
- 1Unity性能优化篇(七) UI优化注意事项以及使用Sprite Atlas打包精灵图集_unity ui优化 需要将missing reference改为none吗
- 251-33 LDM 潜在扩散模型论文精读 + DDPM 扩散模型代码实现_ldm模型
- 3LLamaFactory:当下最容易上手的大模型微调工具_llama factory
- 4YOLOv8初学者手册(Detect、Segment、Classify、OBB、Pose)_yolov8 rtdetr obb pose
- 52023年PMP考试重要时间节点来了!别说没提醒你!_pmp考试时间2023
- 6设置电子围栏 高德地图_Android 高德地图的使用, 根据手势拖动绘制电子围栏
- 7dlopen(cpython-39-darwin.so, 0x0002): symbol not found in flat namespace ‘_CFRelease‘_openexr.cpython-39-darwin.so ymbol not found in fl
- 8计算机音乐谱夜空中最亮的星歌词,夜空中最亮的星歌谱及歌词
- 9自适应相关滤波 with LSTM网络 for 目标追踪_lstm 目标跟踪
- 10git clone 一部分_git日常使用和常见的命令
【深度学习】【机器学习】用神经网络进行入侵检测,NSL-KDD数据集,基于机器学习(深度学习)判断网络入侵,网络攻击,流量异常_nsl kdd数据集
赞
踩
【深度学习】用神经网络进行入侵检测,NSL-KDD数据集,用网络连接特征判断是否是网络入侵。
下载数据集NSL-KDD
NSL-KDD数据集,有dos,u2r,r21,probe等类型的攻击,和普通的正常的流量,即是有五个类别:
1、Normal:正常记录
2、DOS:拒绝服务攻击
3、PROBE:监视和其他探测活动
4、R2L:来自远程机器的非法访问
5、U2R:普通用户对本地超级用户特权的非法访问
数据集样子如下,一行就是一个样本。一个样本有41个特征和一个类别标签。

数据集介绍
https://towardsdatascience.com/a-deeper-dive-into-the-nsl-kdd-data-set-15c753364657
https://mathpretty.com/10244.html
输入的41个特征介绍
下面是对网络连接的41个特征的介绍:
| 特征编号 | 特征名称 | 特征描述 | 类型 | 范围 |
|---|---|---|---|---|
| 1 | duration | 连接持续时间,从TCP连接建立到结束的时间,或每个UDP数据包的连接时间 | 连续 | [0, 58329]秒 |
| 2 | protocol_type | 协议类型,可能值为TCP, UDP, ICMP | 离散 | - |
| 3 | service | 目标主机的网络服务类型,共70种可能值 | 离散 | - |
| 4 | flag | 连接状态,11种可能值,表示连接是否按照协议要求开始或完成 | 离散 | - |
| 5 | src_bytes | 从源主机到目标主机的数据的字节数 | 连续 | [0, 1379963888] |
| 6 | dst_bytes | 从目标主机到源主机的数据的字节数 | 连续 | [0, 1309937401] |
| 7 | land | 若连接来自/送达同一个主机/端口则为1,否则为0 | 离散 | 0或1 |
| 8 | wrong_fragment | 错误分段的数量 | 连续 | [0, 3] |
| 9 | urgent | 加急包的个数 | 连续 | [0, 14] |
| 10 | hot | 访问系统敏感文件和目录的次数 | 连续 | [0, 101] |
| 11 | num_failed_logins | 登录尝试失败的次数 | 连续 | [0, 5] |
| 12 | logged_in | 成功登录则为1,否则为0 | 离散 | 0或1 |
| 13 | num_compromised | compromised条件出现的次数 | 连续 | [0, 7479] |
| 14 | root_shell | 若获得root shell 则为1,否则为0 | 离散 | 0或1 |
| 15 | su_attempted | 若出现"su root" 命令则为1,否则为0 | 离散 | 0或1 |
| 16 | num_root | root用户访问次数 | 连续 | [0, 7468] |
| 17 | num_file_creations | 文件创建操作的次数 | 连续 | [0, 100] |
| 18 | num_shells | 使用shell命令的次数 | 连续 | [0, 5] |
| 19 | num_access_files | 访问控制文件的次数 | 连续 | [0, 9] |
| 20 | num_outbound_cmds | 一个FTP会话中出站连接的次数 | 连续 | 0 |
| 21 | is_hot_login | 登录是否属于“hot”列表,是为1,否则为0 | 离散 | 0或1 |
| 22 | is_guest_login | 若是guest登录则为1,否则为0 | 离散 | 0或1 |
| 23 | count | 过去两秒内,与当前连接具有相同的目标主机的连接数 | 连续 | [0, 511] |
| 24 | srv_count | 过去两秒内,与当前连接具有相同服务的连接数 | 连续 | [0, 511] |
| 25 | serror_rate | 过去两秒内,在与当前连接具有相同目标主机的连接中,出现“SYN”错误的连接的百分比 | 连续 | [0.00, 1.00] |
| 26 | srv_serror_rate | 过去两秒内,在与当前连接具有相同服务的连接中,出现“SYN”错误的连接的百分比 | 连续 | [0.00, 1.00] |
| 27 | rerror_rate | 过去两秒内,在与当前连接具有相同目标主机的连接中,出现“REJ”错误的连接的百分比 | 连续 | [0.00, 1.00] |
| 28 | srv_rerror_rate | 过去两秒内,在与当前连接具有相同服务的连接中,出现“REJ”错误的连接的百分比 | 连续 | [0.00, 1.00] |
| 29 | same_srv_rate | 过去两秒内,在与当前连接具有相同目标主机的连接中,与当前连接具有相同服务的连接的百分比 | 连续 | [0.00, 1.00] |
| 30 | diff_srv_rate | 过去两秒内,在与当前连接具有相同目标主机的连接中,与当前连接具有不同服务的连接的百分比 | 连续 | [0.00, 1.00] |
| 31 | srv_diff_host_rate | 过去两秒内,在与当前连接具有相同服务的连接中,与当前连接具有不同目标主机的连接的百分比 | 连续 | [0.00, 1.00] |
| 32 | dst_host_count | 前100个连接中,与当前连接具有相同目标主机的连接数 | 连续 | [0, 255] |
| 33 | dst_host_srv_count | 前100个连接中,与当前连接具有相同目标主机相同服务的连接数 | 连续 | [0, 255] |
| 34 | dst_host_same_srv_rate | 前100个连接中,与当前连接具有相同目标主机相同服务的连接所占的百分比 | 连续 | [0.00, 1.00] |
| 35 | dst_host_diff_srv_rate | 前100个连接中,与当前连接具有相同目标主机不同服务的连接所占的百分比 | 连续 | [0.00, 1.00] |
| 36 | dst_host_same_src_port_rate | 前100个连接中,与当前连接具有相同目标主机相同源端口的连接所占的百分比 | 连续 | [0.00, 1.00] |
| 37 | dst_host_srv_diff_host_rate | 前100个连接中,与当前连接具有相同目标主机相同服务的连接中,与当前连接具有不同源主机的连接所占的百分比 | 连续 | [0.00, 1.00] |
| 38 | dst_host_serror_rate | 前100个连接中,与当前连接具有相同目标主机的连接中,出现SYN错误的连接所占的百分比 | 连续 | [0.00, 1.00] |
| 39 | dst_host_srv_serror_rate | 前100个连接中,与当前连接具有相同目标主机相同服务的连接中,出现SYN错误的连接所占的百分比 | 连续 | [0.00, 1.00] |
| 40 | dst_host_rerror_rate | 前100个连接中,与当前连接具有相同目标主机的连接中,出现REJ错误的连接所占的百分比 | 连续 | [0.00, 1.00] |
| 41 | dst_host_srv_rerror_rate | 前100个连接中,与当前连接具有相同目标主机相同服务的连接中,出现REJ错误的连接所占的百分比 | 连续 | [0.00, 1.00] |
这个表格提供了关于网络连接的41个特征的详细介绍,包括特征编号、特征名称、特征描述、类型以及范围。
输出的五个类别
数据集是一个csv表格,倒数第二列就是类别标签,类别是五个,但是csv表格里分得很细。
['normal', 'dos', 'probe', 'r2l', 'u2r']
- 1
- 2
但csv里写的详细的标签如下图,比如Dos攻击往细了分,还有back、neptune之类的,但我们只关心五个大类别。
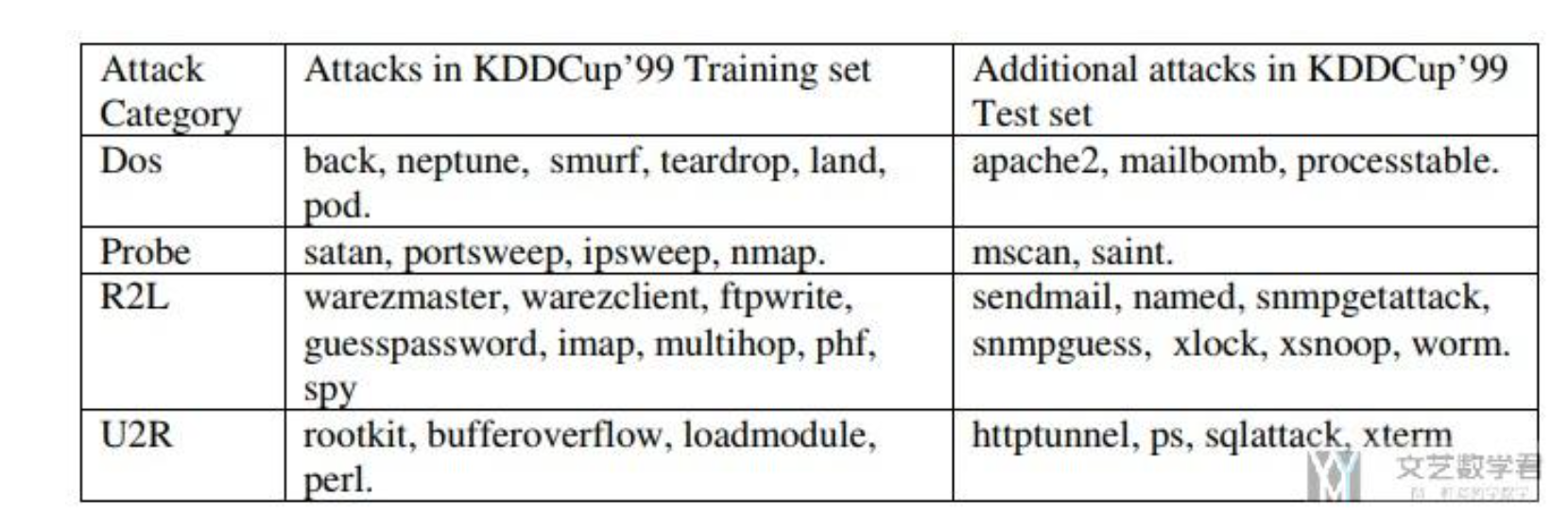
可以通过这个程序转换,比如[‘back’, ‘land’, ‘neptune’, ‘pod’, ‘smurf’, ‘teardrop’, ‘processtable’, ‘udpstorm’, ‘mailbomb’, ‘apache2’]都是Dos攻击类别。
# 结果标签转换为数字 dos_type = ['back', 'land', 'neptune', 'pod', 'smurf', 'teardrop', 'processtable', 'udpstorm', 'mailbomb', 'apache2'] probing_type = ['ipsweep', 'mscan', 'nmap', 'portsweep', 'saint', 'satan'] r2l_type = ['ftp_write', 'guess_passwd', 'imap', 'multihop', 'phf', 'warezmaster', 'warezclient', 'spy', 'sendmail', 'xlock', 'snmpguess', 'named', 'xsnoop', 'snmpgetattack', 'worm'] u2r_type = ['buffer_overflow', 'loadmodule', 'perl', 'rootkit', 'xterm', 'ps', 'httptunnel', 'sqlattack'] type2id = {'normal': 0} for i in dos_type: type2id[i] = 1 for i in r2l_type: type2id[i] = 2 for i in u2r_type: type2id[i] = 3 for i in probing_type: type2id[i] = 4

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数据处理&&训练技巧
数据预处理
讨论原始网络数据面临的挑战:高维度、类别特征和连续特征。
使用的技术:
对类别数据(协议类型、服务和标志)进行独热编码。
标准化连续特征以处理不同的尺度。
如何处理缺失数据(如果有),通过插值或删除。
使用StandardScaler和pickle保存缩放参数以保持一致的预处理。
处理不平衡数据
讨论入侵检测数据集中的不平衡问题。
介绍ImbalancedDatasetSampler的使用及其如何帮助实现平衡的小批量。
使用此类采样器对深度学习模型训练的好处。
模型架构
权重初始化技术,如Xavier和Kaiming初始化。
使用Dropout和Batch Normalization防止过拟合。
训练技巧
使用CosineAnnealingLR进行学习率调度,以适应性地调整学习率。
选择Adam优化器而非传统的SGD的原因。
损失函数的选择及其对模型训练的影响。
实验设置
数据加载器和批处理过程的描述。
利用GPU进行高效模型训练。
在训练过程中评估模型准确性和损失的过程。
建神经网络,输入41个特征,输出是那种类别的攻击
神经网络模型1,这是个全连接神经网络,训练完后效果不错:
class FullyConnectedNet(nn.Module): def __init__(self, input_size=122, num_classes=5): super(FullyConnectedNet, self).__init__() self.fc1 = nn.Linear(input_size, 512) # 第一层全连接层 self.fc2 = nn.Linear(512, 1024) # 第二层全连接层 self.fc3 = nn.Linear(1024, 512) # 第三层全连接层 self.fc3_1 = nn.Linear(512, 128) # 第三层全连接层 # self.fc3_2 = nn.Linear(512, 128) # 第三层全连接层 self.fc4 = nn.Linear(128, num_classes) # 输出层 self.relu = nn.ReLU() self.dropout = nn.Dropout(0.2) def forward(self, x): x = self.relu(self.fc1(x)) # x = self.dropout(x) x = self.relu(self.fc2(x)) # x = self.dropout(x) x = self.relu(self.fc3(x)) # x = self.dropout(x) x = self.relu(self.fc3_1(x)) # x = self.dropout(x) # x = self.relu(self.fc3_2(x)) x = self.fc4(x) return x # 初始化权重 def init_weights(self): for m in self.modules(): if type(m) == nn.Linear: init.xavier_normal_(m.weight) init.constant_(m.bias, 0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
为了写论文,当然可以造一些别的网络,效果也差不多,看你想怎么写就怎么写,比如下面这个模型:
class BGRUNet2(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(BGRUNet2, self).__init__() self.hidden_size = hidden_size self.gru = nn.GRU(input_size, hidden_size, batch_first=True, bidirectional=True) self.fc1 = nn.Linear(hidden_size * 2, 512) # Multiply hidden size by 2 for bidirectional self.fc2 = nn.Linear(512, 64) self.fc3 = nn.Linear(64, output_size) self.dropout = nn.Dropout(0.2) # Initialize GRU weights for name, param in self.gru.named_parameters(): if 'weight_ih' in name: init.xavier_uniform_(param.data) elif 'weight_hh' in name: init.orthogonal_(param.data) elif 'bias' in name: param.data.fill_(0) # Initialize fully connected layer weights init.xavier_uniform_(self.fc1.weight) init.xavier_uniform_(self.fc2.weight) init.xavier_uniform_(self.fc3.weight) # Initialize fully connected layer biases init.zeros_(self.fc1.bias) init.zeros_(self.fc2.bias) init.zeros_(self.fc3.bias) def forward(self, x): # Initialize hidden state for bidirectional GRU h0 = torch.zeros(2, x.size(0), self.hidden_size).to(x.device) # 2 for bidirectional # Forward pass through GRU out, _ = self.gru(x, h0) # Concatenate the hidden states from both directions out = torch.cat((out[:, -1, :self.hidden_size], out[:, 0, self.hidden_size:]), dim=1) out = self.dropout(out) out = F.relu(self.fc1(out)) out = self.dropout(out) out = F.relu(self.fc2(out)) out = self.dropout(out) return self.fc3(out)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
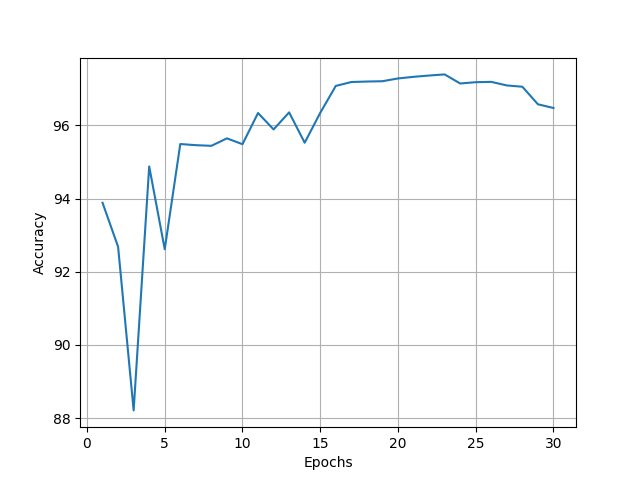
模型训练
训练30轮,准确度最高97.39%:
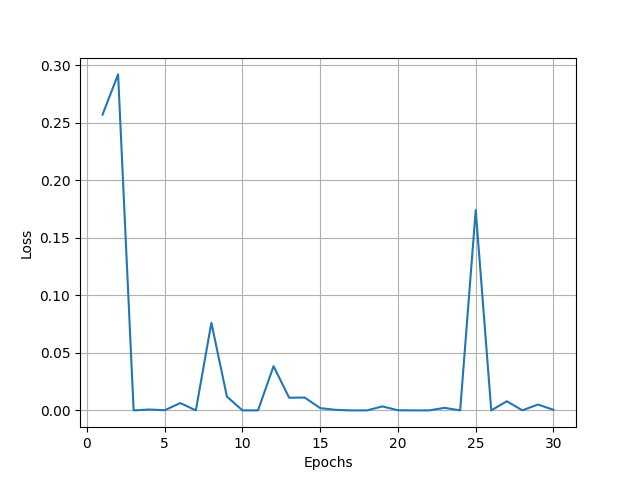
随着训练轮数的变化,损失的变化:
模型推理
加载模型后,构建输入数据,模型推导得出结果:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = BGRUNet2(input_size=122, hidden_size=256, output_size=5)
model.load_state_dict(torch.load('model_accuracy_max.pth', map_location=device))
model.to(device)
model.eval()
time1 = time.time()
with torch.no_grad():
X = X.to(device)
outputs = model(X)
# softmax
outputs = F.softmax(outputs, dim=1)
_, predicted = torch.max(outputs.data, 1)
time2 = time.time()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
写gradio前端界面,用户自己输入41个特征,后端用模型推理计算后显示出是否是dos攻击
安装环境(仅仅第一次需要安装):
pip install matplotlib torch torchvision gradio pandas scipy torchsampler scikit-learn==1.3.1
- 1
运行代码 python app.py 后访问:http://127.0.0.1:7861/
可以看到:
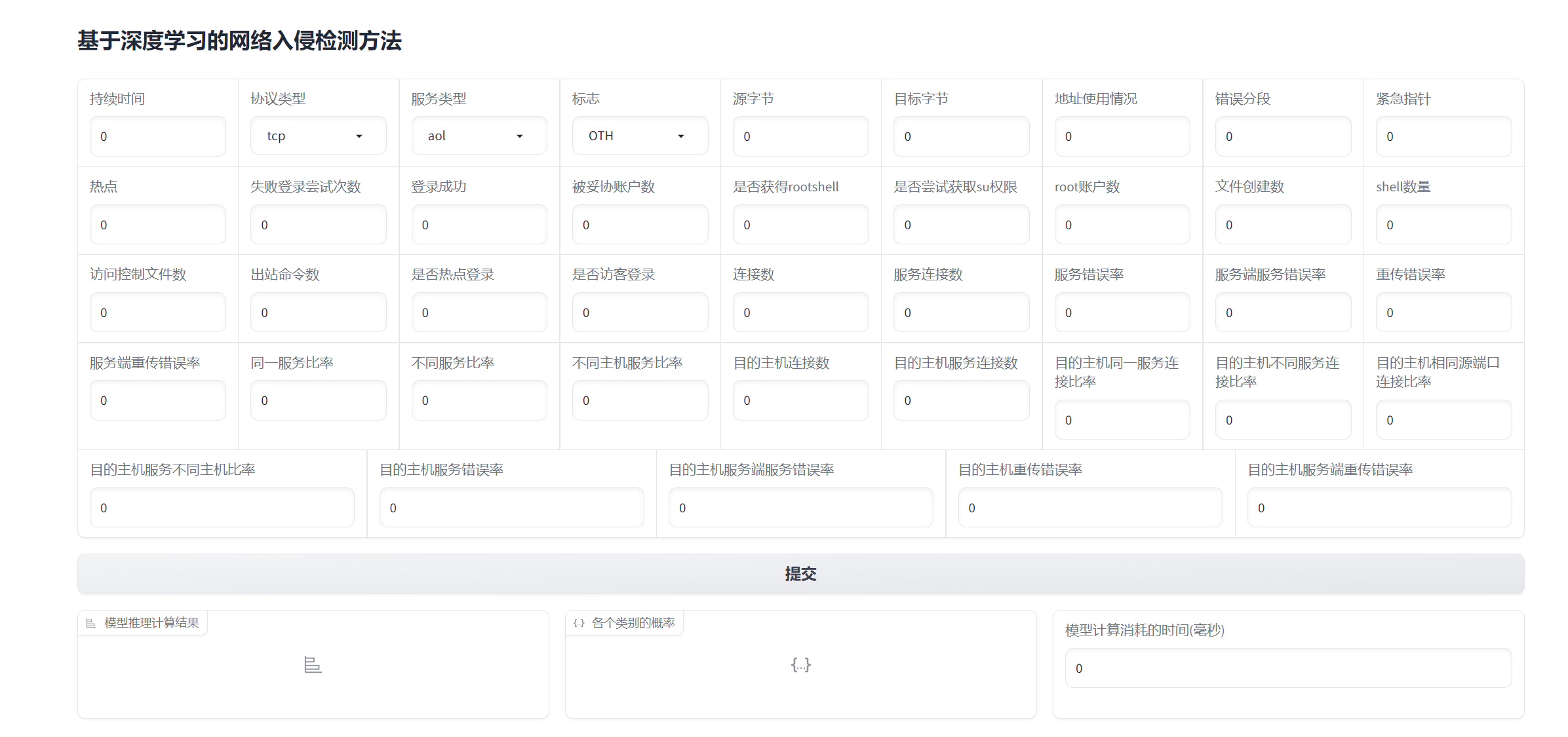
填写特征太多,有点懒得填,可以拉到最底下,有例子,可以点一下例子数据:
然后点一下提交,模型推理后给出结果,可以看到,模型认为这次连接数据表明了这是Doc入侵攻击,概率是1,模型推理消耗了0.01毫秒。

使用方法:
执行python train.py。即可开启训练。
执行python app.py。即可开启gradio前端界面。
获取代码和模型
go:
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2
- 1

