
- 1java 支付宝 第三方即时到账支付 接口
- 2[云原生专题-18]:容器 - docker自带的集群管理工具swarm - 手工搭建集群服务全过程详细解读_在dockerswarm集群中创建服务
- 3火车头采集器伪原创【php源码】
- 4秒懂AI-深度学习五大模型:RNN、CNN、Transformer、BERT、GPT简介_gpt是rnn吗
- 5WebGL 与 WebGPU比对[5] - 渲染计算的过程_webgpurenderer和webglrenderer
- 6git push命令时出现错误:fatal:HttpRequestException encountered,该怎么解决?_fatal: httprequestexception encountered
- 7苹果电脑版 植物大战僵尸杂交版 v2.1 修复已损坏提示教程_植物大战僵尸v2.1
- 8启动hive时报错:Required table missing : “`VERSION`“ in Catalog ““ Schema ““._required table missing : "`version`" in catalog ""
- 9【数据结构与算法】树结构(二叉树)_数据结构与算法树结构代码
- 10关于vcf文件的读取_readvcf
7、Qwen-7B 部署实践_qwen7b
赞
踩
1、Qwen(通义千问)介绍
Qwen(通义千问)由阿里云团队研发,其训练数据覆盖多语言,但主要以中文和英文为主。Qwen的系列模型主要有两类,一类是基座模型Qwen,所谓基座模型,指的是在海量的数据集上进行预训练,这些数据集可能包含了广泛的主题、语境和样式,使得基座模型能够捕捉到丰富的语言特征和通用知识。另外一类是Chat类模型,是利用SFT和RLHF技术实现对齐,从基座模型训练得到对话模型。
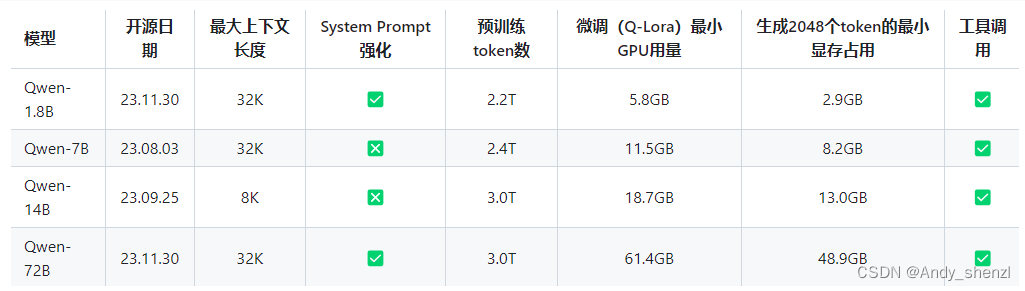
目前开源模型的参数规模为18亿(1.8B)、70亿(7B)、140亿(14B)和720亿(72B)。包括基础模型Qwen,即Qwen-1.8B、Qwen-7B、Qwen-14B、Qwen-72B,以及对话模型Qwen-Chat,即Qwen-1.8B-Chat、Qwen-7B-Chat、Qwen-14B-Chat和Qwen-72B-Chat。
| 模型 | 最大上下文长度 | 微调(Q-Lora)最小GPU用量 | 生成2048个token的最小显存占用 | 工具调用 |
|---|---|---|---|---|
| Qwen-1.8B | 32K | 5.8GB | 2.9GB | ✅ |
| Qwen-7B | 32K | 11.5GB | 8.2GB | ✅ |
| Qwen-14B | 8K | 18.7GB | 13.0GB | ✅ |
| Qwen-72B | 32K | 61.4GB | 48.9GB | ✅ |
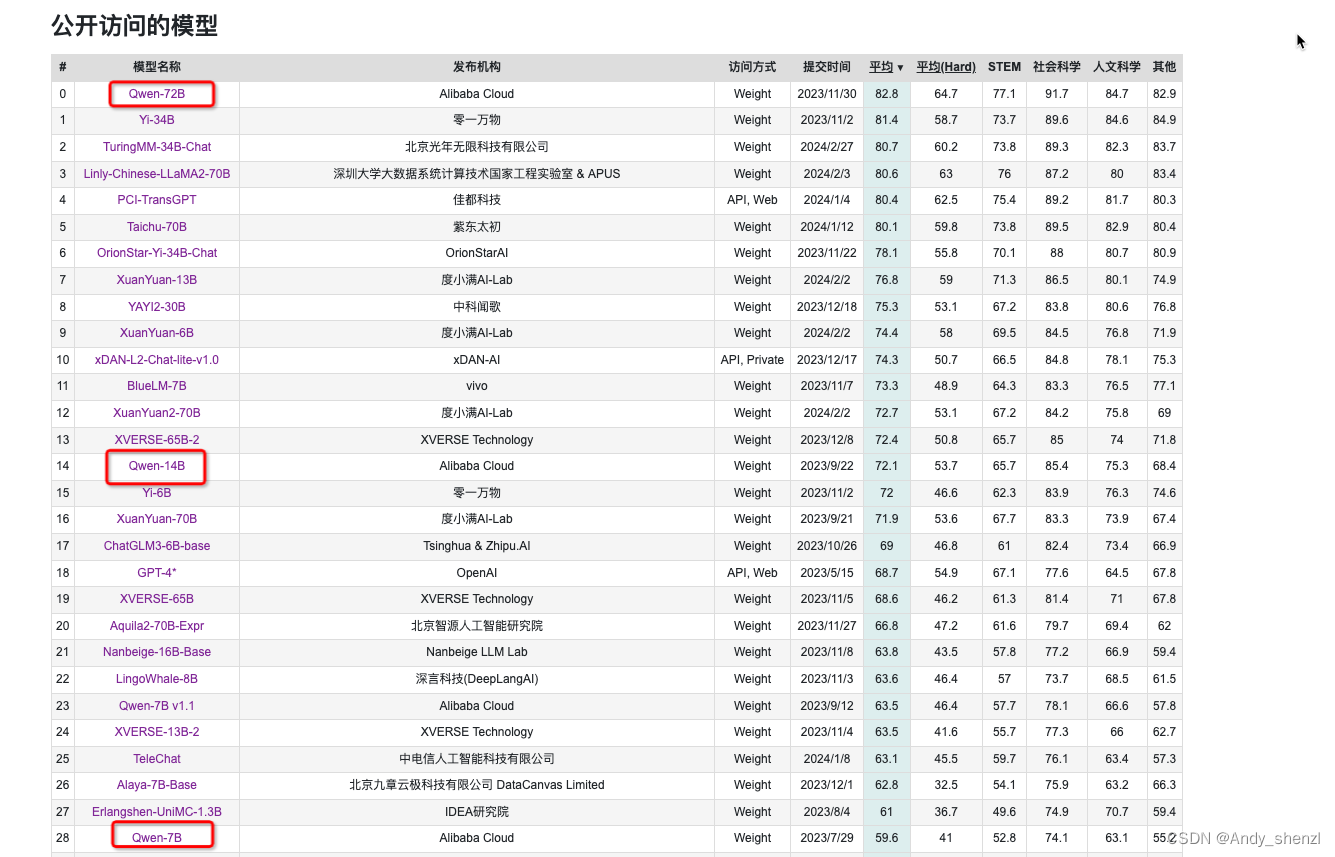
对于比较关注中文需求的来说,可以通过C-Eal榜单来初步确定模型的整体性能情况:https://github.com/hkust-nlp/ceval/tree/main
C-Eval是一个由清华大学、上海交通大学和爱丁堡大学合作构建的中文语言模型综合性考试评测集。它包含13948个多项选择题,覆盖了52个不同的学科和四个难度级别。C-Eval的目的是评估各种中文语言模型的表现。这个榜单为各种基础模型提供了一个评估基准,帮助理解和比较不同模型的性能。
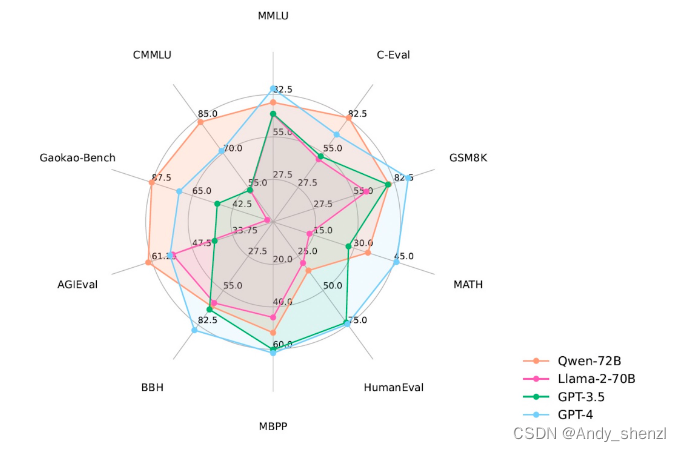
Qwen系列模型相比同规模模型均实现了效果的显著提升。评测的数据集包括MMLU、C-Eval、 GSM8K、 MATH、HumanEval、MBPP、BBH等数据集,考察的能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。Qwen-72B在所有任务上均超越了LLaMA2-70B的性能,同时在10项任务中的7项任务中超越GPT-3.5。
2、部署
本次开源包括基础模型Qwen,即Qwen-1.8B、Qwen-7B、Qwen-14B、Qwen-72B,以及对话模型Qwen-Chat,即Qwen-1.8B-Chat、Qwen-7B-Chat、Qwen-14B-Chat和Qwen-72B-Chat。其Github地址:https://github.com/QwenLM/Qwen/tree/main
对于本地部署来说,开源的模型的部署方式和启动方式都是一样的。不同之处主要在于模型的大小。更大的模型会占用更多的存储空间和显存。因此,本期内容适用于各种规模的模型部署,大家可以根据自己机器的实际性能,选择最适合的模型进行部署和实践。
2.1 下载权重文件
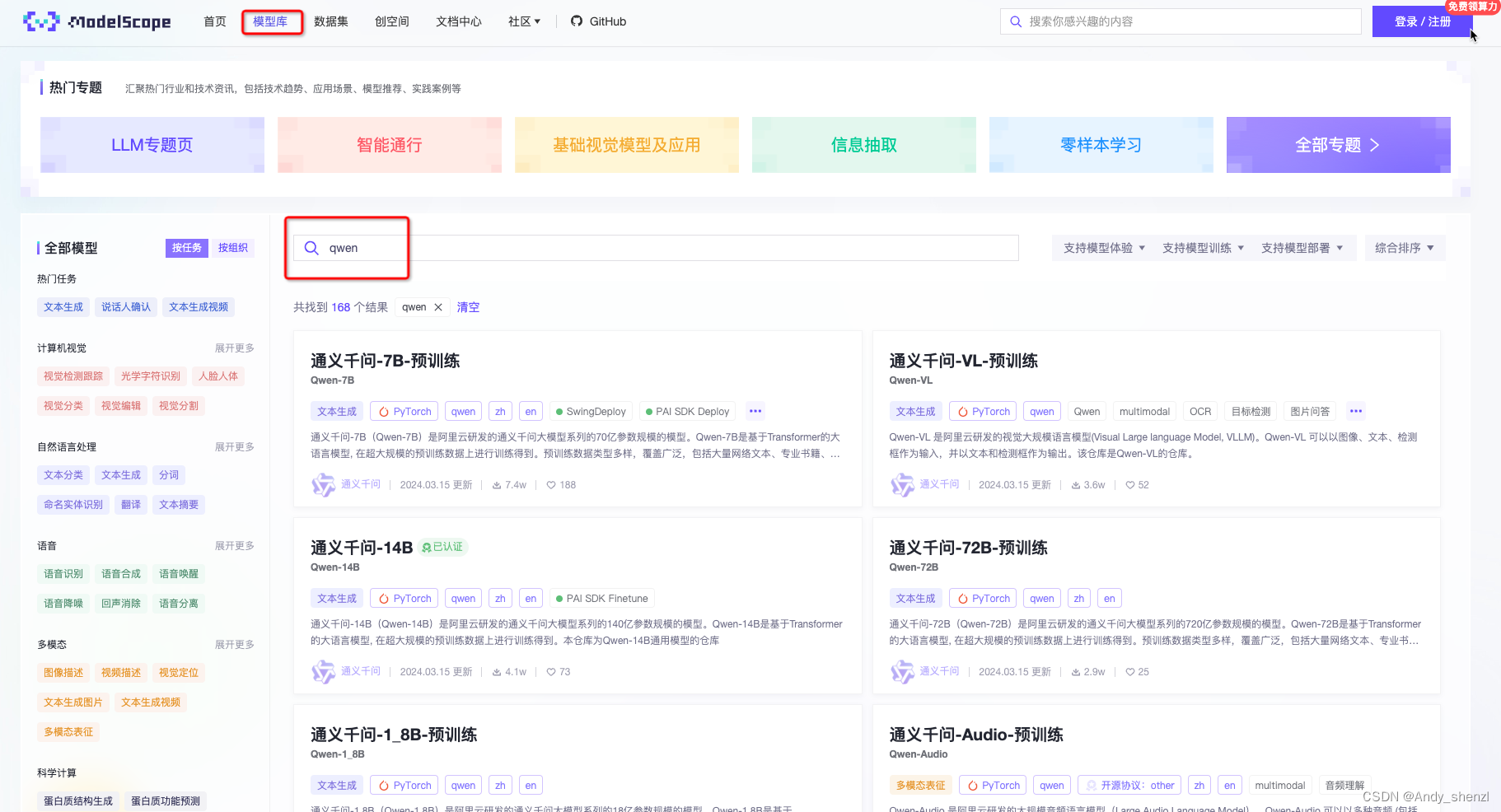
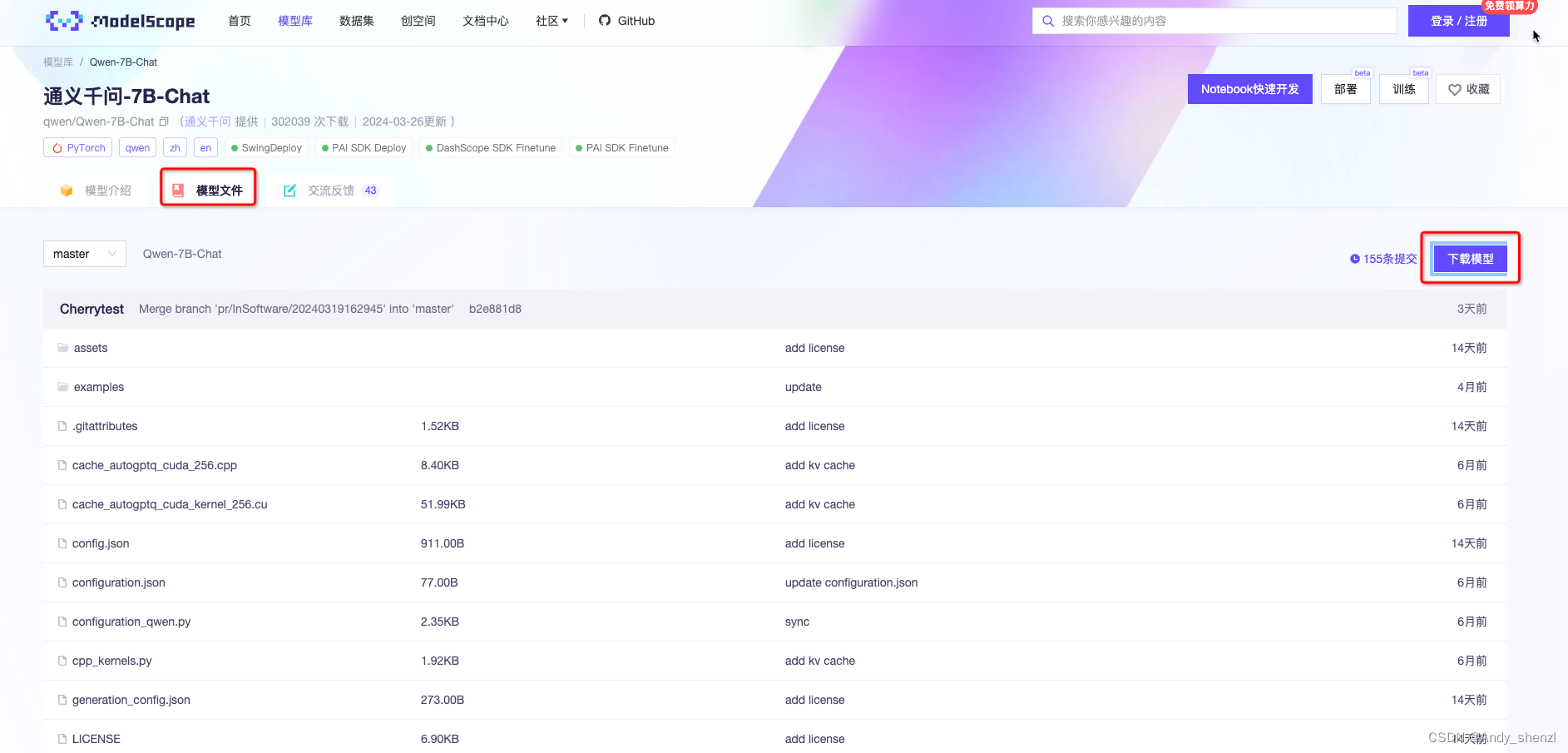
pip install modelscope
- 1
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-7B-Chat')
- 1
- 2
- 3
下载的速度还是很快的,

下载完成后,文件默认在
./root/.cache/modelscope/hub
- 1
我们可以使用find函数查查找一下:
find . -type d -name "modelscope"
./root/miniconda3/lib/python3.8/site-packages/modelscope
./root/.cache/modelscope
- 1
- 2
- 3
第二个就是文件的路径,cd进去看一下
cd ./root/.cache/modelscope
cd hub
ls
> qwen temp
- 1
- 2
- 3
- 4
进入qwen
cd qwen
ls
>Qwen-7B-Chat
cd Qwen-7B-Chat
ls
- 1
- 2
- 3
- 4
- 5

可以把文件移动到自己需要的位置
mv /root/.cache/modelscope/hub/qwen /root/autodl-tmp/model/
- 1
2.2 下载Qwen-7B-Chat的项目文件
https://github.com/QwenLM/Qwen/tree/main
c
git clone https://github.com/QwenLM/Qwen.git
- 1
2.3 运行
2.3.1 在命令行终端启动交互式对话
首先,最简单的方法是直接使用官方提供的简单的交互式Demo,可以直接在终端输入文字的方式和Qwen-7B-Chat交互,并流式输出返回结果。
使用vim cli_demo.py命令编辑这个文件,仅需要修改一下Qwen模型的指向路径即可。默认是从云端加载,因为我们已经下载到了本地,需要改为本地的实际存储路径。
vim cli_demo.py
- 1
修改模型权重文件的路径
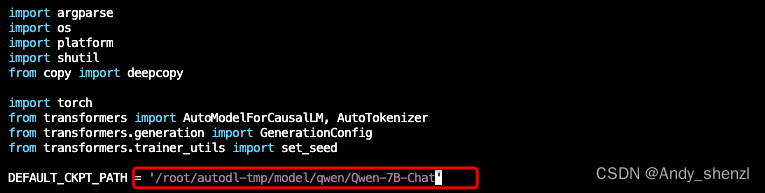
保存后,使用python cli_demo.py启动服务。
python cli_demo.py
- 1

操作信息:
Commands:
:help / :h Show this help message 显示帮助信息
:exit / :quit / :q Exit the demo 退出Demo
:clear / :cl Clear screen 清屏
:clear-his / :clh Clear history 清除对话历史
:history / :his Show history 显示对话历史
:seed Show current random seed 显示当前随机种子
:seed <N> Set random seed to <N> 设置随机种子
:conf Show current generation config 显示生成配置
:conf <key>=<value> Change generation config 修改生成配置
:reset-conf Reset generation config 重置生成配置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.3.2 使用Web UI启动
官方提供了Web UI的demo供我们使用,其借助gradio库来实现,gradio是一个Python库,用于快速创建用于演示机器学习模型的Web界面。开发者可以用几行代码为模型创建输入和输出接口,用户可以通过这些接口与模型进行交互。用户可以轻松地测试和使用机器学习模型,比如通过上传图片来测试图像识别模型,或者输入文本来测试自然语言处理模型。Gradio非常适合于快速原型设计和模型展示。
所以在使用这种方式启动Qwen模型前,需要安装一下相关的依赖库。在项目文件中,有requirements_web_demo.txt这样一个文件,记录了需要安装的依赖包及其精确的版本。
同样可以一次性安装需要的依赖包。执行如下命令:
pip install -r requirements_web_demo.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
接下来使用vim web_demo.py命令编辑这个文件,仅需要修改一下Qwen模型的指向路径即可。默认是从云端加载,因为我们已经下载到了本地,需要改为本地的实际存储路径。
保存后,使用python cli_demo.py启动服务。

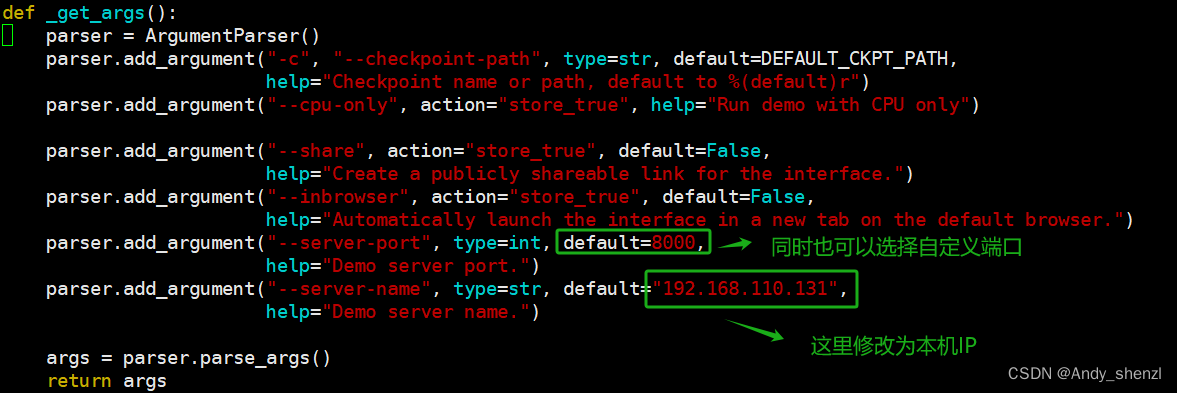
如果你是本机部署服务,且是在本机浏览器中访问,直接通过
127.0.0.1:10000地址访问是完全没有问题的。而如果你是远程服务器或者通过SSH远程局域网内的服务器,需要明确指定本机的IP才可以。操作过程如下:
首先通过ifconfig查看一下本机的地址。
然后使用vim编辑器,修改web_demo.py中程序启动的默认IP地址。
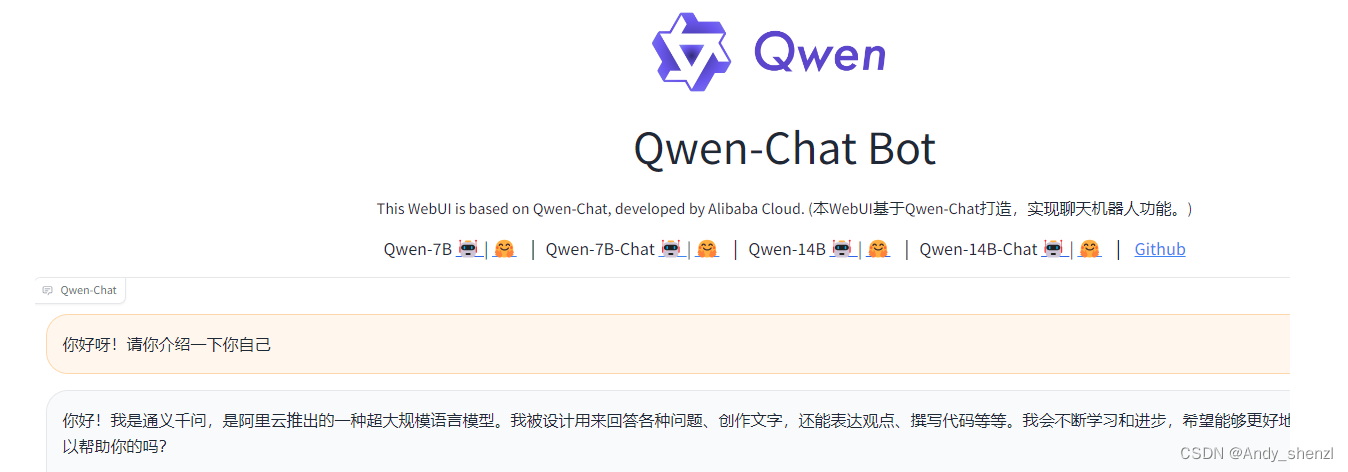
通过这种方式,就可以实现远程机器启动服务,在本机的Web页面使用。注意:如果是使用云服务器,需要确保设置的是公网IP且端口已启用。正常访问情况如下:
2.3.3 使用OpenAI风格调用(推荐)
Qwen的API服务依托于FastAPI框架,其是基于标准的 Python 类型提示,并且是基于 OpenAPI 和 JSON Schema 的,主要用于构建 API服务。其代码流程写在Qwen项目文件目录下的openai_api.py文件中。
既然是使用fastapi框架编写的,所以自然在启动前需要安装fastapi依赖包。
然后,需要使用vim编辑器,修改openai_api.py模型权重地址
修改完成后,回到终端中使用python openai_api.py启动API服务。

随后即可运行以下命令部署你的本地API:
import openai
openai.api_base = "http://127.0.0.1:8000/v1"
openai.api_key = "none"
# 使用流式回复的请求
for chunk in openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
# 流式输出的自定义stopwords功能尚未支持,正在开发中
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
>你好!有什么我能帮助你的吗?
# 不使用流式回复的请求
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=False,
stop=[] # 在此处添加自定义的stop words 例如ReAct prompting时需要增加: stop=["Observation:"]。
)
print(response.choices[0].message.content)
>你好!很高兴为你提供帮助。有什么我能帮你的吗?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30

