
- 1刷一道leetcode花了一天,这正常吗?_力扣写一道题花一天时间
- 213(PHP连接Mysql)_php连接mysql数据库代码
- 3定时从linux获取文件,CentOS 6.4下定时通过ftp获取数据库服务器上的文件
- 4Docker 的安装使用_docker apt-get
- 5Flask Web开发:使用render_template渲染动态HTML模板
- 6c# 实习面试题_c#实习面试
- 7AI绘画:实例-利用Stable Diffusion ComfyUI实现多图连接:区域化提示词与条件设置_comfyui区域条件
- 8Python: 如何绘制核密度散点图和箱线图?_python 箱线图
- 9GitHub主页设计_给github主页装修
- 10GPU快速排序笔记_gpu quick sort
Linux:进程地址空间、进程控制(一.进程创建、进程终止、进程等待)
赞
踩
上次介绍了环境变量:Linux:进程概念(四.main函数的参数、环境变量及其相关操作)
1.程序地址空间
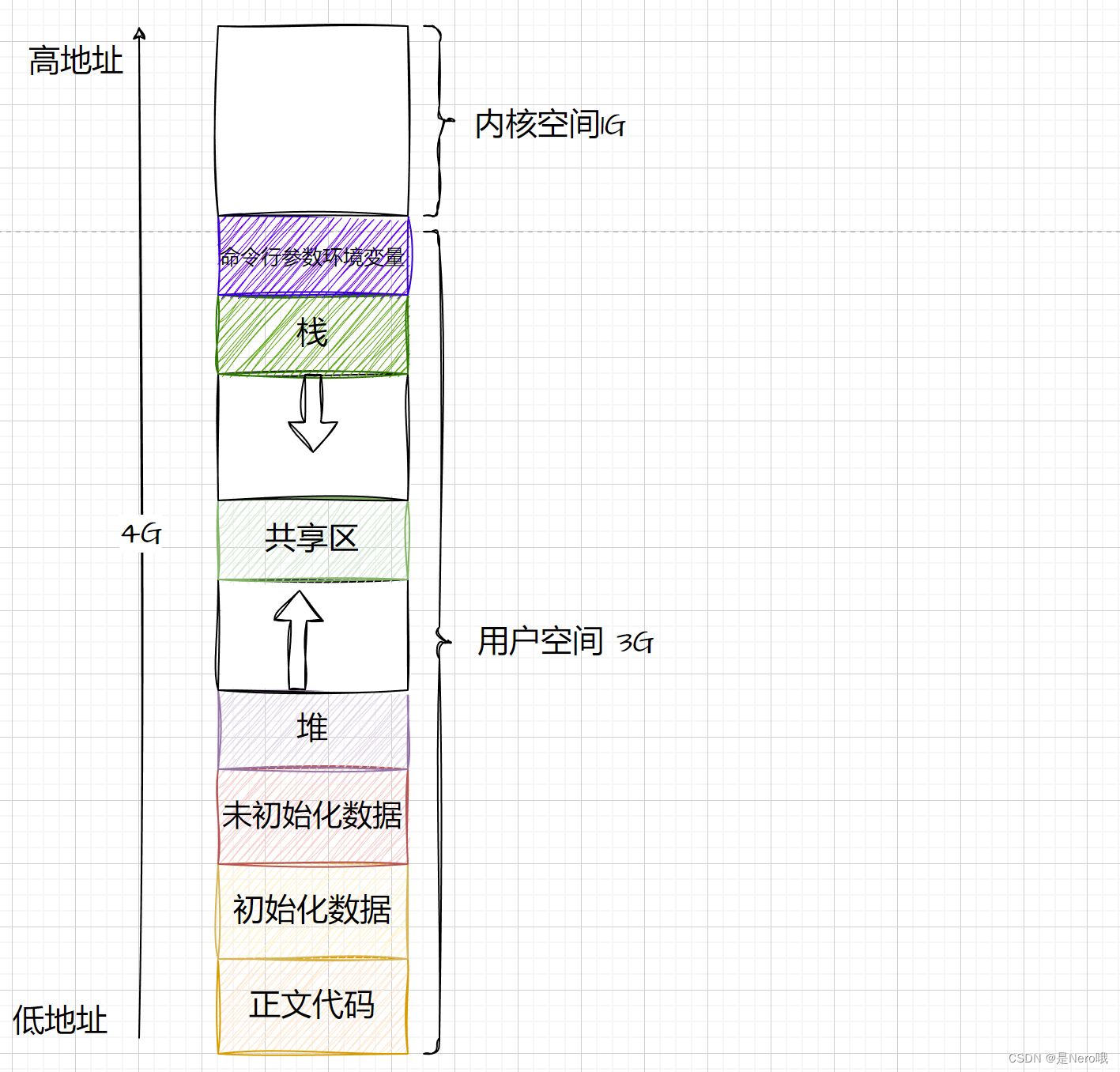
牵扯到内存,肯定有事这张图啦。这次我们写段代码验证一下
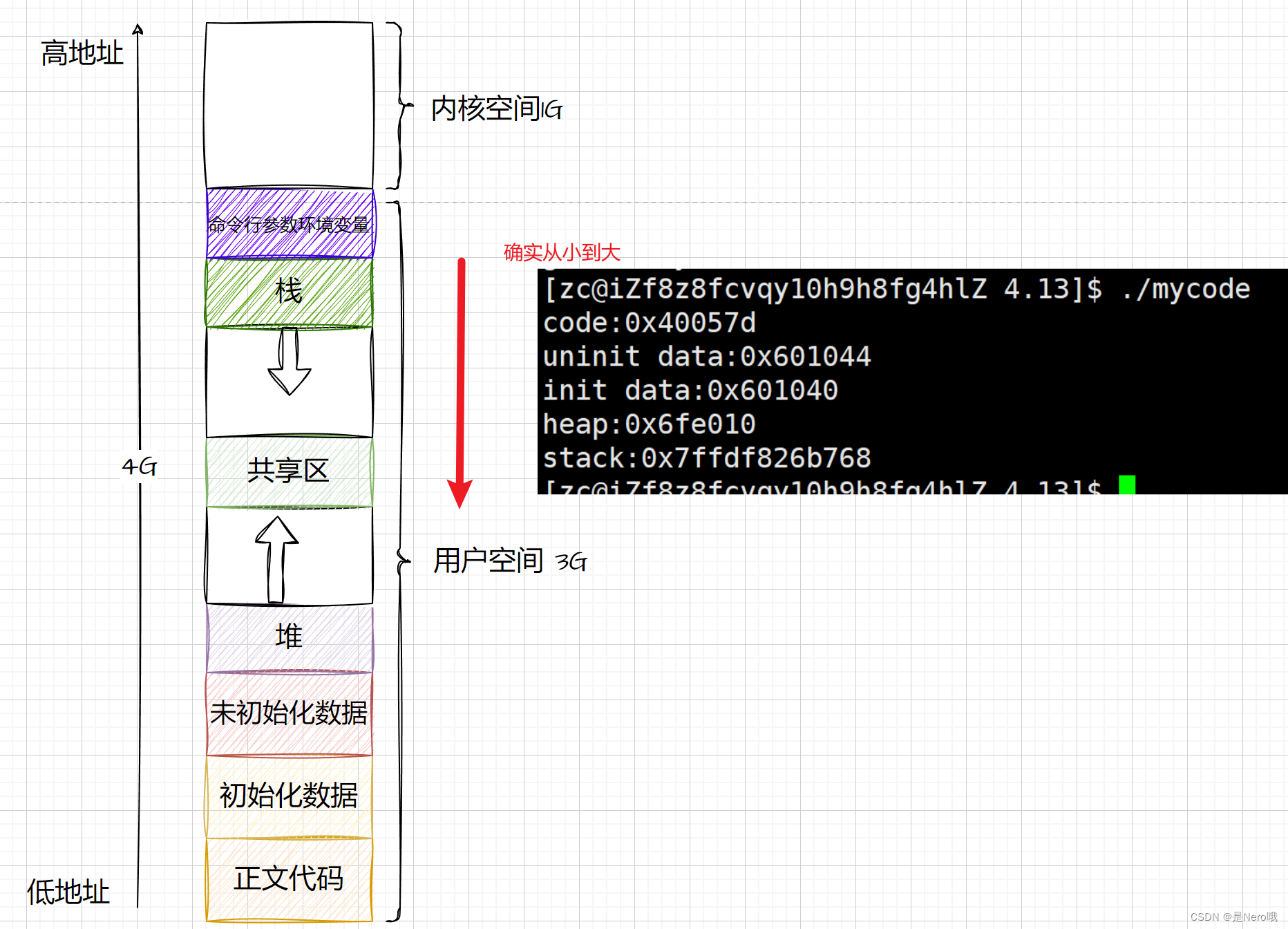
#include <stdio.h> #include <unistd.h> int a; int init_a = 0; int main() { printf("code:%p\n", main);//代码 printf("uninit data:%p\n", &a);//未初始化变量 printf("init data:%p\n", &init_a);//初始化变量 char* arr = (char*)malloc(10); printf("heap:%p\n", arr);//堆 printf("stack:%p\n", &arr);//栈 return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
知识点总结
-
字符串常量:
- 字符串常量通常存储在高地址,其地址是固定的,不可更改。
- 字符串的下标从0到n一直在增加,即字符串中的每个字符在内存中是连续存储的。
-
main函数地址:
main函数地址通常是程序中最底部的地址,因为它是程序的入口点。
-
初始化数据和未初始化数据:
- 初始化数据(如全局变量、静态变量)存储在比
main函数地址高的位置,因为它们在程序启动时需要被初始化。 - 未初始化数据(如全局未初始化变量、静态变量)存储在比初始化数据更高的位置,因为它们在程序启动时不需要被初始化。
- 初始化数据(如全局变量、静态变量)存储在比
-
堆区:
- 堆区是用于动态内存分配的区域,在堆区中存储动态分配的内存。
- 堆区是向上增长的,即分配的内存地址逐渐增加,地址比未初始化数据高。
-
栈区:
- 栈区用于存储函数的参数值、局部变量和函数调用返回地址等信息。
- 栈区是向下增长的,即栈顶地址逐渐减小,整体比堆区的地址要高。
上述空间排布结构是在内存吗?(进程地址空间引入)
#include <stdio.h> #include <string.h> #include <unistd.h> #include <stdlib.h> int main() { pid_t id = fork(); if (id == 0) { int cnt = 0; while (1) { printf("child, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val); sleep(1); cnt++; if (cnt == 3) { g_val = 200; printf("child change g_val: 100->200\n"); } } } else { while (1) { printf("father, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val); sleep(1); } } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
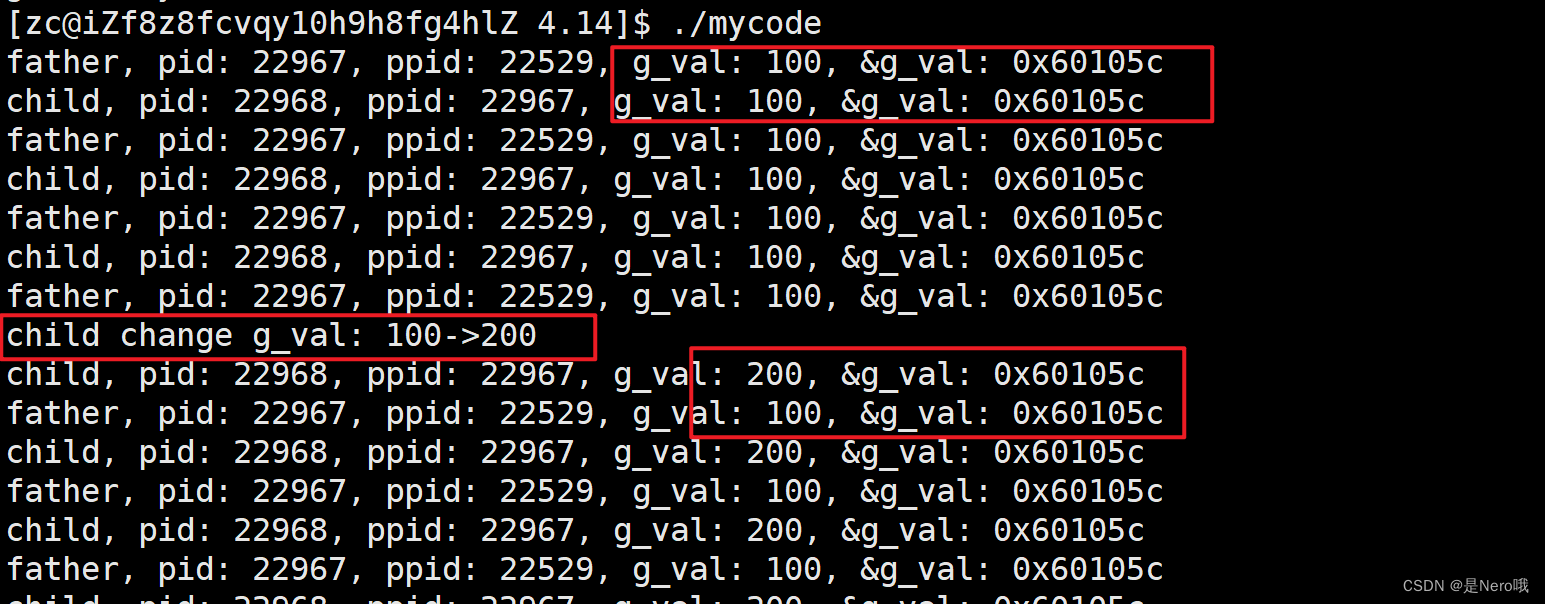
我们都知道父子进程共享代码段,那么一开始二者访问的
g_vla值和地址均相同后面子进程中改变
g_val的值后,二者值不同,但是地址还是一样
- 这就说明,我们看到的这个地址绝对不是物理地址。我们程这些地址为虚拟地址/线性地址
- 上面那些空间排布结构也不是在物理内存里。我们称之为:进程地址空间
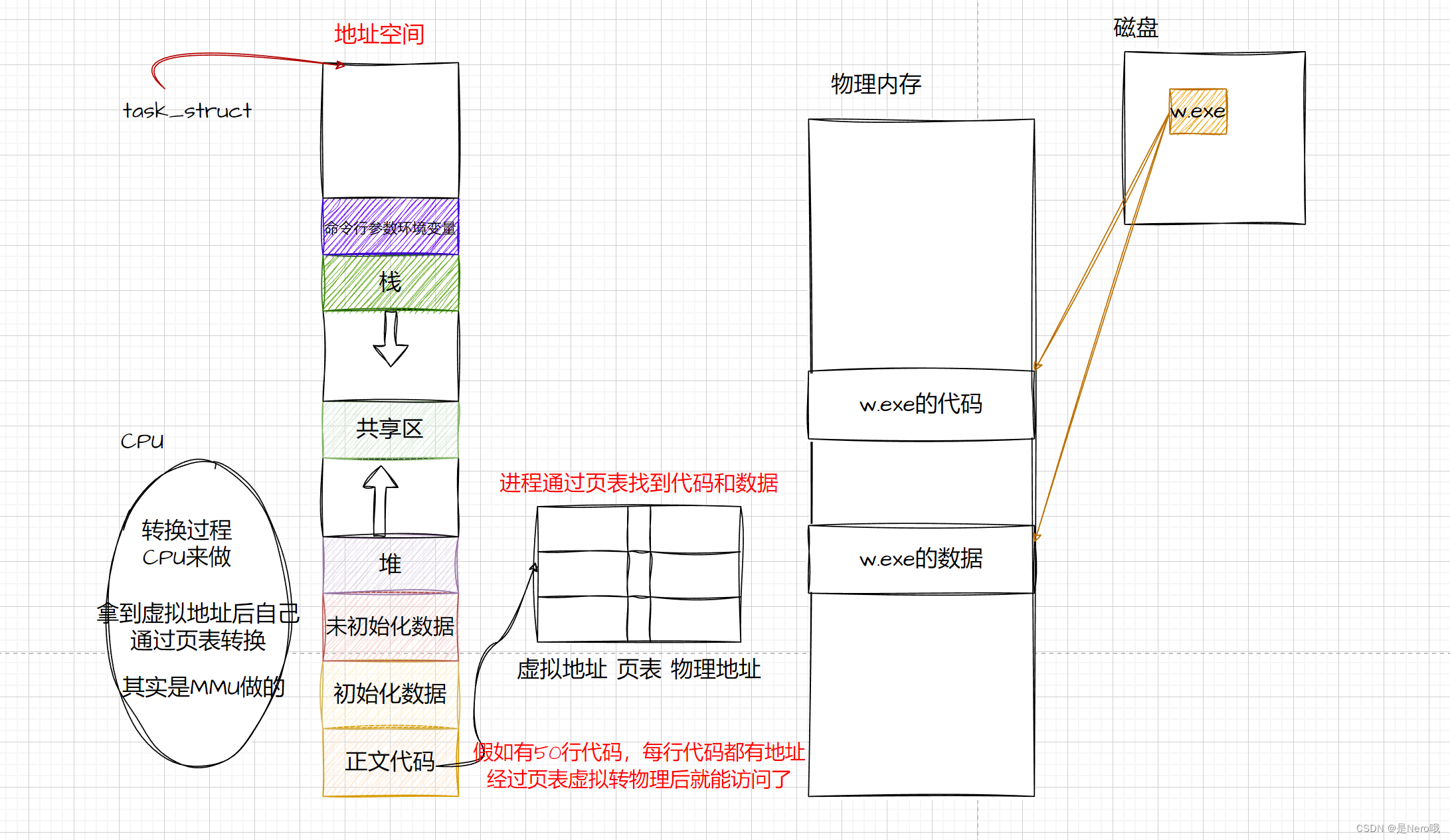
2.进程地址空间
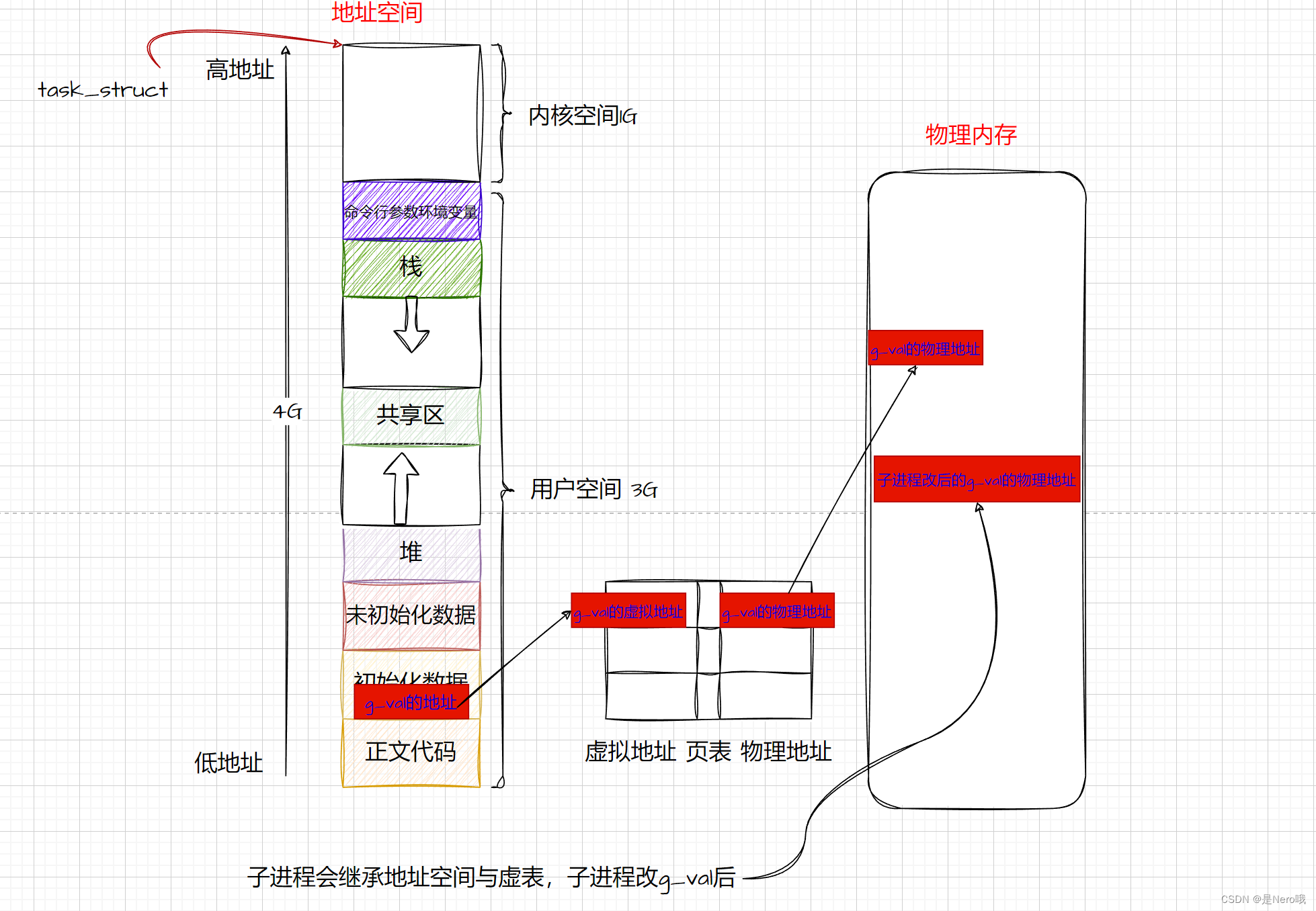
进程地址空间是操作系统中一个重要的概念,它描述了一个进程在运行时所能访问的虚拟地址范围。每个进程都有自己独立的地址空间,使得多个进程可以同时运行而互相不干扰
地址空间是指一个进程可以使用的内存范围,通常由连续的地址组成。对于32位系统,进程地址空间通常是从0到4GB,这个范围内包含了代码段、数据段、堆、栈等部分,用于存放程序的指令、数据以及动态分配的内存(就是我们上面那个图)
每个进程都有自己独立的地址空间,使得进程间可以互相隔离,不会相互干扰。在这个地址空间内,操作系统会进行地址映射,将进程的虚拟地址映射到物理内存上,以实现对内存的访问和管理。
当一个进程被创建时,操作系统会为该进程分配一块内存空间,用来存放进程的地址空间。这个地址空间是虚拟的,因为它并不直接对应物理内存中的连续空间,而是通过页表和页表项来映射到物理内存中的不同位置。
页表(Page Table)是操作系统中用于管理虚拟内存的重要数据结构之一。它将进程的虚拟地址映射到物理内存中的实际地址,实现了虚拟内存的地址转换和管理
明确几个点
-
程序与进程的区别
在操作系统中,程序和进程是两个不同的概念。
程序(Program)是一组指令的集合,是静态的代码文件,通常以可执行文件的形式存在。程序本身并不具有执行能力,只有当程序加载到内存中,并由操作系统创建一个进程来执行时,程序的指令才会被解释和执行。程序可以被多个进程同时执行,因为每个进程都有自己独立的地址空间,程序的指令在不同进程中是相互隔离的。
进程(Process)是操作系统中的一个执行实体,是程序在运行过程中的一个实例。进程包含了程序的代码、数据、堆栈等信息,以及操作系统为其分配的资源。每个进程都有自己独立的地址空间和执行流,可以独立运行、调度和管理。进程是操作系统中的基本执行单位,是程序在执行过程中的动态体现。
可以说进程是运行和执行的主体,程序只是进程执行的指令集合。程序需要被加载到内存中,由进程来执行,进程才是真正执行代码、管理资源、与其他进程交互的实体。
-
进程地址空间不直接保存代码和数据本身,而是提供了一种逻辑上的组织和管理方式,用于标识和访问这些代码和数据在物理内存中的位置。
当程序执行时,CPU会根据指令从进程地址空间中读取代码和数据,并进行相应的处理。这些代码和数据实际上是存储在物理内存中的,但通过地址映射机制,它们被映射到了进程地址空间中的对应位置,使得程序可以方便地访问和操作这些内容。
当我们说进程地址空间用于存储“不同类型的数据”时,实际上是指它组织和标识了这些数据和代码在物理内存中的位置。进程地址空间中的每个部分都通过虚拟地址来标识,这些虚拟地址在运行时会被操作系统和硬件转换为实际的物理地址,以便访问对应的内存位置
因此,可以说进程地址空间是用于组织和管理代码和数据的虚拟内存区域,而代码和数据本身实际存储在物理内存中。进程地址空间提供了一个抽象的视图,使得程序可以像访问内存一样访问代码和数据,而无需关心它们的实际存储位置。
-
虚拟地址并不是真实存在的物理内存地址,而是逻辑上的地址空间。虚拟地址空间是操作系统为每个进程提供的一个假象,使得进程仿佛拥有整个内存空间
-
进程地址空间可以理解成是一套规范,或者是一套边界,可以方便我们系统进行编辑性检查的一个东西
-
进程地址空间并不会把每个虚拟地址都显式地存储起来,而是存储了地址空间的区间范围以及相关的管理信息。这些区间范围定义了虚拟地址的边界,以及每个区间对应的内存属性(如可读、可写、可执行等)
进程地址空间不会存储每个使用的虚拟地址,而是会维护每个内存范围的开始与结束地址
当进程需要访问某个虚拟地址时,操作系统会根据该地址所属的内存范围,查找相应的页表或其他内存管理数据结构,以确定该地址对应的物理地址
-
进程地址空间中的虚拟地址是通过程序计数器、指令集和其他相关机制来使用的。当CPU执行进程中的指令时,它会根据程序计数器的值来获取下一条要执行的指令的虚拟地址
进程地址空间实质
代码和数据实际上是存储在物理内存中的,而进程空间(或称为虚拟地址空间)里存储的是代码和数据的虚拟地址。这些虚拟地址通过页表等机制映射到物理内存中的实际地址。
每个进程都有自己的虚拟地址空间,这个空间是逻辑上连续的,但并不一定在物理内存中连续。操作系统负责维护页表,将虚拟地址转换为物理地址,从而实现进程对内存的访问。
操作系统肯定也要对进程地址空间进行管理,那就说明也需要:先描述再组织
进程地址空间是数据结构,具体到进程中就是特定数据结构的对象。需要注意的是:这个结构体里不保存代码和数据
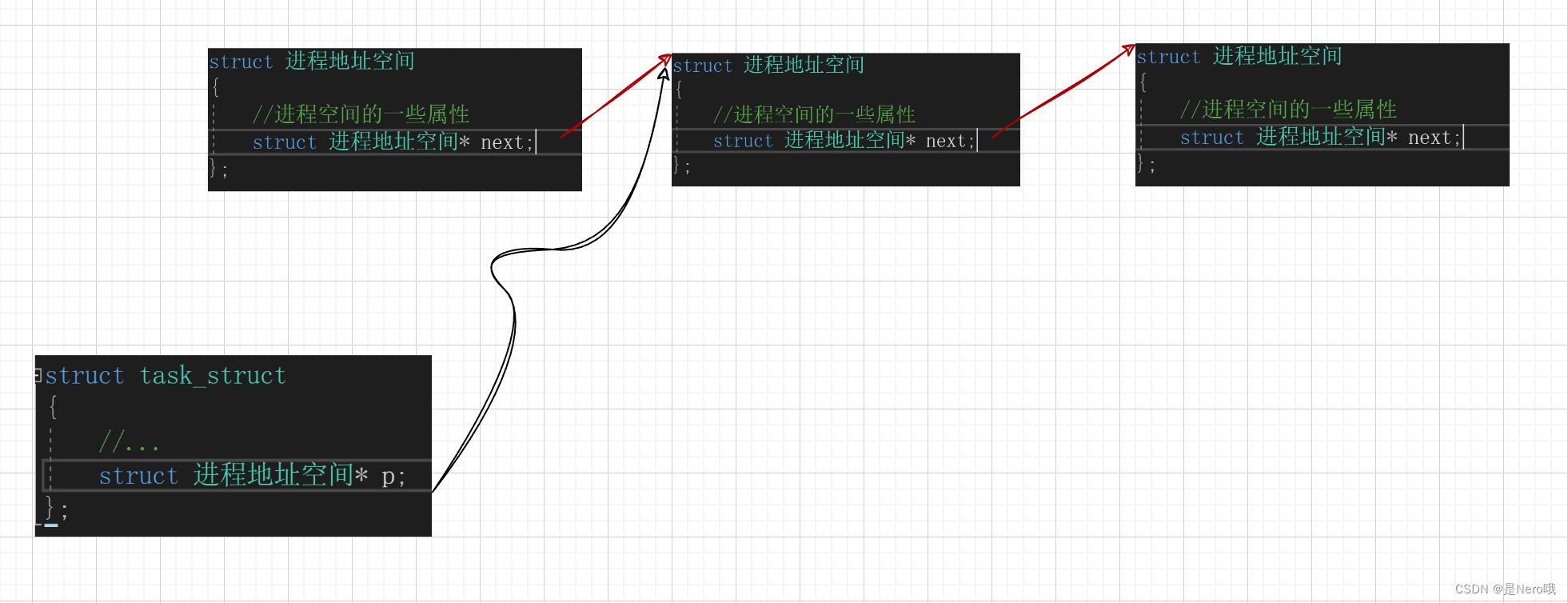
图示过程
2.1进程地址空间意义
地址空间和页表的结合是操作系统中实现虚拟内存管理的关键机制,它们的存在有助于解耦进程管理和内存管理,并提供了保护内存安全的重要手段。
-
统一的内存视图: 地址空间和页表的结合使得每个进程都拥有一个统一的内存视图,无论实际物理内存的情况如何,进程都可以将内存看作是一段连续的地址空间。这种统一的内存视图简化了程序的编写和调试过程,程序员可以使用相对地址来编写程序,而不必担心物理内存的实际情况。
-
解耦进程管理和内存管理: 地址空间和页表的存在使得进程管理和内存管理可以相互独立地进行,进程的创建、销毁和切换与物理内存的分配、回收和调度等操作是相互独立的。这种解耦合的设计有助于提高系统的模块化和可扩展性,使得系统更容易进行维护和升级。
-
保护内存安全: 页表是保护内存安全的重要手段之一,它通过设置页面的访问权限和保护位,可以防止程序对内存的非法访问和修改。例如,可以将某些页面设置为只读或只执行,防止程序对其进行写操作或执行恶意代码,从而提高了系统的安全性和稳定性。
-
内存管理的有效性: 通过地址空间和页表,操作系统可以实现虚拟内存管理,将逻辑地址映射到物理内存中,实现了内存的动态分配和管理。通过页面置换算法和页面驻留策略,可以实现对内存资源的有效利用,提高了系统的性能和效率。
-
地址空间共享和隔离: 地址空间的存在允许多个进程共享相同的代码和数据,从而节省内存空间,提高系统的资源利用率。同时,地址空间的隔离性保证了每个进程都拥有独立的地址空间,互不干扰,确保了系统的稳定性和安全性。
3.创建进程
3.1fork()函数创建子进程补充
我们之前已经讲了在代码里可以使用fork()函数来。创建子进程规则是:子进程与父进程共享代码,写时拷贝
进程调用fork,当控制转移到内核中的fork代码后,内核做:
分配新的内存块和内核数据结构给子进程
将父进程部分数据结构内容拷贝至子进程
添加子进程到系统进程列表当中
fork()函数返回,开始调度器调度
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程
-
共享代码怎么做到的?
子进程创建后,会拷贝父进程的进程地址空间和页表内容(相当于浅拷贝),页表内容相同。那么映射到的物理内存也是相同的,这样就做到了共享代码
写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本
Linux系统中,当使用fork()系统调用创建子进程时,子进程会继承父进程的地址空间的一个副本。但实际上,在fork()之后到子进程开始写数据之前,父进程和子进程所共享的是同一个物理内存页面。只有当其中一个进程尝试修改写入时,操作系统才会进行页面复制,确保每个进程都有自己的数据副本,从而避免了不必要的内存复制开销
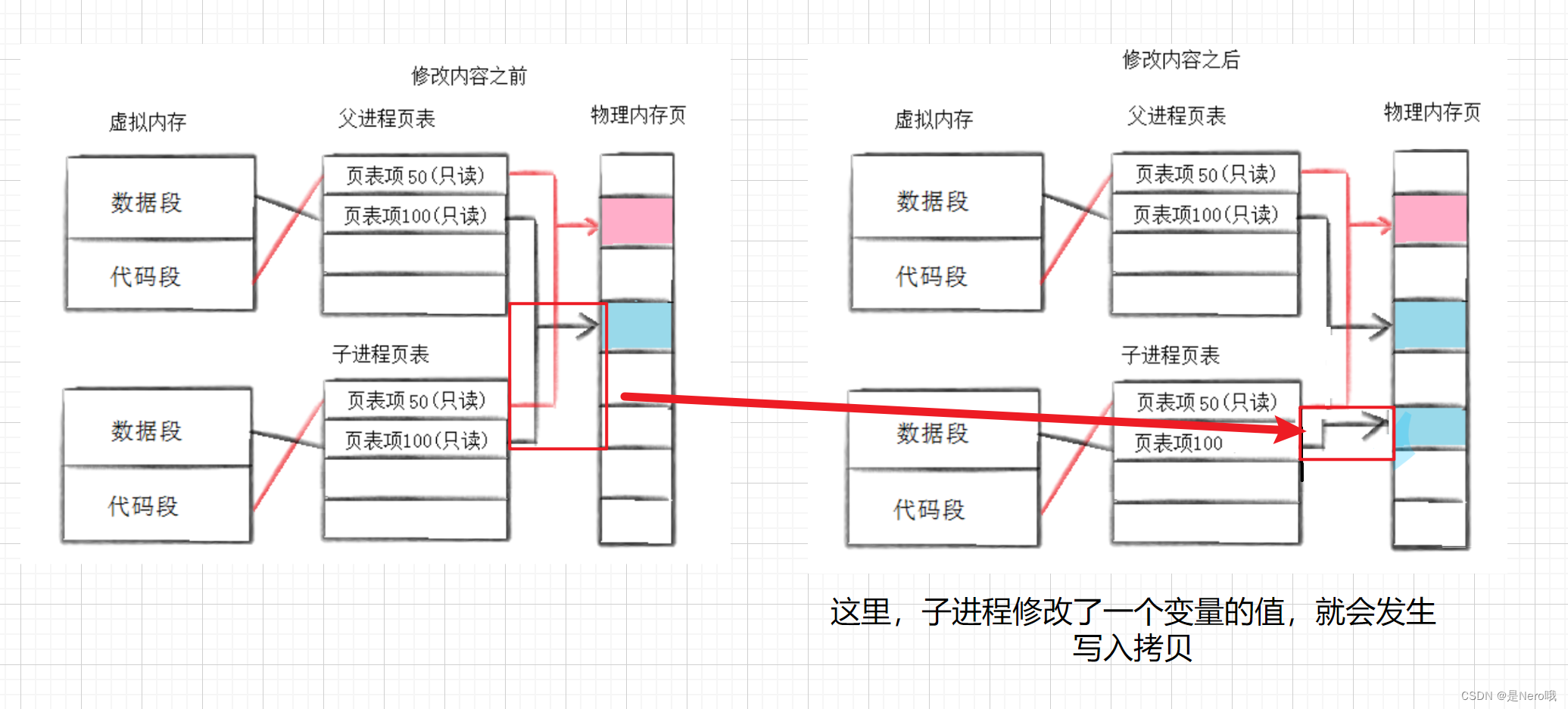
页表除了有一系列对应的虚拟地址和物理地址以外,还有一列代表权限(针对物理地址的内容的权限)
具体来说,权限字段通常包含以下几种权限:
- 读权限(r):当某个页表项的读权限被设置时,拥有该页表项的进程可以读取该页面上的数据。如果读权限未被设置,任何试图读取该页面的操作都会引发异常或错误。
- 写权限(w):写权限决定了进程是否可以修改页面上的数据。如果页表项的写权限被设置,进程可以对该页面进行写操作。否则,任何写操作都会被阻止。
除了读和写权限外,页表的权限字段还可能包含其他类型的权限,例如执行权限(x),它决定了进程是否可以在该页面上执行代码。在某些系统中,还可能存在特殊的权限字段,如用于控制页面共享、缓存策略等的字段。
所以上面写时拷贝的过程里:可以看到在修改内容之前,数据段里的权限也都是只读,这不对吧?(因为,全局变量我们是可以修改的啊)这是在创建子进程后,数据段的页表映射权限由rw权限变为r
为什么要改啊:改后,如果我们尝试写入,会发生错误,这时操作系统就会来完成写入拷贝,又发现你是数据段的本该可以写入,就又把需要写入的进程对应的页表映射由r权限改为rw了
4.进程终止
4.1进程退出场景
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
退出码
main函数的返回值通常被称为进程退出码或返回状态码。在C、C++等编程语言中,main函数是程序的入口点,当程序执行完毕后,main函数会返回一个整数值给操作系统,这个整数值就是进程退出码。操作系统会根据这个退出码来判断程序是正常结束还是出现了某种错误。我们自己写
main函数时,总是写一个return 0
- 返回0表示程序成功执行
- 非0值表示出现了某种错误。具体的非0值可能由程序员定义,用于表示不同的错误类型或状态。
Linux系统中,你可以使用
echo $?命令来查看上一个执行的命令或进程的退出码

但是光看一个数字,我们怎么能知道错误的原因呢? 这就需要把错误码转换为错误描述
错误码就是函数的
strerror()函数是一个C库函数,用于将错误代码转换为对应的错误信息字符串。它接受一个整数参数errno,返回一个指向错误信息字符串的指针。strerror函数的在头文件string.h中,
errno是一个全局变量,用于在C语言中表示发生错误时的错误码。当函数或系统调用发生错误时,errno会被设置为相应的错误码,以便程序可以根据错误码进行适当的错误处理。error是最近一次函数进行调用的返回值
char *strerror(int errnum);
- 1
其中,errnum参数是一个整数,代表特定的错误码。strerror函数会根据错误码在系统的错误码表中查找对应的错误信息,并将其作为字符串返回。
进程出现异常
进程出现异常说明进程收到了异常信号,每种信号都有自己的编号(宏编号),而不同的信号编号能表明异常的原因
kill -l 命令在 Unix 和 Linux 系统中用于列出所有可用的信号。执行这个命令将显示系统支持的所有信号的列表以及它们的编号。这对于了解不同信号的含义和用途非常有用,特别是在处理进程和进程间通信时。
下面是一个 kill -l 命令的典型输出示例:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT
17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU
25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH
29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN
35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 ...
...
63) SIGRTMAX-1 64) SIGRTMAX
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
一些常见的信号及其用途包括:
SIGTERM:请求进程终止。进程可以捕获这个信号并清理资源后正常退出。SIGINT:通常由用户按下 Ctrl+C 产生,用于中断前台进程。SIGKILL:强制终止进程,不能被进程捕获或忽略。SIGHUP:当控制终端(controlling terminal)被关闭时发送给进程,常用于让进程重新读取配置文件。
4.2进程常见退出方法
4.2.1正常退出
-
正常的从
main()函数返回 -
调用
exit()函数#include <unistd.h> void exit(int status);- 1
- 2
参数
status定义了进程的终止状态,也就是程序的退出码用于表示程序的执行状态,并帮助调用程序理解程序结束的原因- 在进程代码中,任意地方调用exit()函数都表示进程退出(不一定非要在main()函数里)
#include<stdio.h> #include<unistd.h> #include<stdlib.h> void Print() { printf("Now it's calling the Print function\n"); exit(10); } int main() { while(1) { printf("I'm a process:%d\n",getpid()); sleep(3); Print(); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
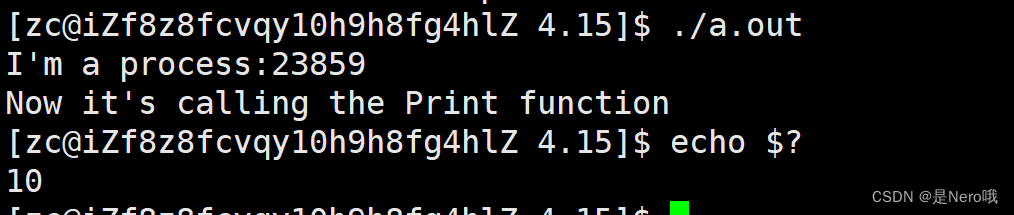
-
调用
_exit()函数与exit()函数的不同:
- exit()是一个标准C库函数,而_exit()通常被视为一个系统调用(可以知道exit底层肯定封装了__exti函数)
- 调用exit()时,它会执行一些清理工作,包括检测进程打开的文件情况,并将处于文件缓冲区的内容写入到文件中,然后才退出
- 而_exit()则直接退出,不会执行这些清理工作,也不会将缓冲区中的内容写入文件
4.2.2异常退出
使用ctrl + c,能使异常信号终止
进程最终执行情况
Linux系统中,任何进程最终执行完毕后都会返回一个状态码,这个状态码通常被称为“退出码”或“返回码”(exit code)。这个退出码是一个整数,用于表示进程执行的结果或状态。根据惯例,退出码0通常表示成功,而非零值表示出现了某种错误。
Linux的上下文中,我们通常讨论的是“信号”(signal),这些信号用于在进程之间传递信息或通知进程发生了某种事件(如中断、终止等)
- 退出码(exit code):一个整数,用于表示进程执行的结果或状态。0通常表示成功,非零值表示错误或异常情况。
- 信号(signal):用于在进程之间传递信息或通知进程发生了某种事件的机制。进程可以发送和接收信号,并对某些信号进行特定的处理。(就是我们上面讲的进程出现异常时收到的异常信号)
4.3 OS会做什么
当进程创建和进程终止时,操作系统会执行一系列的操作来确保系统的稳定性和资源管理的有效性。
进程创建时:
- 资源分配:操作系统为新进程分配必要的资源,如内存空间、文件描述符、打开的文件等。
- 复制父进程数据:新创建的子进程是父进程的副本,所以操作系统会复制父进程的部分数据结构内容到子进程,包括代码、数据、堆、栈等内容。然而,这种复制通常是“写时复制”(Copy-On-Write)的,即实际的物理内存页并不会立即复制,而是在子进程首次对这些页进行修改时才会进行复制。
- 设置进程ID:操作系统为每个新进程分配一个唯一的进程ID(PID),用于在系统中唯一标识该进程。
- 添加到进程列表:新创建的进程会被添加到系统的进程列表中,以便操作系统可以对其进行管理和调度。
- 执行fork系统调用:当父进程调用fork()函数时,操作系统会处理这个系统调用,完成上述操作,并返回相应的值给父进程和子进程。父进程收到的是子进程的PID,而子进程收到的是0。
进程终止时:
- 执行清理工作:进程在终止前会执行一些清理工作,比如关闭打开的文件、释放占用的内存等。如果进程是正常终止(比如调用exit()函数),操作系统还会捕获进程的退出状态码。
- 回收资源:操作系统回收进程占用的所有资源,包括内存、文件描述符、信号处理程序等。
- 处理僵尸进程:当一个进程终止时,它并不会立即从系统中消失。相反,它会变成一个僵尸进程(Zombie Process),直到其父进程调用wait()或waitpid()系统调用来回收它。操作系统会维护这些僵尸进程的信息,直到它们被父进程回收。
- 更新进程列表:操作系统会从进程列表中移除已终止的进程。
5.进程等待
5.1必要性
- 在Unix/Linux系统中,当子进程退出时,它的进程描述符仍然保留在系统中,直到父进程通过某种方式获取其退出状态。这个已经退出但进程描述符仍然保留在系统中的进程就被称为“僵尸进程”
- 一旦进程变成僵尸状态,即使是使用
kill -9这样的强制终止命令也无法直接“杀死”它。因为僵尸进程本身已经终止,只是其退出状态还没有被父进程读取 - 而且父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对, 或者是否正常退出
- 为了回收子进程的资源并获取其退出信息,父进程需要调用
wait()或waitpid()系统调用(进行进程等待)。这些调用会阻塞父进程,直到有子进程退出,并返回已退出子进程的PID和退出状态
5.2进程等待的方法
5.2.1 wait()方法
wait 方法在Linux 编程中是一个重要的系统调用,它主要用于监视先前启动的进程,并根据被等待的进程的运行结果返回相应的 Exit 状态。在父进程中,wait 方法常被用来回收子进程的资源并获取子进程的退出信息,从而避免产生僵尸进程。
wait 函数允许父进程等待其子进程结束,并可以获取子进程的退出状态。在C语言中的用法和参数:
函数原型
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
- 1
- 2
- 3
- 4
参数status:这是一个指向整数的指针,用于存储子进程的退出状态。如果父进程不关心子进程的退出状态,可以将这个参数设为 NULL。
返回值
- 返回值大于零时成功,返回已终止子进程的进程ID。
- 失败时,返回
-1,并设置全局变量errno以指示错误原因。
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> int main() { pid_t id = fork();//创建子进程 if (id == 0) { //这里面是子进程 int count = 5; while (count--) { printf("child is running. pid:%d , ppid:%d\n", getpid(), getppid()); sleep(1); //这里循环5秒 } printf("子进程将退出,马上就变成僵尸进程\n"); exit(0);//子进程退出了 } //这里是父进程 printf("父进程休眠\n"); sleep(10); printf("父进程开始回收了\n"); pid_t rid = wait(NULL);//让父进程进程阻塞等待 if (rid > 0) { printf("wait successfully, rid:%d\n", rid); } printf("父进程回收了\n"); sleep(5); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
代码一共15秒
- 0~5秒内:子进程与父进程都存在,5秒后子进程结束
- 5~10秒内:父进程正常运行,子进程在僵尸。10秒后父进程开始回收
- 10~15秒:父进程正常运行,15秒后父进程结束
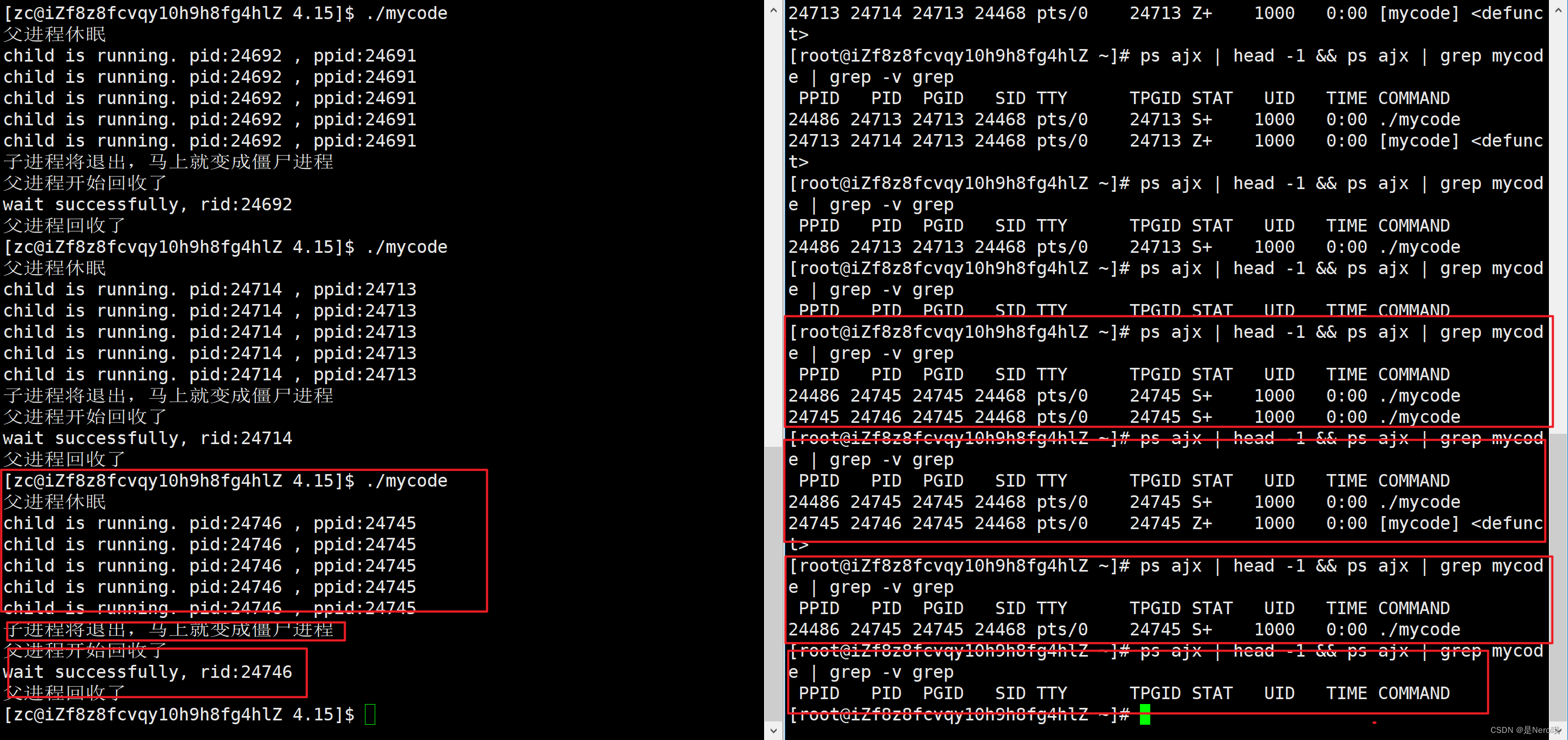
5.2.2waitpid()方法
waitpid 是 Unix 和 Linux 系统编程中用于等待子进程结束并获取其状态的系统调用。它的原型如下:
pid_t waitpid(pid_t pid, int *status, int options);
- 1
返回值
-
当正常返回的时候waitpid返回收集到的子进程的进程ID;
-
如果
options参数中设置了WNOHANG,并且没有已退出的子进程可收集,则waitpid返回0。 -
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在
参数
-
pid:
-
Pid=-1,等待任一个子进程。与wait等效。
-
Pid>0.等待其进程ID与pid相等的子进程
-
-
status:这是一个指向整数的指针,用于存储子进程的退出状态。如果不需要这个信息,可以传递
NULL。WIFEXITED(status):宏函数,如果子进程正常退出,返回非零值;否则返回0。WEXITSTATUS(status):宏函数,如果WIFEXITED(status)为真,则返回子进程的退出码。(后面就能理解这两个用处)
-
options:这是一个位掩码,用于修改
waitpid的行为。WNOHANG:如果指定了此选项,waitpid将不会阻塞,而是立即返回(父进程不会等待子进程了)。如果指定的子进程没有结束,则waitpid返回0;如果子进程已结束,则返回子进程的ID。- 传递
0作为options参数时,你实际上是在告诉waitpid使用最传统的阻塞方式等待子进程终止,并且只关心那些已经终止的子进程
如果子进程已经退出,调用wait/waitpid时,wait/waitpid会立即返回,并且释放资源,获得子进程退出信息。
如果在任意时刻调用wait/waitpid,子进程存在且正常运行,则进程可能阻塞。
如果不存在该子进程,则立即出错返回。
获取子进程status
wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。
如果传递NULL,表示不关心子进程的退出状态信息。
否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
我们上面说:任何进程最终的执行情况,我们可以使用两个数字表明具体执行的情况——退出码和退出信号。这里status就是将两者结合起来的,使用位图结合
status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图:

#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> int main() { pid_t id = fork(); if(id == 0) { // child int cnt = 5; while(cnt) { printf("Child is running, pid: %d, ppid: %d\n", getpid(), getppid()); sleep(1); cnt--; } exit(1); } int status = 0; pid_t rid = waitpid(id, &status, 0); // 阻塞等待 if(rid > 0) { printf("wait successfully, rid: %d, status: %d\n", rid, status); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
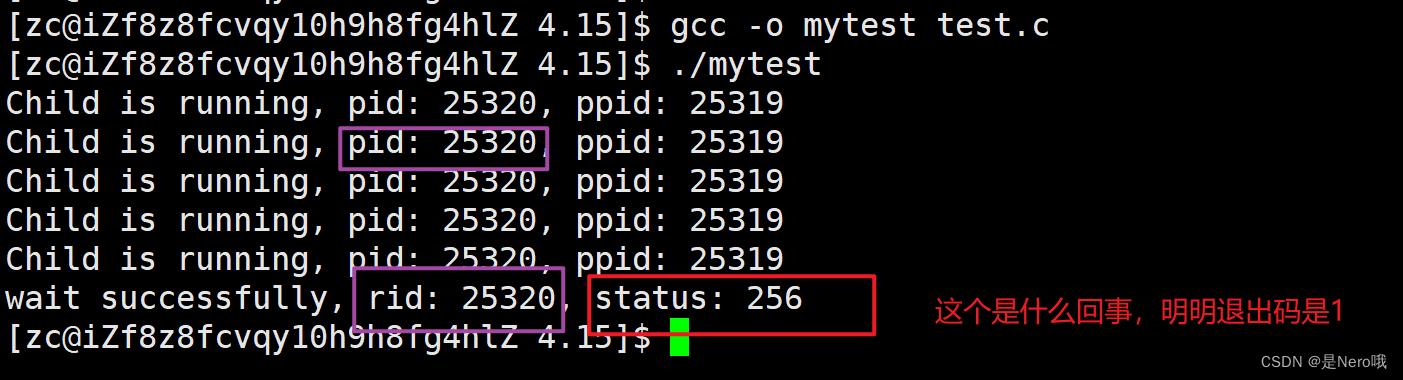

那我们怎么直接获得退出码和信号编号呢?
-
我们能自己针对status进行位运算
-
使用上面的WIFEXITED(status)、WEXITSTATUS(status)
int main() { pid_t id = fork(); if (id == 0) { int cnt = 5; while (cnt) { printf("Child is running, pid: %d, ppid: %d\n", getpid(), getppid()); sleep(1); cnt--; } exit(1); } int status = 0; pid_t rid = waitpid(id, &status, 0); if (rid > 0) { if (WIFEXITED(status)) { printf("wait successfully, rid: %d, status: %d\n", rid, status); printf("wait successfully, rid: %d, status: %d, exit code: %d\n", rid, status,WEXITSTATUS(status)); } else { printf("wait wrongly\n"); } } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34

5.3阻塞等待与非阻塞等待
阻塞等待(wait()与waitpid( , , 0)):
- 当进程执行某个操作时,如果该操作需要等待子进程结束,进程会进入阻塞状态。
- 在阻塞状态下,进程会暂停执行,释放CPU资源,将进程状态保存起来,以便在条件满足后能够恢复执行。
- 阻塞等待期间,进程无法执行其他任务,只能等待条件满足或事件发生。
非阻塞等待:
- 与阻塞等待不同,非阻塞等待允许进程在等待子进程结束期间继续执行其他任务。
- 非阻塞等待通常通过轮询或异步通知机制实现,进程会定期检查条件是否满足,或者在条件满足时接收通知。
int main() { pid_t id = fork(); if (id == 0) { int cnt = 5; while (cnt) { printf("Child is running, pid: %d, ppid: %d\n", getpid(), getppid()); sleep(1); cnt--; } exit(1); } int status = 0; pid_t rid = waitpid(id, &status, WNOHANG); while (1) { if (rid > 0) { //子进程结束了 printf("wait successfully, rid: %d, status: %d, exit code: %d\n", rid, status, WEXITSTATUS(status)); break; } else if (rid = 0) { //子进程还没结束 //这里能写希望在子进程没结束期间希望父进程干什么 } else { //到这里就说明出错了 perror("waitpid"); break; } } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
今天的内容也是不少了,累死了。感谢大家支持!!!


