换,卷积操作可能降采样,会使输出的通道数会翻倍,导致两部分的矩阵维度不一样,无法进行相加。所以这个时候需要对恒等变化也要做一次降采样。
如果输出通道数是输入的两倍,说明卷积的步长为2,在卷积的过程中进行了降采样,并将increase_dim设为True,在之后对x也进行降采样。否则卷积步长为1,卷积过程不会降采样,x不需要处理,直接将x和卷积结果相加得到输出。
- def res_block(x,out_chanel):
- '''实现残差连接块'''
- in_chanel=x.shape[-1]
- # 如果输出通道是输入的两倍,说明需要进行降采样操作
- if in_chanel*2==out_chanel:
- increase_dim=True
- strides=(2,2) # 将步长设为2,卷积操作会进行降采样
- elif in_chanel==out_chanel:
- increase_dim=False
- strides=(1,1) # 步长为1,不进行降采样
- else:
- raise Exception('输入输出通道数目无法匹配')
- # 对输入进行卷积操作
- conv1=tf.layers.conv2d(x,out_chanel,(3,3),strides,padding='same',activation=tf.nn.relu,name='conv1')
- conv2=tf.layers.conv2d(conv1,out_chanel,(3,3),(1,1),padding='same',activation=tf.nn.relu,name='conv2')
- # 如果需要降采样,则对恒等变换部分进行降采样,并补充通道数
- if increase_dim:
- pool_x=tf.layers.average_pooling2d(x,(2,2),(2,2))
- # pool_x为[None,img_width,img_height,chanel],通过tf.pad()对第四维的左右各补充半个in_chanel,使其翻倍
- pad_x=tf.pad(pool_x,[[0,0],[0,0],[0,0],[in_chanel//2,in_chanel//2]])
- else:
- pad_x=x # 不需要降采样,残差直接为x
- out_x=conv2+pad_x # 将卷积结果和残差相加得到输出
- return out_x
有了残差连接块后便可以实现残差网络,例如上面右边图ResNet中的34-layer所示,首先将输入进行一次卷积操作,然后经过四个残差连接层,每个残差连接层中的块数不同,通过两个循环嵌套调用res_block()实现残差连接块,最后经过一个全连接层将结果输出。
- def res_net(x,block_num_list,filter_base,class_num):
- '''构建残差网络
- -x,输入
- -block_num_list,残差连接块数列表,例如[3,4,6,3]
- -filter_base,初始通道数
- -class_num,Cifar数据集的类别数,即最后网络输出的通道数
- '''
- layer_num=len(block_num_list)
- layers=[]
- # 截取x的后三个维度信息,[None,width,height,chanel]->[width,height,chanel]
- input_size=x.shape[1:]
- with tf.variable_scope('conv0'):
- # 首先进行一次卷积操作,并将结果放到layers列表
- conv0=tf.layers.conv2d(x,filter_base,(3,3),(1,1),padding='same',activation=tf.nn.relu,name='conv0')
- layers.append(conv0)
- # 根据残差连接块数列表,循环实现多个残差连接层
- for layer_id in range(layer_num):
- for i in range(block_num_list[layer_id]):
- with tf.variable_scope('conv%d_%d'%(layer_id,i)):
- # 输出通道数是在初始通道的基础上,每经过一层翻一倍,乘以2的layer_id次方
- out_chanel=filter_base*(2**layer_id)
- conv=res_block(layers[-1],out_chanel)
- layers.append(conv)
- # 通过断言检查输出维度是否符合预期,如不符合,报错停止
- multiplier=2 ** (layer_num - 1)
- assert layers[-1].get_shape().as_list()[1:] \
- == [input_size[0] // multiplier,
- input_size[1] // multiplier,
- filter_base * multiplier]
- # 最后经过一个全连接层将结果输出
- with tf.variable_scope('fc'):
- # layers[-1]:[None,width,height,chanel],在width,height上求平均
- global_pool=tf.reduce_mean(layers[-1],[1,2])
- logits=tf.layers.dense(global_pool,class_num)
- layers.append(logits)
- return layers[-1]
4、InceptionNet
GoogleNet在每个卷积层中设置了不同大小的卷积核来增加卷积层功能,例如有5×5、3×3等多种卷积核。卷积核种类多了之后造成特征值的厚度非常大,为了解决这个问题,提出了Inception版本,在卷积核之前通过一个1×1的卷积核进行降维。如下图所示,InceptionNet最大的特点就是在同一卷积层使用不同的卷积核处理数据。

例如下面实现inception块,每个inception块由1×1、3×3、5×5的卷积核与max_pooling构成,将输入x经过不同的卷积操作后将结果拼接起来得到输出
- def inception_block(x,out_chanel_list,name):
- '''
- 实现 inception网络块
- :param x: 输入
- :param out_chanel_list: 不同卷积核输出通道列表
- :param name: 命名域名称
- :return: 多个卷积层的拼接结果
- '''
- with tf.variable_scope(name):
- # 定义1×1、3×3、5×5卷积操作与max_pooling
- conv1_1=tf.layers.conv2d(x,out_chanel_list[0],(1,1),(1,1),
- padding='same',activation=tf.nn.relu,name='conv1_1')
- conv3_3=tf.layers.conv2d(x,out_chanel_list[1],(3,3),(1,1),
- padding='same',activation=tf.nn.relu,name='conv3_3')
- conv5_5=tf.layers.conv2d(x,out_chanel_list[2],(5,5),(1,1),
- padding='same',activation=tf.nn.relu,name='conv5_5')
- max_pooling=tf.layers.max_pooling2d(x,(2,2),(2,2),name='max_pooling')
- # 对max_pooling的结果进行填充,将mx与input相差的部分填充到mx的两侧
- mx_shape=max_pooling.shape[1:]
- input_shape=x.shape[1:]
- width_padding=(input_shape[0]-mx_shape[0])//2
- height_padding=(input_shape[1]-mx_shape[1])//2
- # max_pooling->[None,width,height,chanel],对中间的宽和高进行填充
- mx_padded=tf.pad(max_pooling,[[0,0],[width_padding,width_padding],
- [height_padding,height_padding],[0,0]])
- # 将四个输出结果在第三个维度上进行拼接
- concat_layer=tf.concat([conv1_1,conv3_3,conv5_5,mx_padded],axis=3)
- return concat_layer
接下来利用inception块构建inception网络,将输入x_img首先经过一个卷积、池化层,接着将池化结果传入联系的两个inception块,之后再经过一个池化层。类似地,再经过第三层两个inception块和池化。将结果展开,经过全连接层,得到y的预测值。
- # 先经过一个卷积层和池化层
- conv1=tf.layers.conv2d(x_img,32,(3,3),padding='same',activation=tf.nn.relu,name='conv1')
- pooling1=tf.layers.max_pooling2d(conv1,(2,2),(2,2),name='pooling1')
- # 第二层经过两个inception块和池化层
- inception_2a=inception_block(pooling1,[16,16,16],'inception_2a')
- inception_2b=inception_block(inception_2a,[16,16,16],'inception_2b')
- pooling2=tf.layers.max_pooling2d(inception_2b,(2,2),(2,2),name='pooling2')
- # 第三层
- inception_3a=inception_block(pooling2,[16,16,16],'inception_3a')
- inception_3b=inception_block(inception_3a,[16,16,16],'inception_3b')
- pooling3=tf.layers.max_pooling2d(inception_3b,(2,2),(2,2),name='pooling3')
- # 将结果展开,进行全连接层
- flatten=tf.layers.flatten(pooling3)
- y_predict=tf.layers.dense(flatten,10)
5、MobileNet
MobileNet引入了深度可分离卷积操作,如下图所示,其思想是每个卷积核不关注所有通道,而是只处理几个通道的输出。通过这样的优化减少计算量

如下实现可分离卷积块的操作,将输入的x张量在第四维度上拆分成单个向量并分别进行卷积操作,将卷积后的结果再在第四维上拼接称为一个张量,卷积后返回结果
- def separate_block(x,out_chanel,name):
- '''
- 可分离卷积块
- :param x: 输入
- :param out_chanel: 输出通道数
- :param name: 命名域名称
- :return: 经过可分离卷积的结果
- '''
- with tf.variable_scope(name):
- input_chanel=x.shape[-1]
- # 输入的x->[None,width,height,chanel],在第四维(axis=3)上将x拆分为单个向量
- x_split=tf.split(x,input_chanel,axis=3)
- output_list=[]
- for i in range(input_chanel):
- # 分别对拆分后的每个向量进行卷积操作,并将结果添加到output_list
- output=tf.layers.conv2d(x_split[i],1,(3,3),(1,1),
- padding='same',activation=tf.nn.relu,name='con_%d'%i)
- output_list.append(output)
- # 将单个向量在第四维上拼接起来
- concat_layer=tf.concat(output_list,axis=3)
- # 将拼接后的结果再进行一次卷积后输出
- conv2=tf.layers.conv2d(concat_layer,out_chanel,(1,1),(1,1),
- padding='same',activation=tf.nn.relu,name='conv2')
- return conv2
利用可分离卷积块实现MobileNet网络,其过程与InceptionNet类似,首先经过一次卷积和池化,之后每经过两个可分离卷积块separate_block()做一次池化操作,最后经全连接层输出。
- # 先经过一个卷积层和池化层
- conv1=tf.layers.conv2d(x_img,32,(3,3),padding='same',activation=tf.nn.relu,name='conv1')
- pooling1=tf.layers.max_pooling2d(conv1,(2,2),(2,2),name='pooling1')
- # 第二层经过两个separate_block和池化层
- separate_2a=separate_block(pooling1,32,'separate_2a')
- separate_2b=separate_block(separate_2a,32,'separate_2b')
- pooling2=tf.layers.max_pooling2d(separate_2b,(2,2),(2,2),name='pooling2')
- # 第三层
- separate_3a=separate_block(pooling2,32,'separate_3a')
- separate_3b=separate_block(separate_3a,32,'separate_3b')
- pooling3=tf.layers.max_pooling2d(separate_3b,(2,2),(2,2),name='pooling3')
-
- # 将结果展开,进行全连接层
- flatten=tf.layers.flatten(pooling3)
- y_predict=tf.layers.dense(flatten,10)

