
- 1数据库课程设计报告总结_数据库课程设计总结
- 2计算机网络- 特定服务类型(Type of Service, TOS)& 服务质量(Quality of Service, QoS)_8位服务类型tos
- 3二叉树的七种遍历_7-1 二叉树的遍历!(简单)
- 4[nlp] Word2vec模型 skip-gram和CBOW区别_word2vec 比较skipgram和cbow
- 5H.264中的SPS和PPS_什么时候会出现sps 和pps
- 6十几年老Java咳血推荐,你薪资涨一波没毛病!小AD以为我端午都干嘛去了?
- 7快速体验 Llama3 的 4 种方式,本地部署,800 tokens/s 的推理速度真的太快了!_llama3推理速度
- 8SOA-Converter v1.3.2上线|新增Excel模板适配插件及ARXML合并功能,免费试用助你快速上手_excel转arxml
- 9Vivado中信号被优化掉,无法使用探针_vivado 设备设计和探针不匹配
- 10通信词典_feedmxu
元学习(meta-learning)的通俗解释
赞
踩
目录
1、什么是元学习
meta-learning 的一个很经典的英文解释是 learn to learn,即学会学习。元学习是一个很宽泛的概念,可以有很多实现的方式,下面以目标检测的例子来解释其中的思想。
在传统的目标检测任务中,我们都会为给模型海量的打了标签的数据集,本质是让模型去学习样本数据的数据分布,以期一个泛化的模型,使其可以在没有见过的图片中找到期望的目标。整个学习的过程就是相当于给模型很多某一类事物的照片,训练模型让他拥有分辨这些事物种类的能力,可以在一张没有见过的照片中找到是否有目标事物。
对于人类而言,认识一个新的种类其实并不需要看很多相关的照片,甚至只要看一眼没见过的事物就能达到在没见过的照片中准确分辨是否含有该类事物的效果,这是由于人天生的具有分辨事物异同的能力,在看到新的事物之后就能马上学习到他与已见过的事物的不同并在下次遇到时准确判断其种类。也就是人类具有学会学习的能力。
因此,相比来说,meta-learning 的目标不是让模型识别训练集里的图片并且泛化到测试集,而是让机器自己学会学习。还以目标检测为例,仍然拿一个很大的数据集来训练模型,而 meta-learning 的目标不是让模型在没见过的图片中学会分辨训练集中提到过的类别,而是让模型学会分辨事物的异同,学会分辨这两者是相同的东西还是不同的东西,当模型学会分辨异同之后再在具体的分类任务中使用极少的数据集训练很少的次数即可达到甚至超越传统目标检测训练范式的效果(这种方式也称为 Few-Shot Learning,即小样本学习)。
总的来说,当我们需要分辨的目标种类改变之后,传统的目标检测训练范式需要从头开始训练,而 meta-learning 则因为拥有了学习的(分辨异同)能力从而很快就能适应新的种类从而大大节省了从新学习的时间。下图就是对这种方法的阐述:元学习 通过训练任务学习到了具有分类能力的预训练网络
(
是元学习的模型),使用新的类型来训练
, 让他“学习”区分新的种类手机电脑得到模型
,这个
就是可以适应新的任务的模型了。

元学习分类任务
(图片来源:火炉课堂 | 元学习(meta-learning)到底是什么鬼?_哔哩哔哩_bilibili)
这种训练方式的一种具体的实现就是孪生神经网络(Siamese Network),孪生神经网络是无监督学习的一种,下面简单介绍这种网络的原理。
孪生神经网络拥有两个输入,分别是同样大小但不是同一种类别的图片,输出是两张图片的相似度。其结构如下图

孪生神经网络
具体地,先输入含有种类1的图片1,通过网络得到一个映射的特征向量h1,然后输入含有种类2的图片2,通过同样的网络得到另外一个映射的特征向量h2,通过比较向量h1、h2(比如做差)的相似度即可确定两者是否属于同一个类别,训练过程中只需要通过大量的不同类别的图片训练网络的异同辨别能力。在具体的分类任务中,我们只需要将目标图片与已有的已知种类的图片通过预训练好的神经网络做对比,通过输出即可判断目标图片是否属于这个种类。
以上是元学习在目标检测方面的一种应用,通过元学习训练模型提取不同种类图片的特征,然后在这个预训练的模型的基础上实现快速辨别新的图片种类。“元”在中文中含有“根本、根源”的意思,在深度学习中可以理解为:知道了更深层次(更基础)的知识后更有利于以后适应新事物的能力,这也对应了其英文解释“learn to learn”的思想。
2、元学习还可以做什么
元学习是一个思想,有很广泛的应用范围。
元学习可以用来学算法。即传统的深度学习都是手工设计好的模型(比如CNN、LSTM、DNN、具体多少层、每层的size以及激活函数都是确定好的)然后我们去学习模型的参数。而元学习可以更进一步,用来学习如何设计模型、如何挑选前述的网络结构等。
另外元学习还可以学习算法的超参(比如学习率等)、模型初始化参数(直接给出一个比较好的初始化参数,然后微调,可以大大节省训练时间)等。
3、元学习是如何训练的
一般的深度学习是在数据(data)上做训练,以使模型泛化到其他数据上也有很好的效果。而元学习是在任务(task)上做训练,以使模型在没见过的任务上也做得很好。
如下图所示。首先元学习 在任务1(task1)中学习得到算法(可以是模型结构、超参、初始化参数等)
,然后使用测试样本训练几次(一般一两次就可以了)
得到的模型
,在测试样本中评估元学习给出的算法
好不好,进而评估元学习
好不好,因为好的算法在训练有限次时就能达到较好的效果,这样每组测试样例就可以得到一个损失,若算法不好则对应得出的损失也不好,task2 也是同样的流程。这样将每个 task 的损失加起来求平均得到最终的损失。
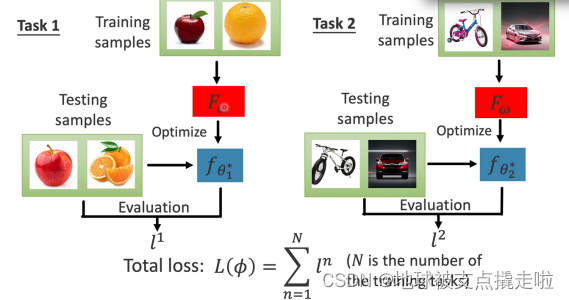
元学习的训练过程
(图片来源:火炉课堂 | 元学习(meta-learning)到底是什么鬼?_哔哩哔哩_bilibili)
可以看出,相比一般的深度学习过程,大部分的元学习任务在训练过程中需要计算二次导数,目前也有最新的研究表明将二次导通过一定的规则近似为一次导数更新模型不仅可以大大提升训练效率,还跟原始的二次导训练方式的性能不相上下,该部分目前仅仅了解了一下,先不做过多的学习。

