
- 1Docker-高级篇(1)-Dockerfile(核心&构建Redis&构建JDK8)_dockerfile 打包 jdk jar mysql redis
- 22021蓝桥杯(Python)骗分指南_蓝桥杯骗分导论
- 3时间序列 工具库学习(1) tsfresh特征提取、特征选择
- 4物流行业分析数据集分享_物流数据集
- 5ELEMENTUI奇葩坑爬出,遇到根本无从下手的问题之解答_elementui做的不好的地方
- 6大数据和人工智能概念全面解析_人工智能 大数据 电动车
- 7【Jenkins】持续集成与交付 (七):Gitlab添加组、创建用户、创建项目和源码上传到Gitlab仓库
- 8@param注解_Spring 自定义注解从入门到精通
- 9Hive之复杂字段分隔符
- 10Python 实现图书馆管理系统登录界面_关于python制作系统的登录界面和应用
深度学习 --- nlp\cv_cv nlp
赞
踩
一、nlp
1. 机器翻译中的nlp技术
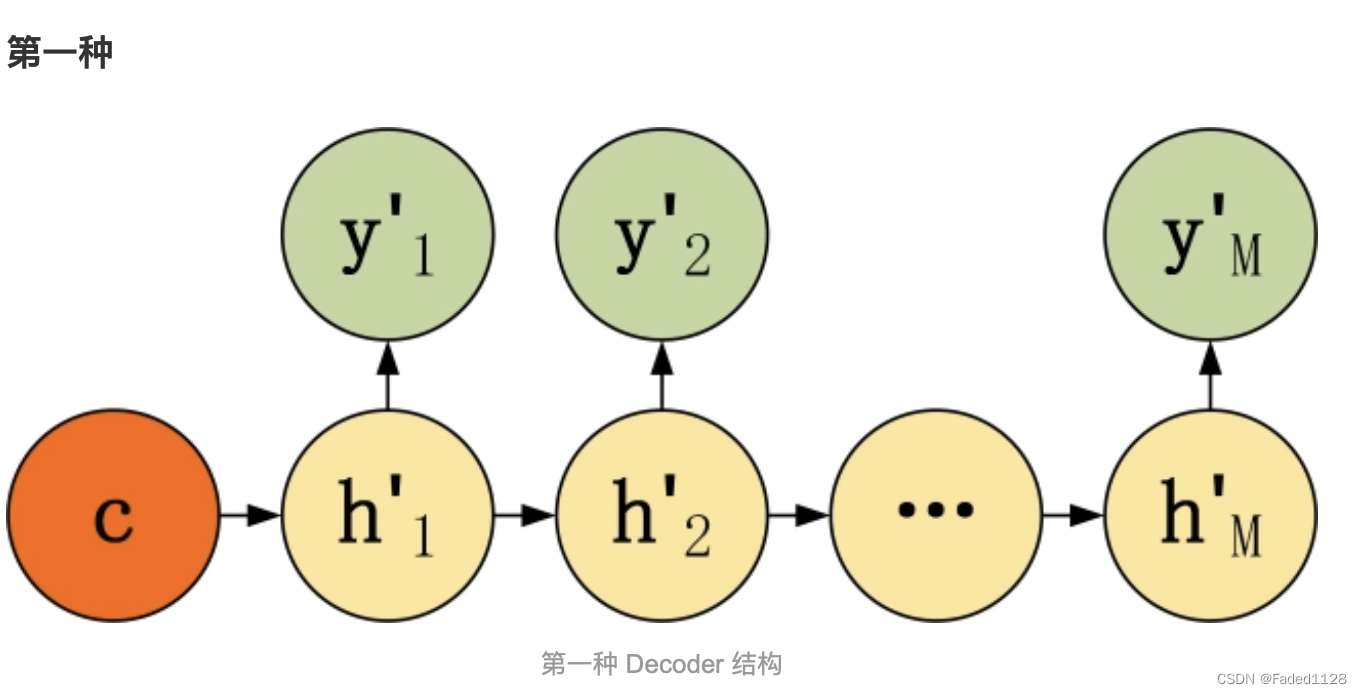
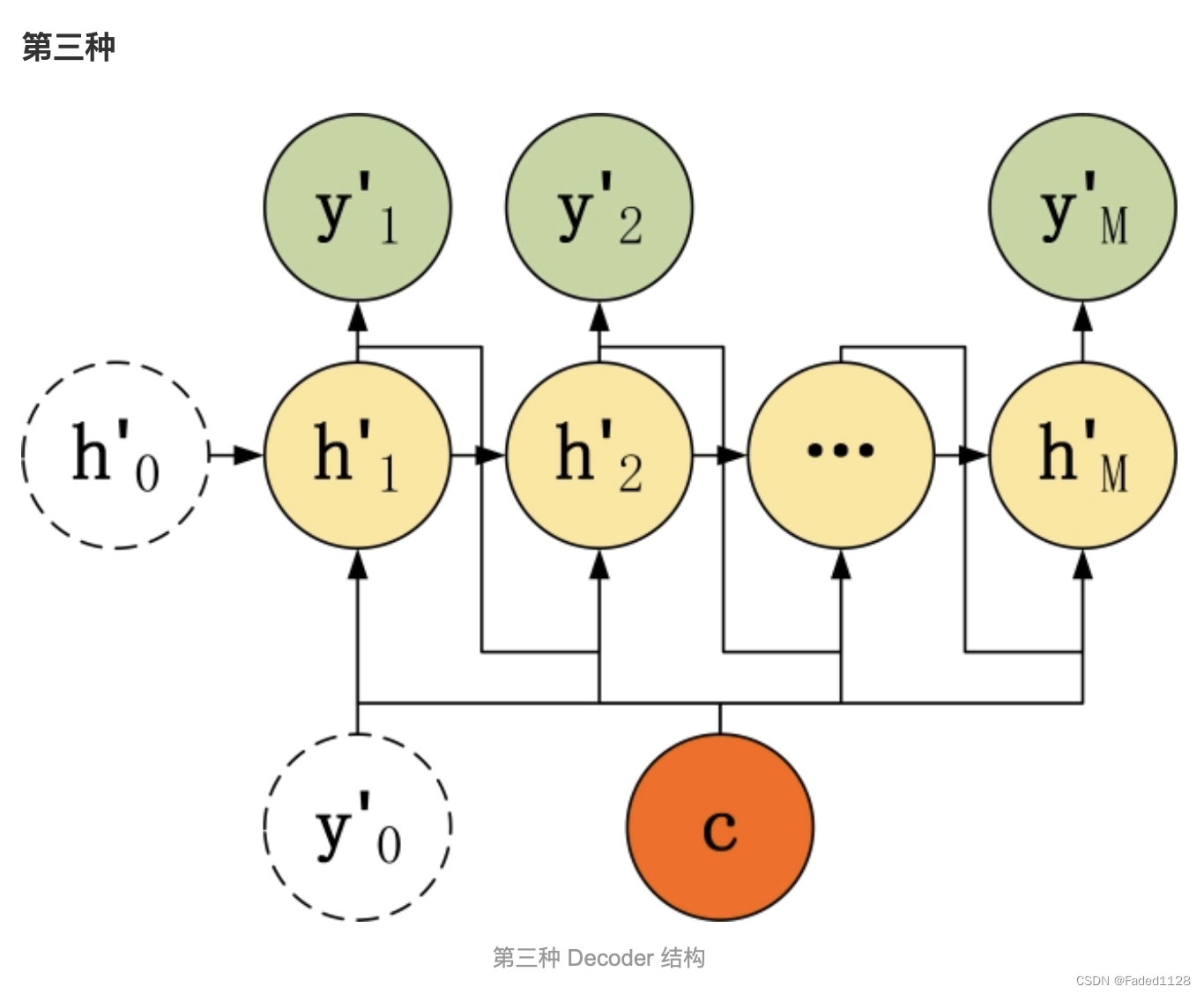
1.1 seq2seq
组成:encoder + decoder(两者都是RNN)
流程:encoder输入源语言 ---> 输出这个句子的embedding --> 输入decoder
encoder:

decoder:

1.2 LSTM
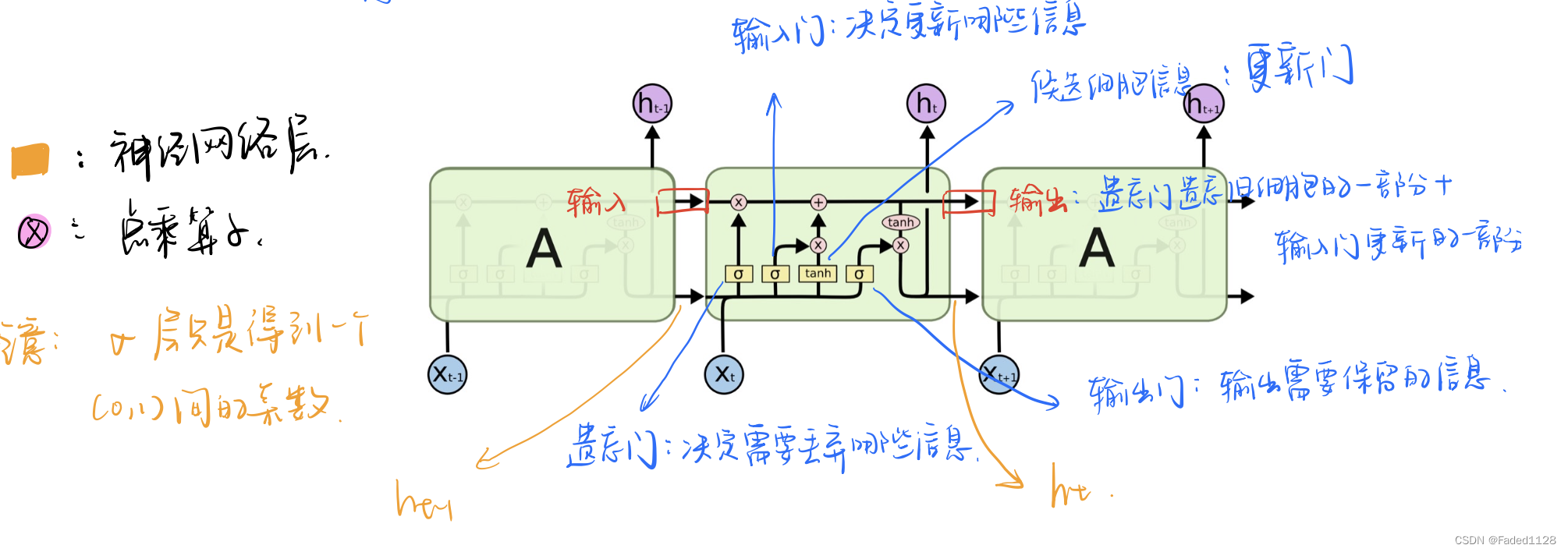
2. elmo、GPT、bert三者之间有什么区别?
- 相同点
- elmo 和 BERT 都是双向的模型,但 elmo 实际上是两个单向神经网络的输出的拼接,这种融合特征的能力比 BERT 一体化融合特征的能力弱
- 输入的都是句子,不是单词
- elmo 、GPT、BERT 都能解决一词多义的问题
- 使用大规模文本训练的预训练模型
- 不相同点:
- GPT 是单向的模型
- BERT 会将输入遮蔽
- elmo 使用的是 LSTM 作为神经网络层,而 GPT 和 BERT 则使用 Transformer 作为神经网络层
3. Transformer\RNN\CNN的模型复杂度
假设输入序列的长度为 ,词汇表的大小(语义向量的长度)为
.
RNN:
CNN: (假设kernel行数为
(列数固定为
))
Transformer:
4. encoder\decoder\encoder+decoder模型举例
Encoder-Only: 文本表示类的任务(文本的分类、实体识别、关键信息抽取)
Decoder: 文本生成类的任务(GPT)
Encoder-Decoder: Seq2seq

4.1 RoBerta
4.1.1 静态MASK v.s. 动态Mask
静态Mask:BERT对每一个序列随机选择15%的tokens替换成[MASK],而一旦被选中,之后的N个epoch就不能再改变。
动态Mask:RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Mask,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。
NSP VS w/o NSP
4.1.2去除了NSP任务
每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做(FULL - SENTENCES),而原来的Bert每次只输入两个句子。
4.1.3 hyper-parameter
更大的batch_size
更多的数据
更高的学习率
更长时间的训练
4.2 XLNet
AR LM:利用上下文单词预测下一个单词的一种模型。但是在这里,上下文单词被限制在两个方向,要么向前,要么向后。
AE LM:从损坏的输入中重建原始数据的一种模型。它可以同时在向前向后两个方向看到上下文。
BERT存在的问题:
掩码导致的微调差异:预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失。
预测的标记彼此独立:Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的,XLNet则考虑了这种关系。
XLNet在输入侧维持表面的X句子单词顺序,在Transformer内部,看到的已经是被重新排列组合后的顺序,是通过Attention Mask来实现的。从X的输入单词里面,也就是Ti的上文和下文单词中,随机选择i-1个,放到Ti的上文位置中,把其它单词的输入通过Attention Mask隐藏掉,于是就能够达成我们期望的目标。
4.3 ALBert
词嵌入向量参数的因式分解(Factorized embedding parameterization)
在BERT、XLNet中,词表的embedding size(E)和transformer层的hidden size(H)是等同的,所以E=H。但实际上词库的大小一般都很大,这就导致模型参数个数就会变得很大。为了解决这些问题他们提出了一个基于factorization的方法。
跨层参数共享(Cross-layer parameter sharing)
每一层的Transformer可以共享参数,这样一来参数的个数不会以层数的增加而增加。
段落连续性任务(Inter-sentence coherence loss)
后续的研究表示NSP过于简单,性能不可靠。使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
5. self-instruction
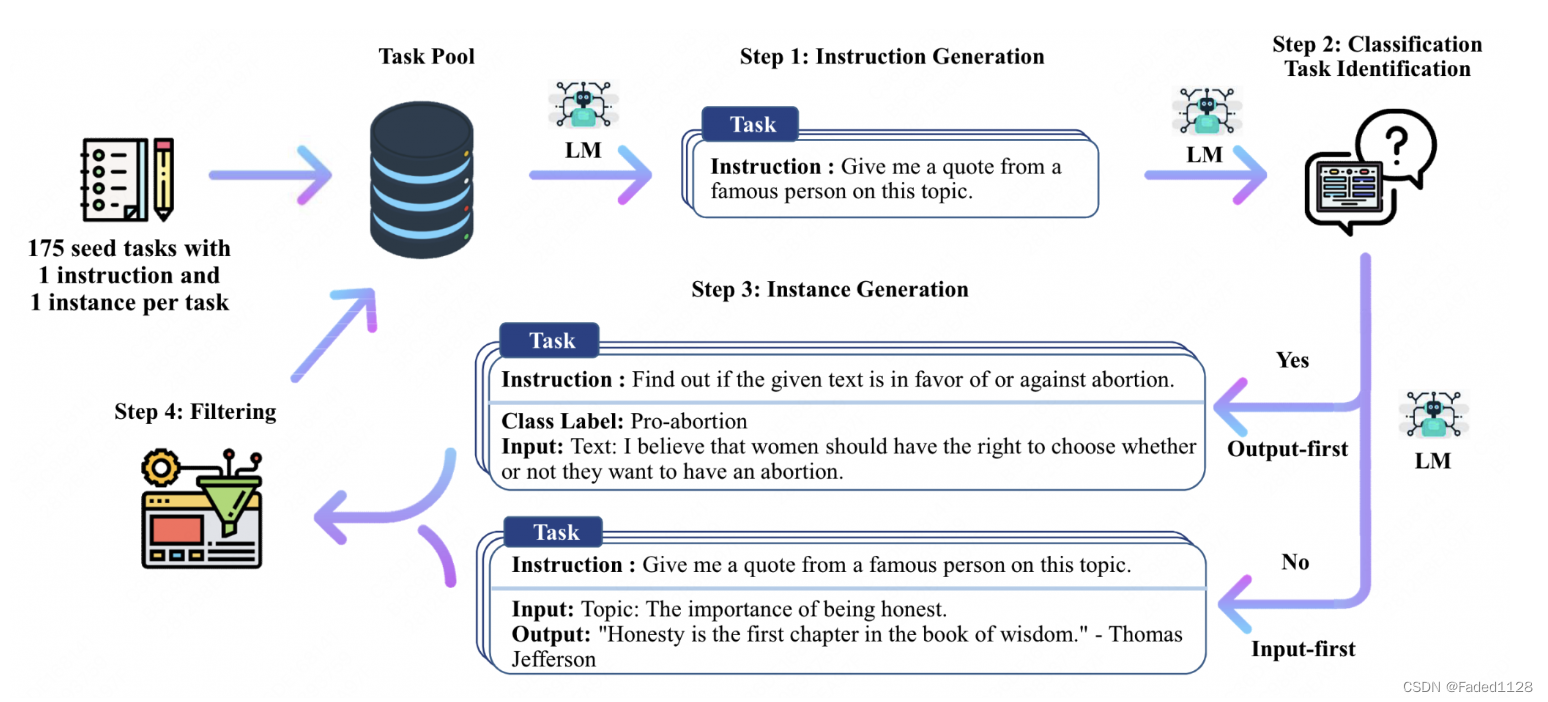
1)指令生成
从一小部分人类编写的指令种子中扩充指令数据
2)识别指令是否代表分类任务
之所以需要区分分类任务和生成任务,是因为模型对于分类任务,会更容易倾向于生成同一个标签的文本。因此让模型先输出label(output),在输出input。
3)用输入优先或输出优先的方法生成实例
为分类任务另外提出了一种输出优先的应用方法,即首先生成可能的类标签,然后根据每个类标签确定输入生成的条件,
4)过滤低质量数据。
使用ROUGE筛选掉高重复的指令、同时筛选掉例如 图片、视频等无法被llm处理的指令。
6. RLHF

1)花钱招人给问题(prompt)写回答(demonstration),然后finetune一个GPT3。
2)用多个模型(可以是初始模型、finetune模型和人工等等)给出问题的多个回答,然后人工给这些问答对按一些标准(可读性、无害、正确性blabla)进行排序,训练一个奖励模型/偏好模型来打分(reward model)。
3)用强化学习训练上面那个finetune后的GPT3模型。用强化学习做LM训练是PPO算法,即Proximal Policy Optimization。
7. 解决一个nlp问题的主流程
7.1 分词

BPE 的优点就在于,可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的 token 数量)。
7.2 文本预处理
7.2.1 词袋模型(Bag Of Words)
把一个句子转化为向量表示,只考虑词表(vocabulary)中单词在这个句子中的出现次数。

缺点: 没有考虑单词间的顺序
7.2.2 TF-IDF
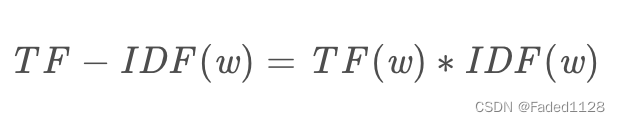
TF(Term Frequency) : 词频

IDF(Inverse Document Frequency): 逆文本频率

TF-IDF值越大说明这个词越重要,也可以说这个词是关键词
7.3 词性标注
7.3.1 CRF
CRF是由随机场满足各种约束条件(随机场满足马尔科夫假设得到马尔科夫随机场,即当前节点只与其相邻节点相关,而在马尔科夫随机场的基础上,假设其随机变量只有X和Y,则得到CRF)而得到的,实际常用的其实叫做线性链CRF(CRF中的X和Y结构不一定是一致的,而线性链CRF中X与Y结构一致)。
那么线性链CRF主要有两个重要组成部分,一个是发射矩阵部分,参数化表示的话就是,各个节点特征函数与其权重的乘积和;另一个是转移矩阵部分,参数化表示的话就是,各个局部特征函数与其权重的乘积和。每个特征函数的结果都是0/1,这两个部分的组合可以得到非常多种不同结果的发射矩阵和转移矩阵,而其中只有一种组合是正确的(我们的目标组合),那么便可以通过SoftMax概率化这个最优结果并取 l o g log log,所以线性链CRF的优化目标就是最大化这个最优组合的概率值。具体线性链CRF参数化表示如下,目标便是最大化 l o g ( P ( y ∣ x ) ) log(P(y|x)) log(P(y∣x)),损失函数的分母是全部路径和,分子是目标最优路径,从而进行训练。
训练完成后,进行预测时需要进行解码,解码使用维特比算法,求解全局最优解,即动态规划,具体见一文轻松搞懂-条件随机场CRF。
7.3.2 HMM
HMM是一个生成模型,由隐藏状态序列生成观测序列。HMM有三个重要知识点:HMM的三个参数:初始概率,状态转移概率,和观测概率。HMM三个任务:预测问题(计算观测序列的概率),解码问题(已知观测序列求最可能产生该观测序列的状态序列),以及学习问题(学习HMM的三个参数)。HMM两个假设:齐次马尔可夫假设(当前状态只与前一状态有关)和观测独立假设(当前观测只与当前状态有关)
【NLP】HMM 词性标注&中文分词_hmm词性标注_maershii的博客-CSDN博客
7.4 文本张量表示方法
7.4.1 one-hot
7.4.2 word2vec
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.
(a) CBOW模式
比如窗口大小为3,用前两个词的one-hot编码乘变换矩阵再相加(维度降低),计算这个向量与第三个词的one-hot编码的损失,完成模型迭代。
(b) skipgram模式
用第三个词预测前两个词,所以有两个变换矩阵。
(c) 两者比较
一般来说,Skip-Gram模型比CBOW模型更好,因为:
- Skip-Gram模型有更多的训练样本。Skip-Gram是一个词预测n个词,而CBOW是n个词预测一个词。
- 误差反向更新中,CBOW是中心词误差更新n个周边词,这n个周边词被更新的力度是一样的。而Skip-Gram中,每个周边词都可以根据误差更新中心词,所以Skip-Gram是更细粒度的学习方法。
- Skip-Gram效果更好,但是缺点就是训练次数更多,时间更长。
7.4.3 word embedding
其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
如果文本中有20000个词语,如果使用one-hot编码,那么我们会有20000*20000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000* 维度,比如20000*300
1. 梯度消失梯度爆炸的原因及解决办法?
什么是:反向传播的过程中,对激活函数求导,若导数>1(<1),随着网络的加深,梯度更新将朝着指数爆炸(衰减)的方式增加(减少)。
原因:激活函数
解决方案:
1. 梯度剪切:梯度更新 = min(阈值,梯度),防止梯度爆炸。
2. 权重正则化:L1、L2,解决梯度爆炸。
3. Relu激活函数:Relu(x) = max(0,x), 防止梯度爆炸。
4. BN:batchnorm通过对每一层的输出规范为均值和方差一致的方法,消除了x带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
5. RNN & LSTM:门控
退化问题:网络深度增加时,网络准确度出现饱和,甚至出现下降。(解决:残差学习)
二、 过拟合的解决办法?
- 增加数据量
- 数据增强
- 加入L1,L2正则
- Dropout
- Batch Normalization
- early stopping
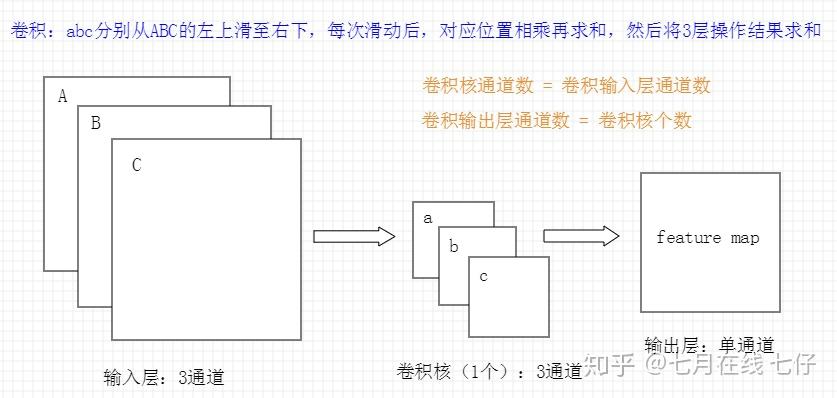
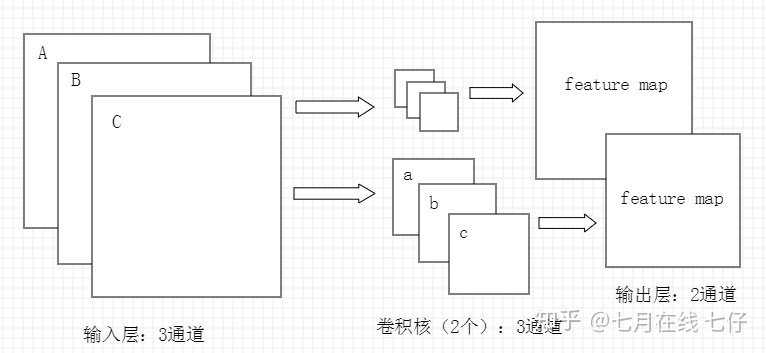
三、如何确定CNN的卷积核通道数和卷积输出层的通道数?
CNN的卷积核通道数 = 卷积输入层的通道数;CNN的卷积输出层通道数 = 卷积核的个数
四. 激活函数
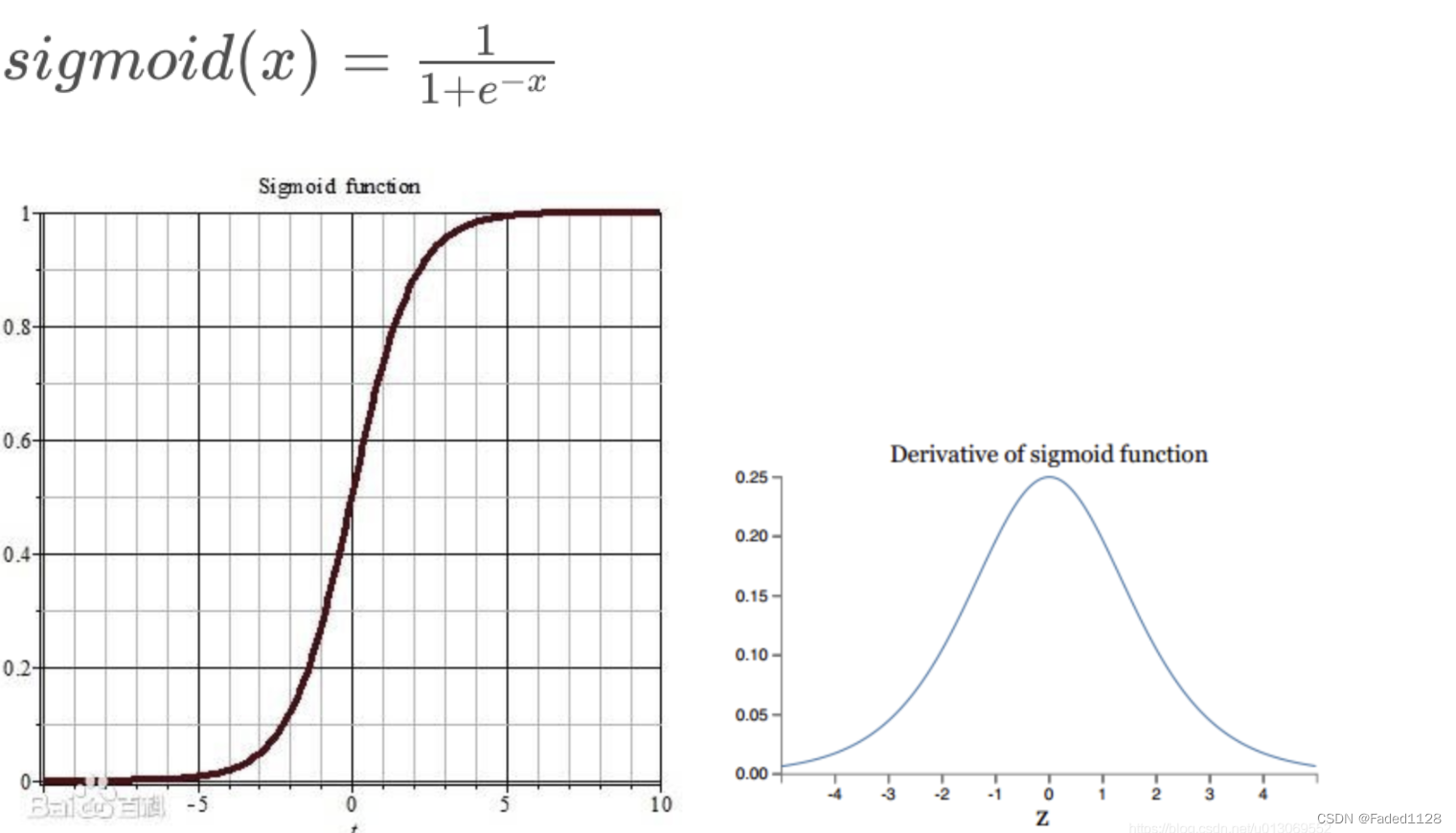
4.1 Sigmoid函数

缺点: 梯度消失;不以零为中心(有偏移量);计算成本高 (exp())
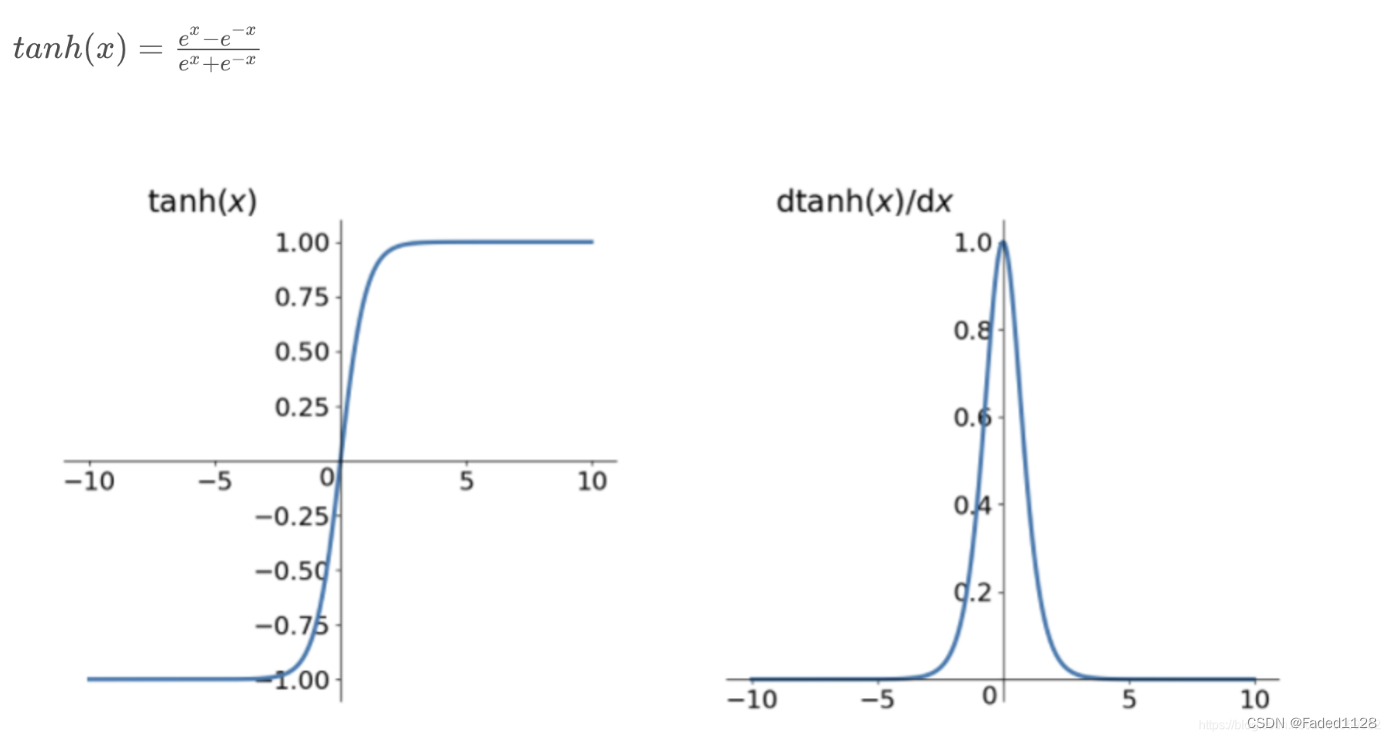
4.2 tanh(双曲正切)
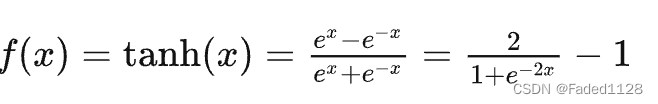
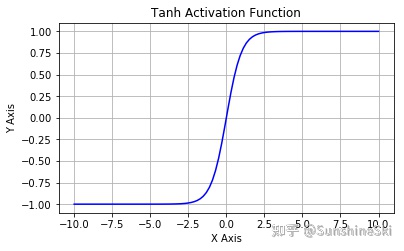
缺点: 梯度消失;计算成本高 (exp())
4.3 ReLU
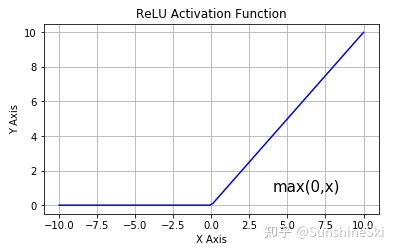
缺点:神经元死亡;不以零为中心
4.4 Leaky ReLU
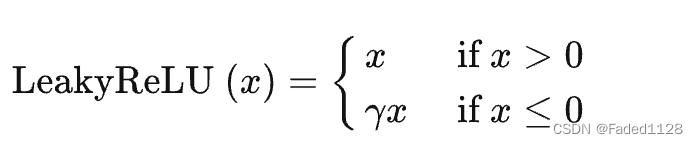
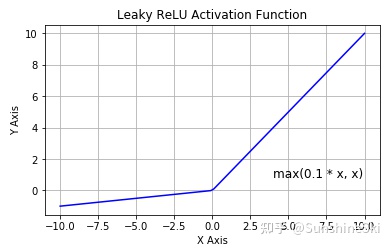
4.5 softmax:多分类问题
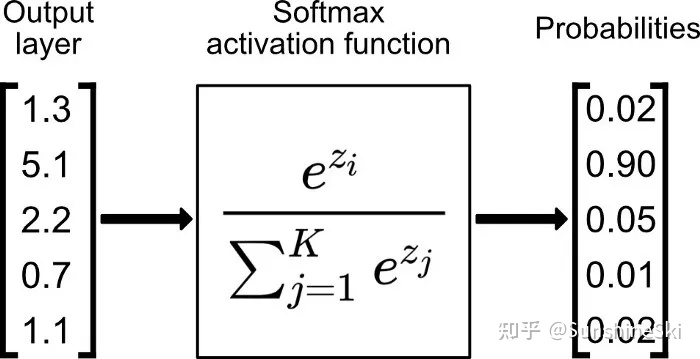
五、 怎么解决样本分布不均衡的问题
样本:过采样、欠采样、数据增强
损失函数:class weight、Focal loss
模型:集成学习
六、简述下什么是生成对抗网络
假设有两个模型,一个是生成模型(Generative Model,下文简写为G),一个是判别模型(Discriminative Model,下文简写为D),判别模型(D)的任务就是判断一个实例是真实的还是由模型生成的,生成模型(G)的任务是生成一个实例来骗过判别模型(D) ,两个模型互相对抗,发展下去就会达到一个平衡,生成模型生成的实例与真实的没有区别,判别模型无法区分自然的还是模型生成的。
七、几个常用的CNN模型


