
- 1快速上手的AI工具 - 文心编码辅助
- 2java.lang.ClassCastException: class java.lang.Integer cannot be cast to class java.lang.String
- 3第三代AlphaFold发布:生物大分子复合物结构预测问题将被解决?_alphafold3
- 4html网页制作——奶茶网页设计与实现(HTML+CSS+JavaScript)_奶茶店网站具体设计
- 5Docker部署GitLab代码托管工具保姆级教程(小白都能学会)_docker部署代码管理工具
- 6mysql honeypot_Mysql使用语法总结
- 7决策树DTC数据分析及鸢尾数据集分析_决策树分析源数据
- 8python发送邮件的时候出现 error (535, b‘5.7.3 Authentication unsuccessful‘) 解决方法_535, b'5.7.139 authentication unsuccessful, smtpcl
- 9【Python】PySpark 数据处理 ② ( 安装 PySpark | PySpark 数据处理步骤 | 构建 PySpark 执行环境入口对象 )_pyspark安装
- 10C语言 数据结构 链表 基本操作代码_数据结构链表c语言代码
Python处理Excel,学会这十四个方法,工作量减少大半
赞
踩
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=[“较差”,“中等”,“较好”,“非常好”]
#使用cut分组
#sale_area[“分组”]=pd.cut(sale_area[“利润”],bins,labels=groups)
7、对比两列差异
因为这表每列数据维度都不一样,比较起来没啥意义,所以我先做了个订单明细号的差异再进行比较。
需求:比较订单明细号与订单明细号2的差异并显示出来。
sale[“订单明细号2”]=sale[“订单明细号”]
#在订单明细号2里前10个都+1.
sale[“订单明细号2”][1:10]=sale[“订单明细号2”][1:10]+1
#差异输出
result=sale.loc[sale[“订单明细号”].isin(sale[“订单明细号2”])==False]
8、异常值替换
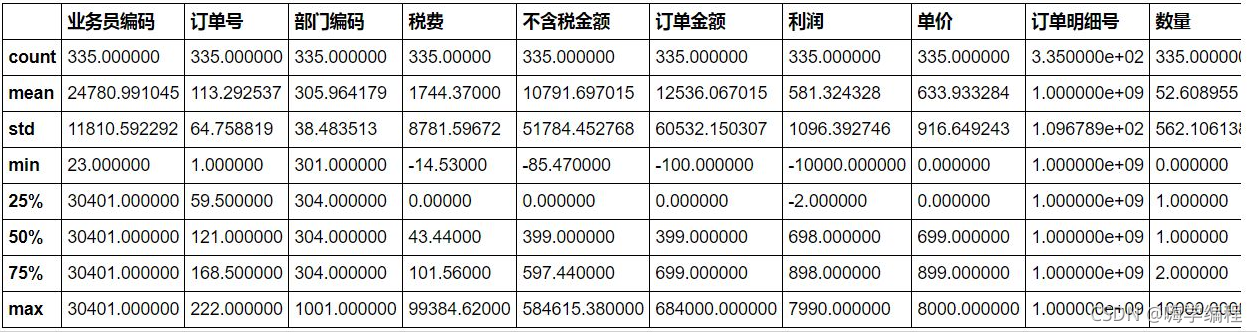
首先用describe()函数简单查看一下数据有无异常值。
#可看到销项税有负数,一般不会有这种情况,视它为异常值。
sale.describe()
 需求
需求
用0代替异常值。
sale[“订单金额”]=sale[“订单金额”].replace(min(sale[“订单金额”]),0)
9、缺失值处理
先查看销售数据哪几列有缺失值
#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值
sale.info()

需求
用0填充缺失值或则删除有客户编码缺失值的行
实际上缺失值处理的办法是很复杂的,这里只介绍简单的处理方法,若是数值变量,最常用平均数或中位数或众数处理,比较复杂的可以用随机森林模型根据其他维度去预测结果填充。
若是分类变量,根据业务逻辑去填充准确性比较高。
比如这里的需求填充客户名称缺失值:就可以根据存货分类出现频率最大的存货所对应的客户名称去填充。
这里我们用简单的处理办法:用0填充缺失值或则删除有客户编码缺失值的行。
#用0填充缺失值
sale[“客户名称”]=sale[“客户名称”].fillna(0)
#删除有客户编码缺失值的行
sale.dropna(subset=[“客户编码”])
10、数据分列
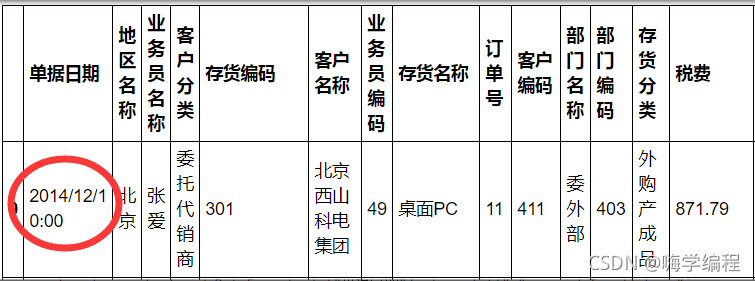
需求
将日期与时间分列
sale=pd.merge(sale,pd.DataFrame(sale[“单据日期”].str.split(" ",expand=True)),how=“inner”,left_index=True,right_index=True)
11、 模糊筛选数据
需求
筛选存货名称含有"三星"或则含有"索尼"的信息
sale.loc[sale[“存货名称”].str.contains(“三星|索尼”)]
12、删除数据间的空格
需求
删除存货名称两边的空格
sale[“存货名称”].map(lambda s
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

