
- 1NLP实用小工具Tokenizer和pad_sequences进行文本的数字编码和长度填充或截断_tokenizer 统计特征的长度
- 2vue项目基于WebRTC实现一对一音视频通话_vue实战 1-1 webrtc点对点语音视频通话
- 3ADS仿真工具使用_ads仿真软件
- 4真实遇到的产品经理面试题
- 5【AI 大模型】提示工程 ① ( 通用人工智能 和 专用人工智能 | 掌握 提示工程 的优势 | 提示工程目的 | 提示词组成、迭代、调优及示例 | 思维链 | 启用思维链的指令 | 思维链原理 )_ai 提示词工程
- 6Item2vec_movielens item2vec
- 7JS常用方法_数组对象元素保留某些属性
- 8海康视觉平台VisionMaster使用学习笔记(1)_visionmaster图像源怎么连接相机
- 9【Pytorch】学习记录分享8——自然语言处理基础-词向量模型Word2Vec_pytorch word2vec
- 10⛳ TCP 协议详解
模型压缩:剪枝算法_滤波器剪枝
赞
踩

过参数化主要是指在训练阶段,在数学上需要进行大量的微分求解,去捕抓数据中的微小变化信息,一旦完成迭代式的训练之后,网络模型推理的时候就不需要这么多参数。而剪枝算法正是基于过参数化的理论基础而提出的。
剪枝算法核心思想就是减少网络模型中参数量和计算量,同时尽量保证模型的性能不受影响。
那在AI框架中,实际上剪枝主要作用在右下角的端侧模型推理应用场景中,为的就是让端侧模型更小,无论是平板、手机、手表、耳机等小型IOT设备都可以轻松使用AI模型。而实际在训练过程更多体现在剪枝算法和框架提供的剪枝API上面。

剪枝算法分类
实际上大部分刚接触剪枝算法的时候,都会从从宏观层面去划分剪枝技术,主要是分为Drop Out和Drop Connect两种经典的剪枝算法,如下图所示。
1)Drop Out:随机的将一些神经元的输出置零,称之为神经元剪枝。
2)Drop Connect:随机将部分神经元间的连接Connect置零,使得权重连接矩阵变得稀疏。
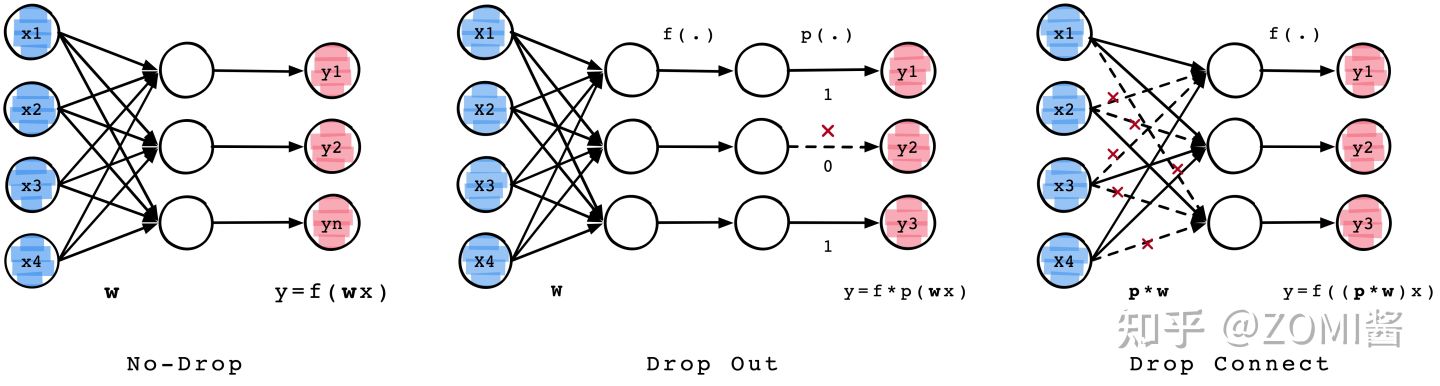
结构化剪枝 VS 非结构化剪枝
下面会把剪枝的更多种方式呈现出来,可能会稍微复杂哈。从剪枝的粒度来划分,可以分为结构化剪枝和非结构化剪枝,2个剪枝结构方法。下面来看看具体的剪枝方法有4种:
1) 细粒度剪枝(fine-grained):即对连接或者神经元进行剪枝,是粒度最小的剪枝,上面Drop Out和Drop Connect都是属于细粒度剪枝。
2) 向量剪枝(vector-level):它相对于细粒度剪枝粒度稍大,属于对卷积核内部(intra-kernel) 的剪枝。
3) 核剪枝(kernel-level):即去除某个卷积核,丢弃对输入通道中对应卷积核的计算。
4) 滤波器剪枝(Filter-level):对整个卷积核组进行剪枝,推理过程中输出特征通道数会改变。
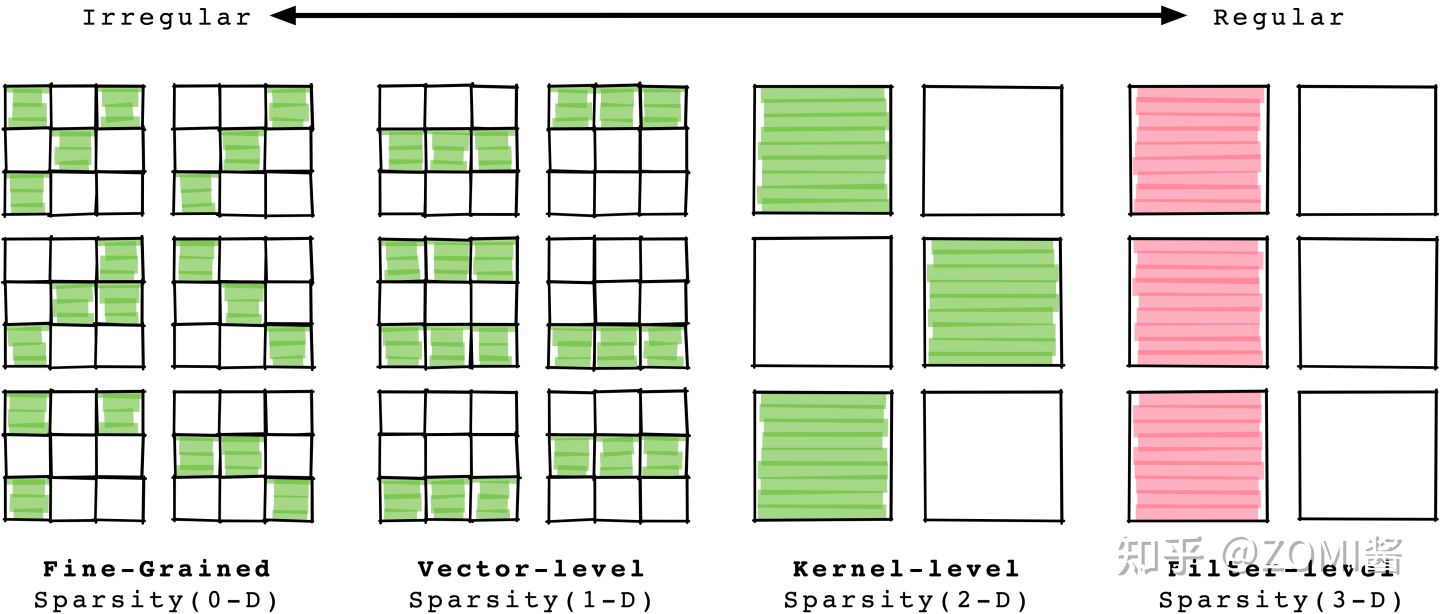
细粒度剪枝、向量剪枝、核剪枝在参数量与模型性能之间取得了一定的平衡,但是网络模型单层的神经元之间的组合结构发生了变化,需要专门的算法或者硬件结构来支持稀疏的运算,这种叫做结构化剪枝(Unstructured Pruning)。
其中,非结构化剪枝能够实现更高的压缩率,同时保持较高的模型性能,然而会带来网络模型稀疏化,其稀疏结构对于硬件加速计算并不友好,除非底层硬件和计算加速库对稀疏计算有比较好的支持,否则剪枝后很难获得实质的性能提升。
滤波器剪枝(Filter-level)主要改变网络中的滤波器组和特征通道数目,所获得的模型不需要专门的算法和硬件就能够运行,被称为结构化剪枝(Structured Pruning)。结构化剪枝又可进一步细分:可以是channel-wise,也可以是filter-wise,还可以是在shape-wise。
结构化剪枝与非结构化剪枝恰恰相反,可以方便改变网络模型的结构特征,从而达到压缩模型的效果,例如知识蒸馏中的student网络模型、NAS搜索或者如VGG19和VGG16这种裁剪模型,也可以看做变相的结构化剪枝行为。
剪枝算法流程
虽然剪枝算法的分类看上去很多,但是核心思想还是对神经网络模型进行剪枝,目前剪枝算法的总体流程大同小异,可以归结为三种:标准剪枝、基于子模型采样的剪枝、以及基于搜索的剪枝,如下图所示。
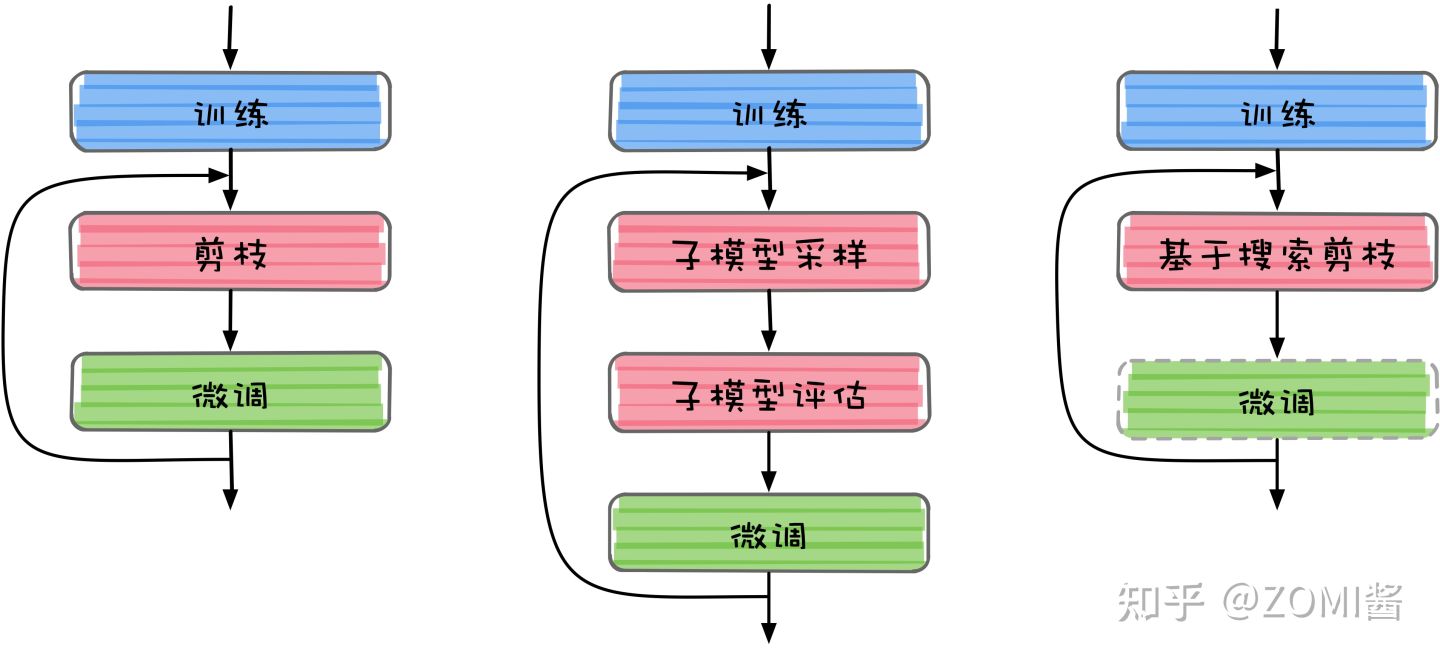
标准剪枝算法流程
标准剪枝是目前最流行的剪枝流程,在Tensorflow、Pytroch都有标准的接口。主要包含三个部分:训练、剪枝、以及微调。
1)训练:首先是对网络模型进行训练。在剪枝流程中,训练部分主要指预训练,训练的目的是为剪枝算法获得在特定基础SOTA任务上训练好的原始模型。
2) 剪枝:在这里面可以进行如细粒度剪枝、向量剪枝、核剪枝、滤波器剪枝等各种不同的剪枝算法。其中很重要的就一点,就是在剪枝之后,对网络模型结构进行评估。确定一个需要剪枝的层,设定一个裁剪阈值或者比例。实现上,通过修改代码加入一个与参数矩阵尺寸一致的Mask矩阵。Mask矩阵中只有0和1,实际上是用于微调网络。
3)微调:微调是恢复被剪枝操作影响的模型表达能力的必要步骤。结构化模型剪枝会对原始模型结构进行调整,因此剪枝后的模型参数虽然保留了原始的模型参数,但是由于模型结构的改变,剪枝后模型的表达能力会受到一定程度的影响。实现上,微调网络模型,参数在计算的时候先乘以该Mask,Mask为1的参数值将继续训练通过BP调整梯度,而Mask为0的部分因为输出始终为0则不对后续部分产生影响。
4)再剪枝:再剪枝过程将微调之后的网络模型再送到剪枝模块中,再次进行模型结构评估和执行剪枝算法。目的是使得每次剪枝都在性能更优的模型上面进行,不断迭代式地进行优化剪枝模型,直到模型能够满足剪枝目标需求。
最后输出模型参数储存的时候,因为有大量的稀疏,所以可以重新定义储存的数据结构, 仅储存非零值以及其矩阵位置。重新读取模型参数的时候,就可以还原矩阵。

基于子模型采样流程
除标准剪枝之外,基于子模型采样的剪枝《EagleEye: Fast sub-net evaluation for efficient neural network pruning》最近也表现出比较好的剪枝效果。得到训练好的模型之后,进行子模型采样过程。一次子模型采样过程为:
1)对训练好的原模型中可修剪的网络结构,按照剪枝目标进行采样,采样过程可以是随机的,也可以按照网络结构的重要性或者通过KL散度计算进行概率采样。
2)对采样后的网络结构进行剪枝,得到采样子模型。子模型采样过程通常进行 次,得到 个子模型( ≥1), 之后对每一个子模型进行性能评估。子模型评估结束之后,选取最优的子模型进行微调以得倒最后的剪枝模型。
基于搜索的剪枝流程
基于搜索的剪枝主要依靠强化学习等一系列无监督学习或者半监督学习算法,也可以是神经网络结构搜索相关理论。
给定剪枝目标之后,基于搜索的剪枝在网络结构中搜索较优的子结构,这个搜索过程往往伴随着网络参数的学习过程,因此一些基于搜索的剪枝算法在剪枝结束后不需要再进行微调。
剪枝的发展
这几年神经网络剪枝pruning作为模型压缩技术的四小龙之一,正在受到越来越多的关注。当然,各种更好的pruning参数选取方法一定还会层出不穷。另外,从趋势来看,以下几个方向值得关注:
打破固定假设:挑战已有的固有的假设,例如ICLR2019会议的best paper彩票假说《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks 》的出现。还有一开始提到的对于over-parameterization,与重用已有参数是否有有益的反思非常有意思。这样的工作会给剪枝算法非常大的启发,从而根本改变解决问题的思路。
自动化剪枝:随着AutoML的大潮,越来越多的算法开始走向自动化。模型压缩能拉下吗?当然不能。经过前面的介绍我们知道,像ADC,RNP,N2N Learning这些工作都是试图将剪枝中部分工作自动化。如量化中的《HAQ: Hardware-Aware Automated Quantization》考虑网络中不同层信息的冗余程度不一样,所以自动化使用混合量化比特进行压缩。
与NAS融合:如前面模型剪枝流程中提到,剪枝算法与神经网络搜索NAS的界限已经模糊了。NAS有针对结构化剪枝进行搜索方法,如One-Shot Architecture Search是先有一个大网络,然后做减法。NAS与模型压缩两个一开始看似关系不是那么大的分支,在近几年的发展过程中因为下游任务和部署场景的需求,最后似乎会走到一块去。这两个分支今天有了更多的交集,也必将擦出更多的火花。
与GAN融合:这几年机器学习最火热的分支之一GAN,正在不断渗透到已有领域,在pruning中也开始有它的身影。如2019年《Towards Optimal Structured CNN Pruning via Generative Adversarial Learning》让generator生成裁剪后网络,discrimintor来判别是否属于原网络还是裁剪后网络,从而进行更有效的网络结构化裁剪。
硬件稀疏性支持:剪枝会给神经网络模型带来稀疏性特征,参数稀疏性在计算中会有大量的索引,所以并不能加速。现在虽然有像cuSPARSE这样的计算库,但底层硬件AI芯片本身设计并不是专门为稀疏数据处理打造的。如果能将稀疏计算和处理能力做进芯片那必将极大提高计算效率。仅2021年中国就推出了10+款基于ASIC的AI加速芯片,相信针对稀疏性场景的支持在未来会有所突破。
总结
模型压缩算法中针对已有的模型,有:张量分解,模型剪枝,模型量化。针对新构建的网络,有:知识蒸馏,紧凑网络设计等方法。
剪枝只是模型压缩方法中的一种,它与其它模型压缩方法并不冲突,因此会与量化、蒸馏、NAS、强化学习等方法慢慢融合,这些都是很值得研究的方向。另外在上面的发展来看,打破固有的假设定义,与NAS、GAN、AutoML、RL等技术进行相互的融合,可能到最后会模糊purning方式,出现新的范式或者压缩模式也是很吸引的。

