- 1计算机网络中23是什么端口号,什么是网络端口,端口有哪些分类-电脑自学网
- 2【话题】程序员应该有什么职业素养
- 3java的JVM学习总结第一章——JVM与java的体系结构
- 4【文献阅读】受山体阴影影响的冰湖制图方法研究(Li JunLi等人,2018.09,IJRS)_阴影损失文献
- 5【数据结构】线性表之《带头双向循环链表》超详细实现
- 6LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战_dashscope中的llm的api
- 7ue4 UMG添加到场景_unreal umg放到世界空间
- 8译文:dBA和dBC的不同_dba和dbc的区别
- 9网站高性能架构设计——web前端与池化_前端架构设计
- 10spring整合openAI大模型之Spring AI_spring ai maven
【python实现网络爬虫(17)】使用正则表达式爬取百度以任意关键词搜索返回结果的数据_python 检索baidu
赞
踩
正则表达式爬取百度搜索结果
1. 爬虫架构
为了减少不必要的步骤,直接加载一下爬虫的基础架构,如下。注意,一定要填写自己的headers的内容
import re import requests import time headers = { 'Cookie': '_ga=GA1.2.1075258978.1586877585; _gid=GA1.2.304073749.1587691875; ', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' } #这里的cookie和header加上自己浏览器的即可 def get_data(url): html = requests.get(url,headers) if html.status_code == 200: print('正在爬取中...') time.sleep(2) parse_html(html.text) else: print('Error',url) def parse_html(text): pass if __name__ == '__main__': pass

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2. 创建分页url
2.1 网页url规律查找
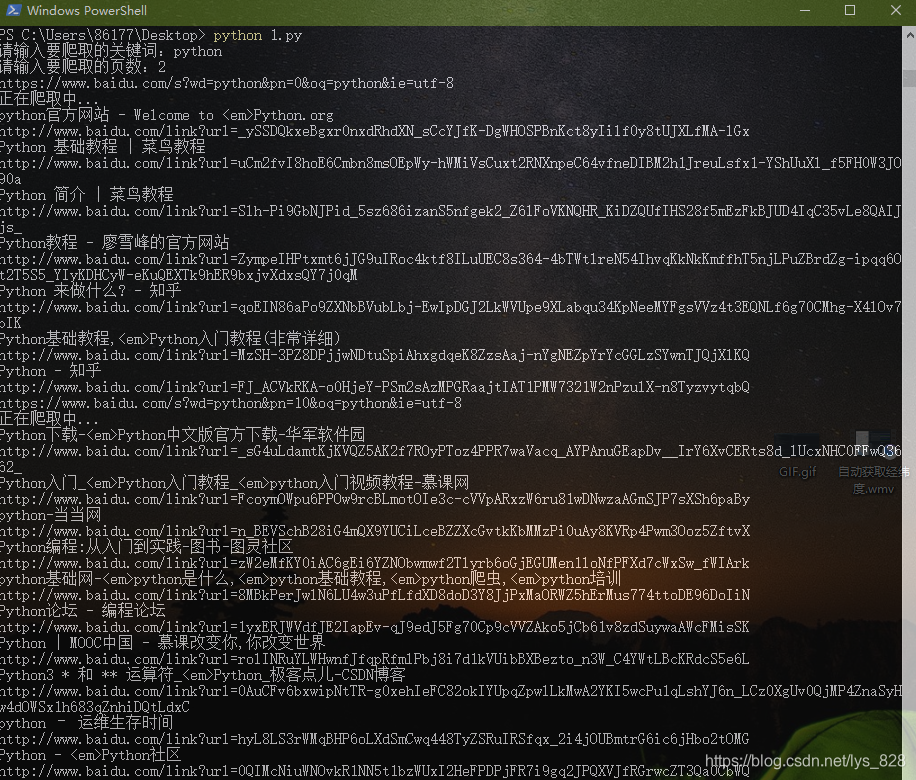
这里假设使用“python”作为关键词进行搜索,然后习惯的是查看第2、3、4页,这样就可以查找url之间的规律了,后面的参数会有很多,只需要选取有效的部分即可,如下
u2 = https://www.baidu.com/s?wd=python&pn=10&oq=python&ie=utf-8
u3 = https://www.baidu.com/s?wd=python&pn=20&oq=python&ie=utf-8
u4 = https://www.baidu.com/s?wd=python&pn=30&oq=python&ie=utf-8
......
- 1
- 2
- 3
- 4
2.2 创建接口输出url测试
一次写的代码要有可扩展性,而不是只针对于具体的内容,最好是保留一个接口,这样可以使得爬虫的程序代码高效,因此需要进行input的输入,然后对于关键词的解析,存在着中文字符,就需要将其转化为可以识别的内容,这里导入urllib库中的parse模块进行关键词的解析,如下。
关于第一条语句的使用,该行代码的意义是什么?功能就是将执行区和功能函数区进行分割,创建接口
if __name__ == "__main__"
- 1
一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行。因此该段代码的作用就是控制这两种情况执行代码的过程,在该行代码下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的
也就是该行代码前面就是导入的库和相关定义的函数,该行代码下面就是我们进行的具体赋值和对应的操作
if __name__ == '__main__':
keyword = parse.quote(input('请输入要爬取的关键词:'))
num = eval(input('请输入要爬取的页数:'))
for i in range(0,num):
url = f'https://www.baidu.com/s?wd={keyword}&pn={i*10}&oq={keyword}&ie=utf-8'
print(url)
get_data(url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
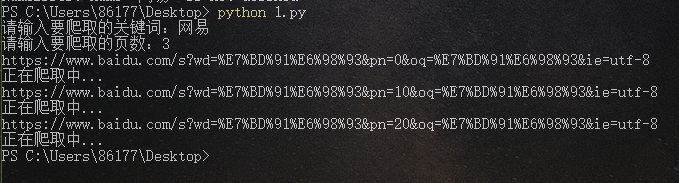
→ 输出的结果为:(因为保留的接口,所以可以输入任何关键字,比如以“网易”为例,搜索前3页)
3 正则表达式匹配
正则表达式在爬虫中使用有两种使用方式,一种是不需要配合bs4直接在源代码中进行数据的匹配(比如爬取B站弹幕时候获取cid信息,爬取酷狗音乐中获取榜单的hash值);还有一种结合bs4进行标签解析结果输出后进行复杂字段信息的提取(豆瓣读书详细信息介绍,链家二手房的详细信息介绍)
3.1 直接匹配源代码
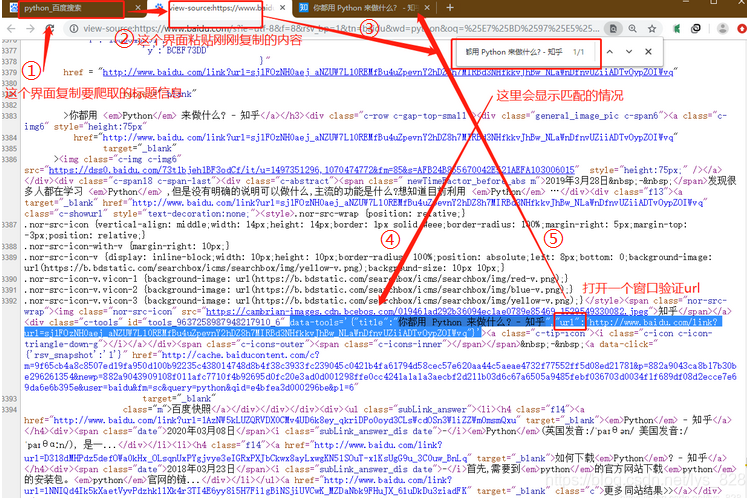
这时候就不是进入检查界面了,而是直接在搜索结果的界面鼠标右键,然后在弹出的选项中选择“查看网页源代码”,把要爬取的标题在弹出“源代码”中进行数据匹配,查看保存需求数据的格式,比如就是以刚刚的搜索python为例,选择标题和其对应的url为获取对象
流程步骤解析:【复制要爬取的内容】→ 【目标页面右键进入源代码页面】→ 【ctrl+f调出查找窗口】→ 【在小窗中粘贴复制的内容】→ 【找到目标数据的格式规律】→ 【使用正则替换掉目标数据】→ 编写代码
流程图解,如下,注意箭头及对应的标号。
代码如下:只需要将需要匹配的数据进行正则表达式的替换即可
def parse_html(text):
# print(text)
infos = re.findall(r'{"title":"(.*?)","url":"(.*?)"}',text)
print(infos)
- 1
- 2
- 3
- 4
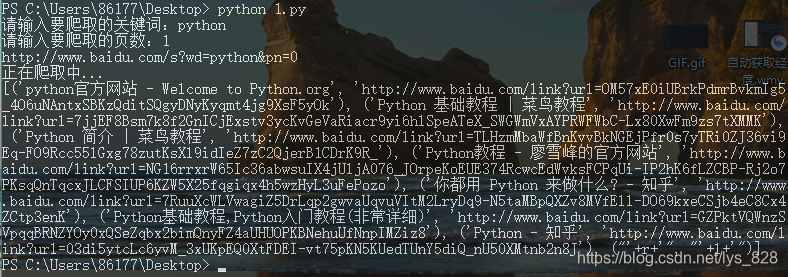
→ 输出的结果为:(如果需要分别提取title和url的话,就是列表里面筛选数据,进行遍历循环后索引即可)
3.2 配合网页解析进行结果匹配
这个主要是用在复杂字段,解决疑难问题,这次爬取的内容不适合使用这种方式,原因可以在匹配的过程中感受到,如下
1) 网页解析
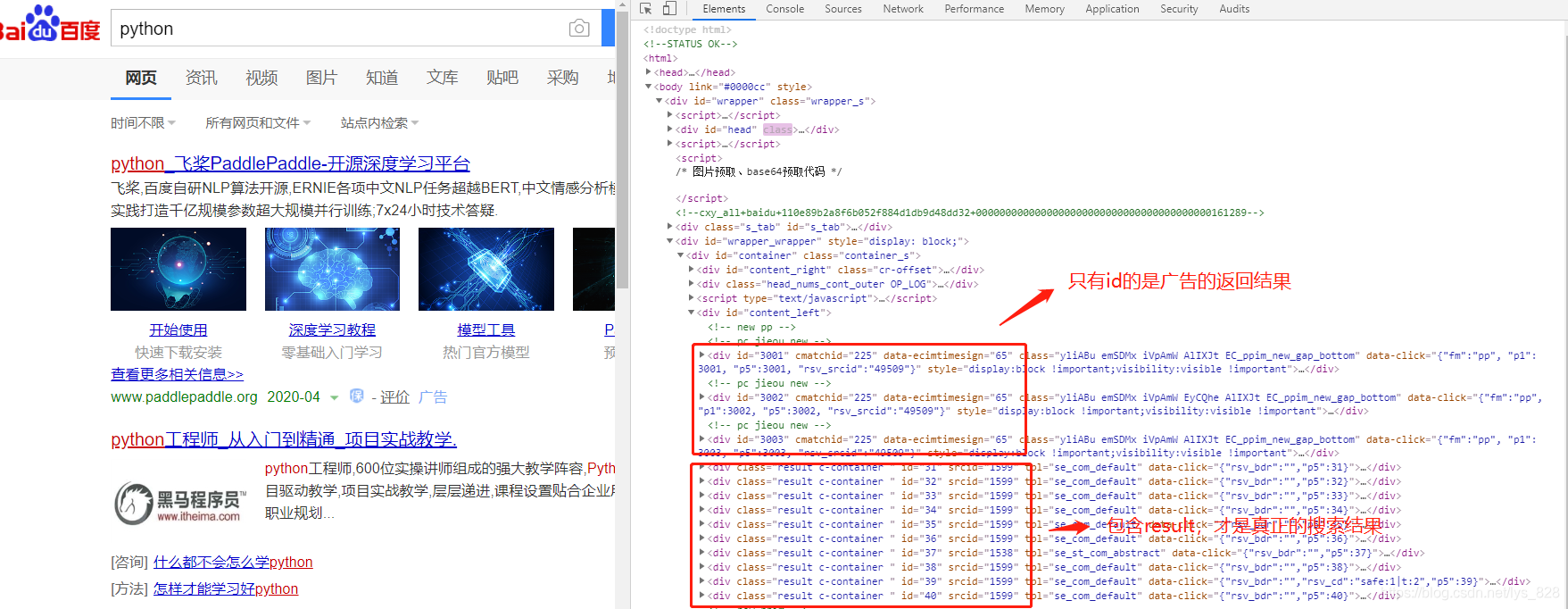
这里还是以“python”作为关键词进行搜索结果界面的解析。其中可以发现百度的返回结果中前几个往往都是广告内容,后面的才是我们要搜索而返回的结果
2) 标题解析
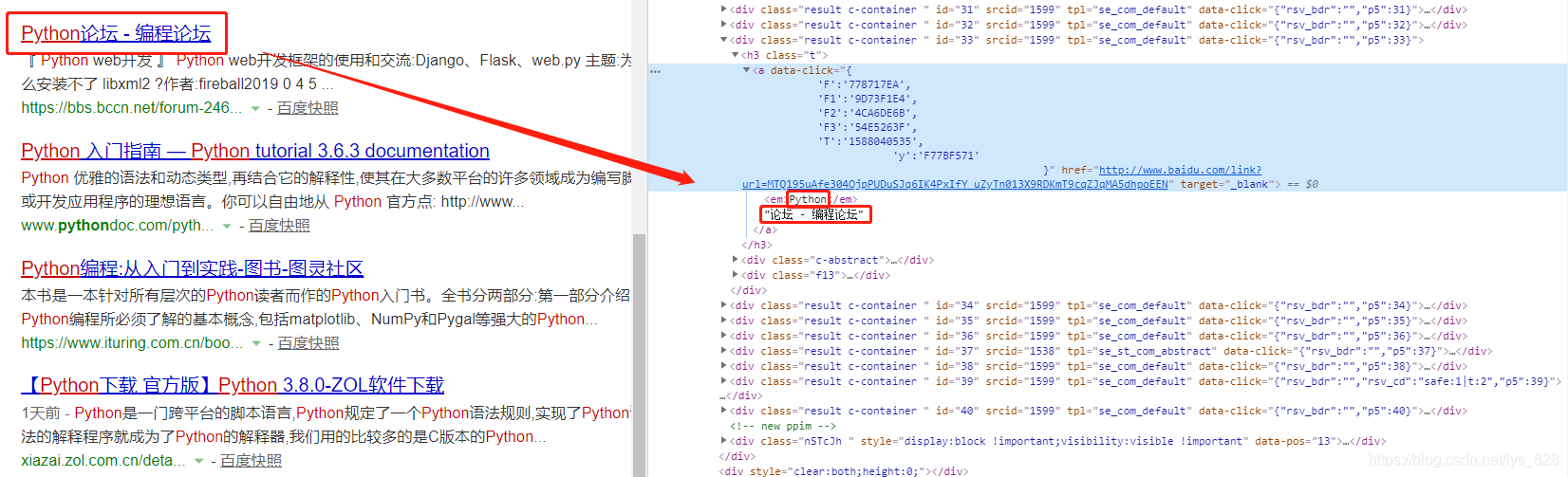
这里只针对需要的数据进行标题信息的获取(排除广告),可以发现标题的内容被放置在了em的便签里面,而且是被分割了
3) 搜索结果的url解析
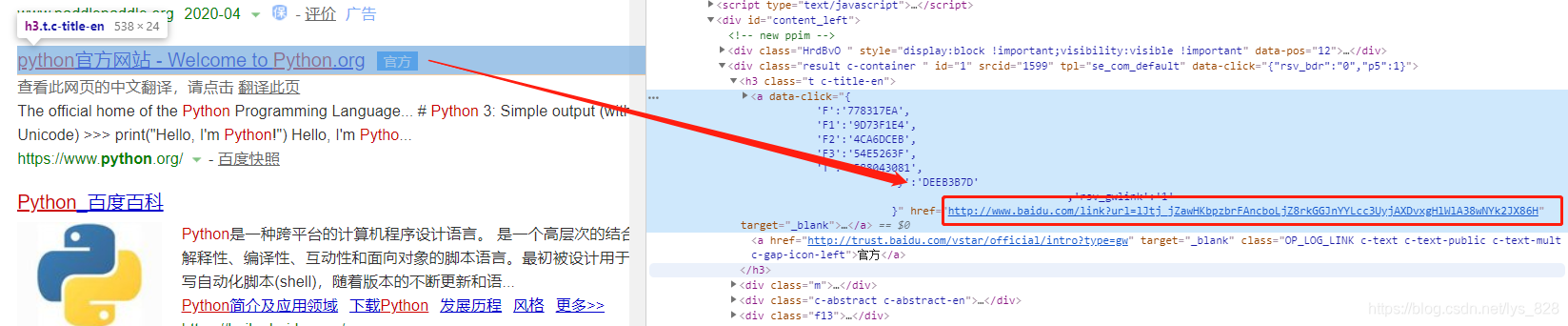
要获取搜索返回结果的url的信息,可以发现这个内容就是在标题信息的上面一行中
代码如下:(首先是要引入bs4解析页面,然后找到对应信息所在的标签,然后使用正则表达式匹配标签的信息)
def parse_html(text):
soup = BeautifulSoup(text,'lxml')
infos = soup.find_all('div',class_='result c-container')
for info in infos:
info = info.find('h3').a
print(info)
- 1
- 2
- 3
- 4
- 5
- 6
→ 输出的结果为:(只截取部分,这里其实可以直接.text就已经完成了标题的获取,使用a[‘href’]也可以直接获取url)
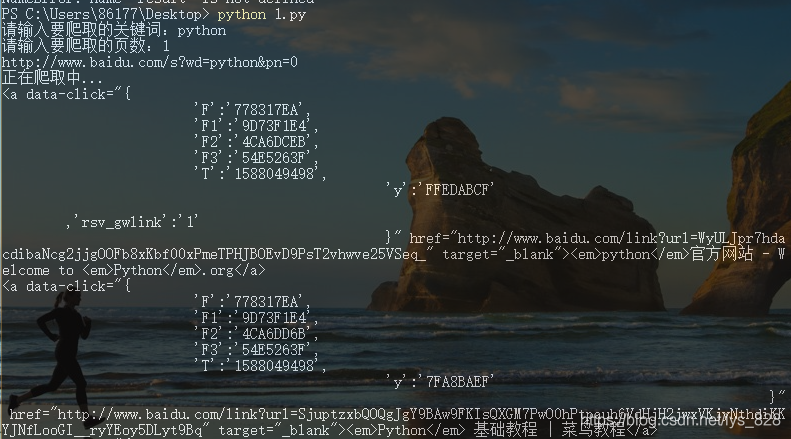
这里要配合着bs4使用,可以直接匹配a标签中的内容进行数据提取
def parse_html(text):
soup = BeautifulSoup(text,'lxml')
infos = soup.find_all('div',class_='result c-container')
for info in infos:
info = info.find('h3').a
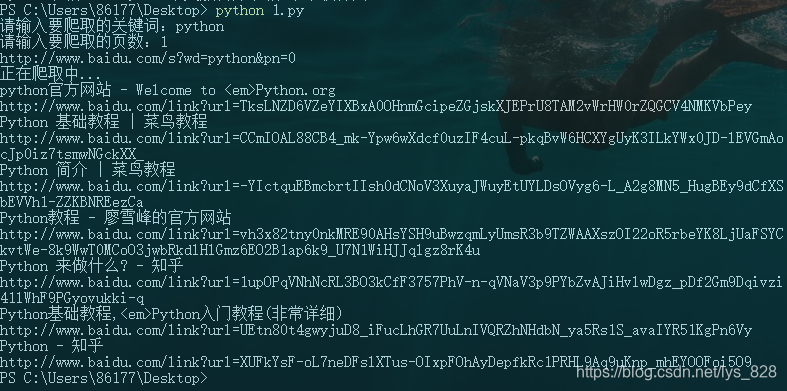
title = re.search(r'<em>(.*)</a>',str(info)).group(1).replace('</em>','')
print(title)
url = re.search(r'href="(.*?)"',str(info)).group(1)
print(url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
→ 输出的结果为:(可以实现数据的获取)
4. 小结
通过上面的示例可以发现,直接通过正则表达式匹配源代码是最为简单的方式,其中的问题 难点在于找到存放数据的格式,然后把要爬取的数据换成正则表达式,接着就是不建议完全使用正则表达式去匹配解析后的标签信息,因为这一步是属于重复的工作(这里只是练习使用正则),在实际的爬虫过程中,可以使用标签解析的.text方法获得文本数据或者a[href]获取url,尽量直接一步到位就可,不需要再这一步使用正则表达式否则就使得问题复杂化了。
注意:正则表达式与bs4配合使用多发生在标签解析已经获得文本之后进行文本的提纯,比如提到的豆瓣读书信息详情的爬取等(有兴趣可以试一下,也可以参考一下博客【python爬虫专项(14)】正则表达式在爬虫中的应用)
个人经验是(简洁性):re+源代码 > bs4 > bs4+re
个人经验是(常用性):bs4 > bs4 + re > re + 源代码
5. 全部代码
5.1 re + 源代码
import re import requests import time from bs4 import BeautifulSoup from urllib import parse headers = { 'Cookie': 'BIDUPSID=82508FD9E8C7F366210EB75A638DF308; PSTM=1567074841; ', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' } #这里的refer,cookie和header加上自己浏览器的即可 def get_data(url): html = requests.get(url,headers=headers) if html.status_code == 200: print('正在爬取中...') time.sleep(2) parse_html(html.text) else: print('Error',url) def parse_html(text): infos = re.findall(r'{"title":"(.*?)","url":"(.*?)"}',text) print(infos) if __name__ == '__main__': keyword = parse.quote(input('请输入要爬取的关键词:')) num = eval(input('请输入要爬取的页数:')) for i in range(0,num): url = f'https://www.baidu.com/s?wd={keyword}&pn={i*10}&oq={keyword}&ie=utf-8' print(url) get_data(url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
5.2 bs4 + re
import re import requests import time from bs4 import BeautifulSoup from urllib import parse headers = { 'Cookie': 'BIDUPSID=82508FD9E8C7F366210EB75A638DF308; PSTM=1567074841; ', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' } #这里的refer,cookie和header加上自己浏览器的即可 def get_data(url): html = requests.get(url,headers=headers) if html.status_code == 200: print('正在爬取中...') time.sleep(2) parse_html(html.text) else: print('Error',url) def parse_html(text): # print(text) # infos = re.findall(r'{"title":"(.*?)","url":"(.*?)"}',text) # print(infos) soup = BeautifulSoup(text,'lxml') infos = soup.find_all('div',class_='result c-container') for info in infos: info = info.find('h3').a title = re.search(r'<em>(.*)</a>',str(info)).group(1).replace('</em>','') print(title) url = re.search(r'href="(.*?)"',str(info)).group(1) print(url) if __name__ == '__main__': keyword = parse.quote(input('请输入要爬取的关键词:')) num = eval(input('请输入要爬取的页数:')) for i in range(0,num): url = f'https://www.baidu.com/s?wd={keyword}&pn={i*10}&oq={keyword}&ie=utf-8' print(url) get_data(url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
附上多页爬取数据测试的结果(这里爬取两页,对应两个正在爬取中…)