
- 1hadoop04--Kafka集群环境搭建_kafka和hadoop集成
- 2【node.js从入门到精通】编写接口,使用CROS解决跨域问题,jsonp的接口_nodejs jsonp
- 3探秘Vanna AI:一款智能代码助手与代码审查工具
- 4Go最新使用Golang Web3库进行区块链开发_go语言有web3库吗(1),华为架构师深入讲解Golang开发
- 5梯度下降算法的实现【python,算法,机器学习】
- 6【编程语言之Python】之plt画图尺寸、去白边_python画图不要坐标轴外白色框
- 7csv文件导入 navicat会少了很多记录_MySql导入和抽取大数量级文件数据
- 8Prometheus+Grafana新手友好教程:从零开始搭建轻松掌握强大的警报系统_grafana配合prometheus配置告警
- 9国内唯一!阿里云荣膺MongoDB “2024年度DBaaS认证合作伙伴奖”
- 10bootloader详解(转载)
预训练(pre-learning)、微调(fine-tuning)、迁移学习(transfer learning)_迁移学习 pretrain fune ttuing
赞
踩
什么是预训练?
预训练是一种深度学习模型训练的策略,通常在大规模的数据集上进行。预训练的目标是通过在一个相关但较大的任务上训练模型,使得模型学习到通用的特征表示。这样的预训练模型在其他具体任务上的表现通常更好,因为它已经学习到了普适的特征。
在深度学习中,预训练可以分为两种主要类型:无监督预训练和有监督预训练。
1)无监督预训练
在无监督预训练中,模型在没有标签的大规模数据上进行预训练。常见的无监督预训练方法包括自编码器、变分自编码器、对比预训练等。预训练后,模型的参数会被调整到一种更有用的表示形式,使得它能够从输入数据中提取有意义的特征。
2)有监督预训练
在有监督预训练中,模型在一个与最终任务相关的较大数据集上进行预训练。然后,可以使用这些预训练的权重作为最终任务(如分类、回归等)的初始参数。这种方法通常能够加速最终任务的训练过程,特别是在目标任务数据较少时。
预训练的好处在于,通过利用大规模数据进行训练,模型可以学习到更泛化的特征表示,从而在具体任务上表现更好。这对于数据较少的任务或者计算资源有限的情况下特别有用。预训练的模型也经常用于迁移学习,可以将预训练模型的部分或全部用于新的任务,以提高模型的性能。
预训练有什么作用?
加速训练过程:通过预训练,在大规模数据上学习到的通用特征表示可以作为初始化参数,加速模型在特定任务上的训练过程。这是因为预训练的参数已经接近最优,并且已经捕捉到了输入数据中的一些通用模式,这样在目标任务上的优化过程更容易收敛。
提高性能:预训练的模型通常在具体任务上表现更好。这是因为在预训练阶段,模型学习到了大量的数据中的通用特征,这些特征对于许多任务都是有用的。在目标任务中,预训练的模型能够更好地利用这些通用特征,从而提高性能。
解决数据不足问题:在许多实际任务中,数据往往是有限的,特别是深度学习模型需要大量的数据进行训练。通过预训练,可以利用大规模数据集进行通用特征的学习,然后将这些学到的特征应用于目标任务,从而克服数据不足的问题。
迁移学习:预训练的模型可以作为迁移学习的基础。将预训练模型的参数应用于新的相关任务,可以利用预训练模型在大规模数据上学习到的通用特征,从而在新任务上提高性能。这对于目标任务数据较少的情况下特别有用。
提高泛化能力:预训练有助于提高模型的泛化能力,即在未见过的数据上表现良好。通过在大规模数据上学习通用特征,模型更能够从输入数据中捕捉普遍的模式,而不是过度拟合训练集。
预训练和训练之间的本质区别
1)阶段和目标:
- 预训练阶段:在预训练阶段,模型使用大规模的数据集(通常是无标签数据集)进行训练,目标是学习通用的特征表示。这些通用特征可以应用于各种任务,因为它们反映了数据中的一般模式,而不是特定任务的信息。
- 训练阶段:在训练阶段,模型使用特定任务的有标签数据集进行训练,目标是根据该任务的特定目标函数调整模型参数,使其在该任务上表现良好。
2)数据集:
- 预训练阶段:预训练通常使用大规模无标签数据集,因为其目标是学习通用特征表示,无需特定标签信息。
- 训练阶段:训练使用特定任务的有标签数据集,因为需要根据任务的特定标签进行监督式学习,优化模型在该任务上的性能。
3)特征表示:
- 预训练阶段:预训练的目标是学习数据的通用特征表示,使得模型能够捕捉数据中的一般模式和结构。
- 训练阶段:在训练阶段,预训练的模型参数(通用特征表示)可以作为初始化参数,然后根据特定任务的目标函数进一步微调模型参数,使其更适应该任务。
4)任务目标:
- 预训练阶段:预训练的目标是促使模型学习更加泛化的特征,使其能够在各种任务上有良好的表现。
- 训练阶段:训练的目标是针对特定任务,最小化损失函数并优化模型参数,使其能够在该任务上达到最佳性能。
综上所述:预训练和训练是两个不同的阶段,它们的目标、数据集和特征表示等方面都有所区别。预训练提供了一种有效的方式来初始化模型参数,并使模型受益于大规模数据的通用特征表示,从而在特定任务上表现更好。
转自:https://blog.csdn.net/weixin_45325693/article/details/132084298
1、什么是预训练和微调
你需要搭建一个网络模型来完成一个特定的图像分类的任务。首先,你需要随机初始化参数,然后开始训练网络,不断调整参数,直到网络的损失越来越小。在训练的过程中,一开始初始化的参数会不断变化。当你觉得结果很满意的时候,你就可以将训练模型的参数保存下来,以便训练好的模型可以在下次执行类似任务时获得较好的结果。这个过程就是 pre-training。
之后,你又接收到一个类似的图像分类的任务。这时候,你可以直接使用之前保存下来的模型的参数来作为这一任务的初始化参数,然后在训练的过程中,依据结果不断进行一些修改。这时候,你使用的就是一个 pre-trained 模型,而过程就是 fine-tuning。
所以,预训练 就是指预先训练的一个模型或者指预先训练模型的过程;微调 就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
1.1、预训练模型
预训练模型就是已经用数据集训练好了的模型。
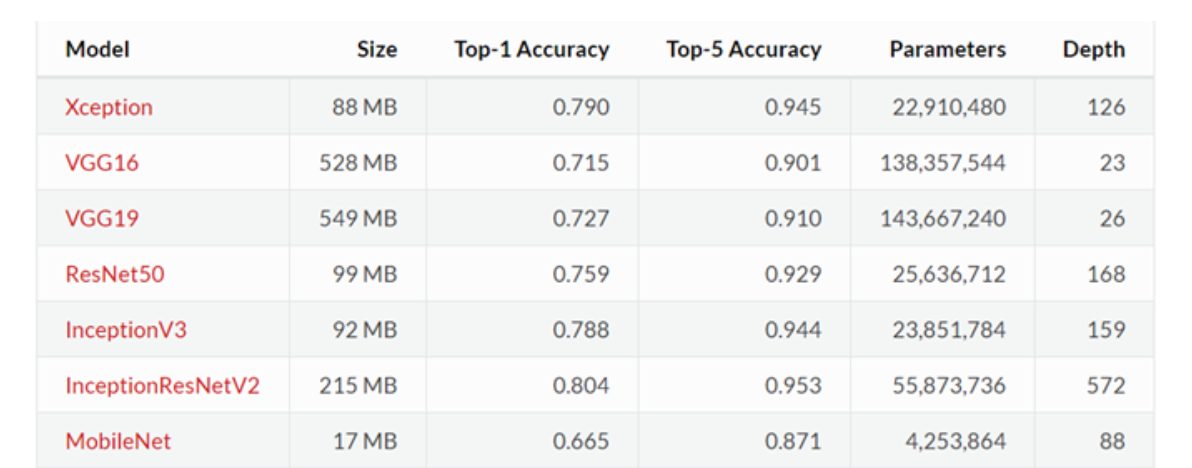
现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数;
正常情况下,我们常用的VGG16/19等网络已经是他人调试好的优秀网络,我们无需再修改其网络结构。
2、预训练和微调的作用
在 CNN 领域中,实际上,很少人自己从头训练一个 CNN 网络。主要原因是自己很小的概率会拥有足够大的数据集,基本是几百或者几千张,不像 ImageNet 有 120 万张图片这样的规模。拥有的数据集不够大,而又想使用很好的模型的话,很容易会造成过拟合。
所以,一般的操作都是在一个大型的数据集上(ImageNet)训练一个模型,然后使用该模型作为类似任务的初始化或者特征提取器。比如 VGG,ResNet 等模型都提供了自己的训练参数,以便人们可以拿来微调。这样既节省了时间和计算资源,又能很快的达到较好的效果。
3、模型微调



3.1、微调的四个步骤
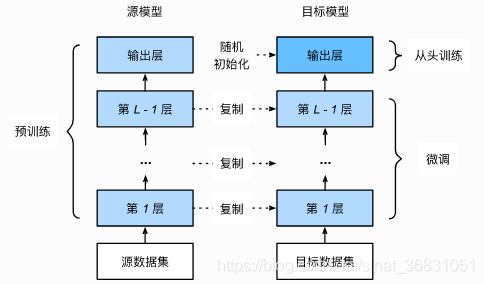
1)在源数据集(例如 ImageNet 数据集)上预训练一个神经网络模型,即源模型。
2)创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
3)为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
4)在目标数据集(例如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
3.2、为什么要微调
卷积神经网络的核心是:
1)浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。
2)深层卷积层提取抽象特征,比如整个脸型。
3)全连接层根据特征组合进行评分分类。
普通预训练模型的特点是:用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
如果不做微调的话:
1)从头开始训练,需要大量的数据,计算时间和计算资源。
2)存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
3.3、什么情况下使用微调
1)要使用的数据集和预训练模型的数据集相似。如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的。
2)自己搭建或者使用的CNN模型正确率太低。
3)数据集相似,但数据集数量太少。
4)计算资源太少。
不同数据集下使用微调
1)数据集1 - 数据量少,但数据相似度非常高 - 在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
2)数据集2 - 数据量少,数据相似度低 - 在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
3)数据集3 - 数据量大,数据相似度低 - 在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
4)数据集4 - 数据量大,数据相似度高 - 这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
3.4、微调注意事项
1)通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。例如,ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
2)使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
3)如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
4、迁移学习
迁移学习(Transfer Learning)是机器学习中的一个名词,也可以应用到深度学习领域,是指一种学习对另一种学习的影响,或习得的经验对完成其它活动的影响。迁移广泛存在于各种知识、技能与社会规范的学习中。
通常情况下,迁移学习发生在两个任务之间,这两个任务可以是相似的,也可以是略有不同。在迁移学习中,源任务(Source Task)是已经训练好的模型的来源,目标任务(Target Task)是我们希望在其中应用迁移学习的新任务。
迁移学习专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。比如说,用来辨识汽车的知识(或者是模型)也可以被用来提升识别卡车的能力。计算机领域的迁移学习和心理学常常提到的学习迁移在概念上有一定关系,但是两个领域在学术上的关系非常有限。
4.1、迁移学习的具象理解
从技术上来说,迁移学习只是一种学习的方式,一种基于以前学习的基础上继续学习的方式。但现在大家讲的最多的还是基于神经网络基础之上的迁移学习。这里我们以卷积神经网络(CNN)为例,做一个简单的介绍。
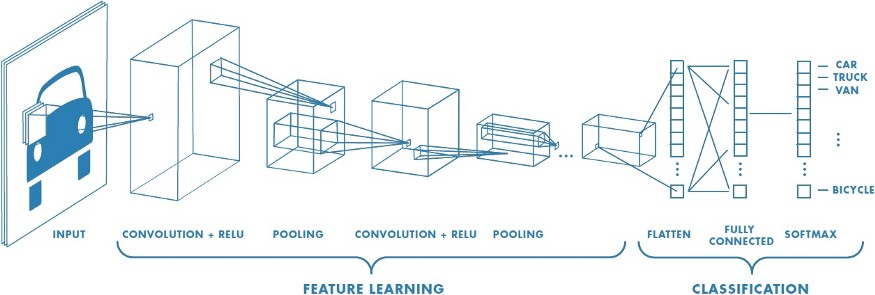
在CNN中,我们反复的将一张图片的局部区域卷积,减少面积,并提升通道数。
那么卷积神经网络的中间层里面到底有什么?Matthew D. Zeiler和Rob Fergus发表了一篇非常著名的论文,阐述了卷积神经网络到底看到了什么:

和对卷积层进行简单的成像不同,他们尝试把不同的内容输入到训练好的神经网络,并观察记录卷积核的激活值。并把造成相同卷积核较大激活的内容分组比较。上面的图片中每个九宫格为同一个卷积核对不同图片的聚类。
从上面图片中可以看到,较浅层的卷积层将较为几何抽象的内容归纳到了一起。例如第一层的卷积中,基本就是边缘检测。而在第二层的卷积中,聚类了相似的几何形状,尽管这些几何形状的内容相差甚远。
随着卷积层越来越深,所聚类的内容也越来越具体。例如在第五层里,几乎每个九宫格里都是相同类型的东西。当我们了解这些基础知识后,那么我们有些什么办法可以实现迁移学习?
其实有个最简单易行的方式已经摆在我们面前了:如果我们把卷积神经网络的前n层保留下来,剩下不想要的砍掉怎么样?就像我们可以不需要ct能识别狗,识别猫,但是轮廓的对我们还是很有帮助的。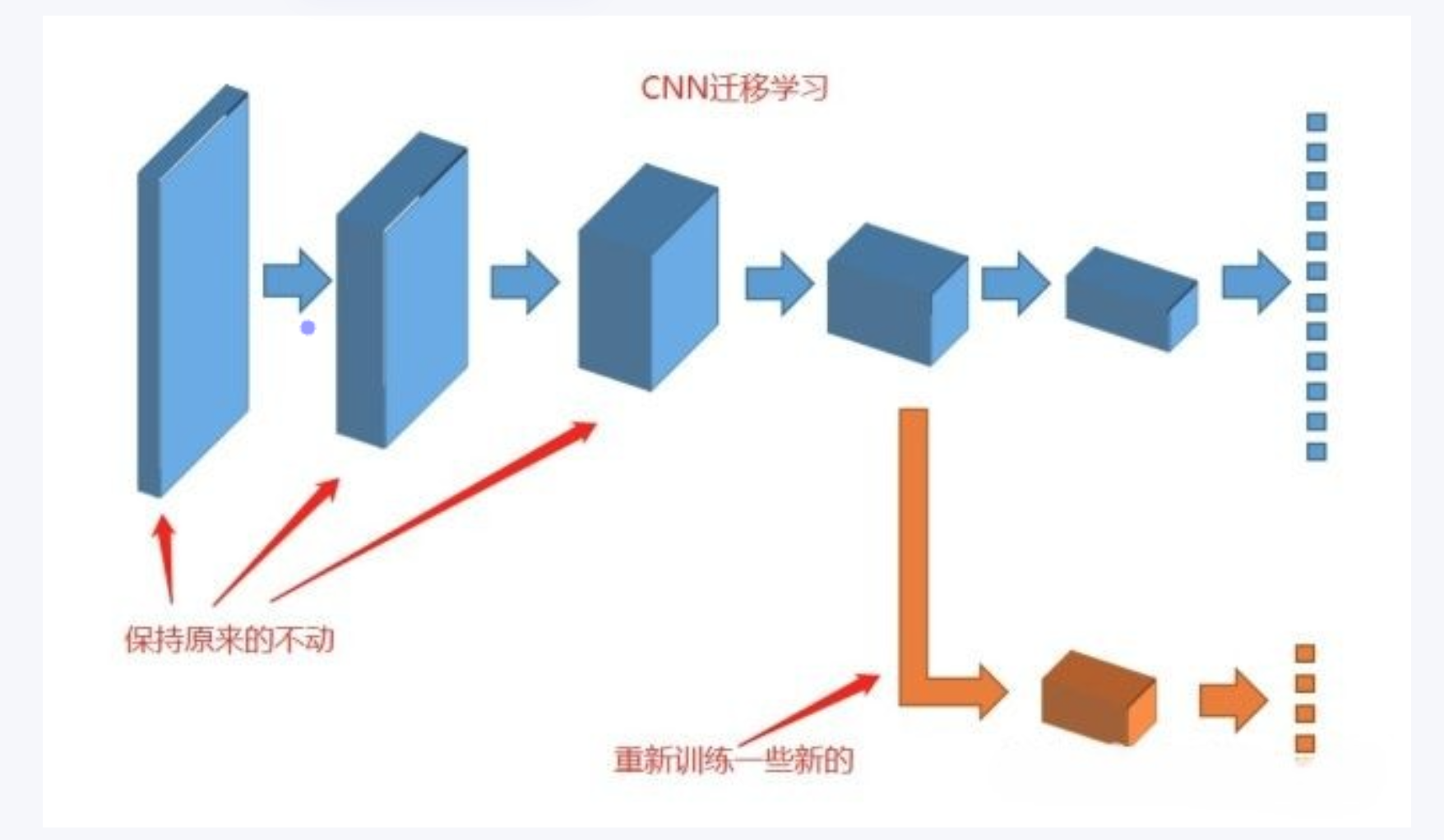
4.2、迁移学习的思想
迁移学习的主要思想是通过利用源任务上学到的特征表示、模型参数或知识,来辅助目标任务的训练过程。这种迁移可以帮助解决以下问题:
1)数据稀缺问题:当目标任务的数据量较少时,通过迁移学习可以利用源任务上丰富的数据信息来提高对目标任务的建模能力和泛化能力。
2)高维输入问题:当目标任务的输入数据具有高维特征时,迁移学习可以借助已经学到的特征表示,减少目标任务中的维度灾难问题,提高处理效率和性能。
3)任务相似性问题:当源任务和目标任务在特征空间或输出空间上存在一定的相似性时,迁移学习可以通过共享模型参数或知识的方式,加速目标任务的学习过程,提升性能。
4)领域适应问题:当源任务和目标任务的数据分布存在一定的差异时,迁移学习可以通过对抗训练、领域自适应等方法,实现在不同领域之间的知识传递和迁移。
总结来说,迁移学习是一种将已经学到的知识和模型从源任务迁移到目标任务的方法。它在机器学习和深度学习中都具有重要意义,可以提高模型的泛化能力、减少训练成本,并更好地应对数据稀缺、高维输入和任务相似性等问题。
4.3、如何使用迁移学习
你可以在自己的预测模型问题上使用迁移学习。以下是两个常用的方法:
- 开发模型的方法
- 预训练模型的方法
开发模型的方法
1)选择源任务。你必须选择一个具有丰富数据的相关的预测建模问题,原任务和目标任务的输入数据、输出数据以及从输入数据和输出数据之间的映射中学到的概念之间有某种关系,
2)开发源模型。然后,你必须为第一个任务开发一个精巧的模型。这个模型一定要比普通的模型更好,以保证一些特征学习可以被执行。
3)重用模型。然后,适用于源任务的模型可以被作为目标任务的学习起点。这可能将会涉及到全部或者部分使用第一个模型,这依赖于所用的建模技术。
4)调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。
预训练模型方法
1)选择源模型。一个预训练的源模型是从可用模型中挑选出来的。很多研究机构都发布了基于超大数据集的模型,这些都可以作为源模型的备选者。
2)重用模型。选择的预训练模型可以作为用于第二个任务的模型的学习起点。这可能涉及到全部或者部分使用与训练模型,取决于所用的模型训练技术。
3)调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。
第二种类型的迁移学习在深度学习领域比较常用。
4.4、什么时候使用迁移学习?
迁移学习是一种优化,是一种节省时间或者得到更好性能的捷径。
通常而言,在模型经过开发和测试之前,并不能明显地发现使用迁移学习带来的性能提升。
Lisa Torrey 和 Jude Shavlik 在他们关于迁移学习的章节中描述了使用迁移学习的时候可能带来的三种益处:
- 更高的起点。在微调之前,源模型的初始性能要比不使用迁移学习来的高。
- 更高的斜率。在训练的过程中源模型提升的速率要比不使用迁移学习来得快。
- 更高的渐进。训练得到的模型的收敛性能要比不使用迁移学习更好。
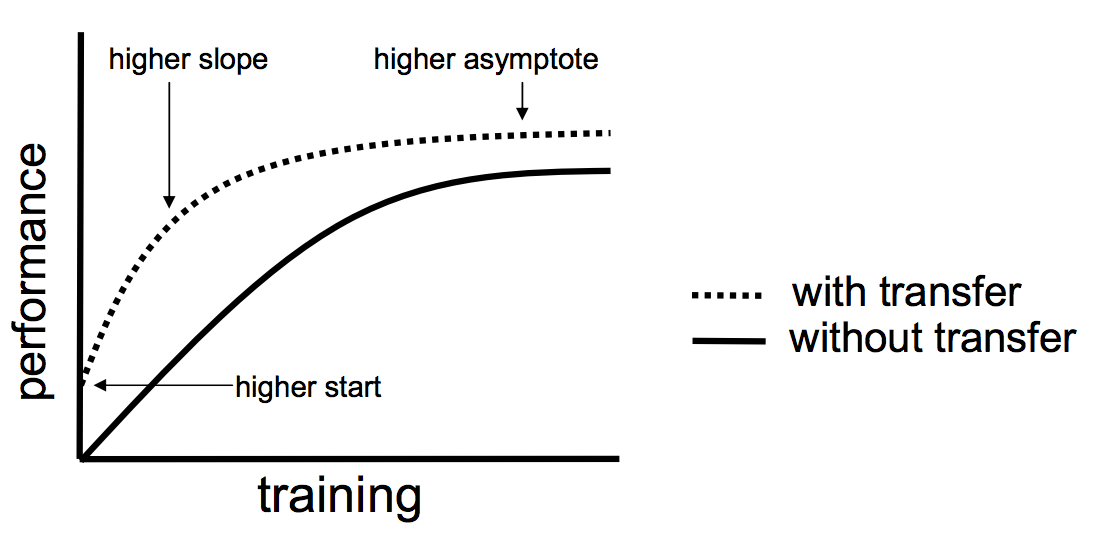
理想情况下,在一个成功的迁移学习应用中,你会得到上述这三种益处。
如果你能够发现一个与你的任务有相关性的任务,它具备丰富的数据,并且你也有资源来为它开发模型,那么,在你的任务中重用这个模型确实是一个好方法,或者(更好的情况),有一个可用的预训练模型,你可以将它作为你自己模型的训练初始点。
在一些问题上,你或许没有那么多的数据,这时候迁移学习可以让你开发出相对不使用迁移学习而言具有更高性能的模型。
对源数据和源模型的选择是一个开放问题,可能需要领域专家或者实际开发经验。
参考:深入理解预训练(pre-learning)、微调(fine-tuning)、迁移学习(transfer learning)三者的联系与区别_预训练和微调的区别-CSDN博客

