
热门标签
热门文章
- 1pycharm创建django项目及开发初准备
- 2neo4j 的卸载_neo4j-community-5.15.0 卸载
- 3李宏毅 自然语言处理(Voice Conversion) 笔记_李宏毅 voice conversion
- 4web SSTI 刷题记录_[hnctf 2022 week3]ssssti
- 5QUIC协议连接原理和特性
- 6[Go]三、最简单的RestFul API服务器_go 简单的api
- 7Linux系统管理常用命令
- 8Neo4j(CQL)学习记录-02(Cypher Query Language)
- 9使用 Verdaccio 构建自己的私有 npm 仓库_yarn verdaccio
- 10用shell 脚本写守护进程_shell进程守护脚本
当前位置: article > 正文
【NLP】特征工程_word2Vec_02_实践_文本向量化_中文word2vec 训练有哪些python工具包
作者:不正经 | 2024-05-22 07:36:39
赞
踩
中文word2vec 训练有哪些python工具包

前言
word2vec目前可以应用很多方面,如文本分类,文本聚类,相似度计算,推荐,NLP相关应用等等。
那么今天就先玩下其文本向量化功能
python版已实现word2vec的库有: gensim
数据集
要训练词向量就必须要有大量的语料库
中文语料如下:
- 腾讯AI Lab2018年分享的开源800万中文词的NLP数据集文章https://mp.weixin.qq.com/s?__biz=MzIzNjc1NzUzMw==&mid=2247506252&idx=4&sn=1f883532975737c9df02212fc2ae1ca5&chksm=e8d06e3edfa7e728ee0f1ae592e03cee5c818a5b731a0f0560672323894a2304758698b52f37&mpshare=1&scene=1&srcid=1019nHpV0cUEBOk3Z25cuPgA#rd
下载链接为https://ai.tencent.com/ailab/nlp/embedding.html- 中文自然语言处理开放平台
由中国科学院计算技术研究所·数字化室&软件室创立一个研究自然语言处理的一个平台,里面包含有大量的训练测试语料。
语料库: http://www.nlp.org.cn/docs/doclist.php?cat_id=9&type=15
文本语料库: http://www.nlp.org.cn/docs/doclist.php?cat_id=16&type=15- sogou文本分类语料库
文本分类语料库来源于Sohu新闻网站保存的大量经过编辑手工整理与分类的新闻语料与对应的分类信息。其分类体系包括几十个分类节点,网页规模约为十万篇文档。
地址: http://www.sogou.com/labs/dl/c.html- wei —基百科中文网页下载资源: https://dumps.wikimedia.org/zhwiki/lastest/zhwiki-lastest-pages-articles.xml.bz2
由于上述语料库都比较大,维基数据大小为1.5G,大小比较适合作为开发测试
数据清洗
W基提供的语料是xml格式且还是繁文的,故需做相应的数据处理
1.数据预处理
# -*- coding: utf-8 -*-
"""
FileName : data_pre_process.py
Description : 中文语料预处理.
@author : PuShkin
Time : 20181230
"""
from gensim.corpora import WikiCorpus
import jieba
from langconv import *
def my_function():
space = ' '
i = 0
l = []
zhwiki_name = './data/zhwiki-latest-pages-articles.xml.bz2'
f = open('./data/reduce_zhiwiki.txt', 'w',encoding='utf-8')
# xml文件中读出训练语料
wiki = WikiCorpus(zhwiki_name, lemmatize=False, dictionary={})
for text in wiki.get_texts():
for temp_sentence in text:
# 繁体字转换为简体
temp_sentence = Converter('zh-hans').convert(temp_sentence)
# 分词
seg_list = list(jieba.cut(temp_sentence))
for temp_term in seg_list:
l.append(temp_term)
f.write(space.join(l) + '\n')
l = []
i = i + 1
if (i %200 == 0):
print('Saved ' + str(i) + ' articles')
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
向量化训练(模型)
使用gensim库训练词向量,相关参数请见注释,
# -*- coding: utf-8 -*-
"""
FileName : train.py
Description : 向量化训练.
@author : PuShkin
Time : 20181230
"""
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
def my_function():
wiki_news = open('./data/reduce_zhiwiki.txt', 'r',encoding='utf-8')
# sg=0表示使用CBOW模型训练词向量; sg=1 表示使用Skip-gram训练词向量, size表示词向量的维度;
# windows表示当前词和预测词可能的最大距离,windows越大所需要枚举的预测词越多,计算时间越长
# min_count表示最小出现的次数,如果一个词语出现的次数小于min_count,那么直接忽略
# workers 表示使用的线程数
model = Word2Vec(LineSentence(wiki_news), sg=0,size=192, window=5, min_count=5, workers=9)
model.save('zhiwiki_news.word2vec')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
模型应用
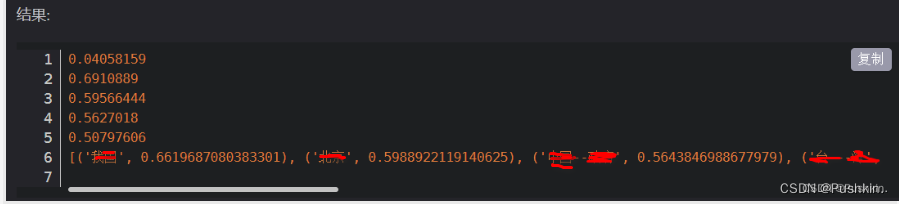
利用词向量计算词语的相似度
PS: 由于词汇敏感 故我直接图片化吧 哎~~~~

结果:
- 1
- 2
- 3
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/607182
推荐阅读
相关标签

