
- 1echarts Map(地图) 波纹数据点_acroutes
- 2cad.net 筛选、选择集_cad.net过滤选择集
- 3Unity3d--让我们的小坦克动起来_using unityengine; public class tankmovement : mon
- 4git代码托管平台_国内git代码托管平台
- 5fftw3图片傅里叶变换_使用傅里叶变换进行图像边缘检测
- 6在COCOS2D项目中添加BOX2D支持注意点_cocos 动态添加 boxcollider2d
- 7Unity 摄像机控制脚本(全局通用),可根据需要自己修改!_unity脚本挂载main camera
- 8vue中使用百度地图 完成展示坐标,点击坐标展示相关信息_vue使用百度地图根据坐标显示位置
- 9antdegin vue 设置局部样式_ant-card-body
- 10vue中使用baidu-map获取当前坐标。
基于深度学习的森林火焰烟雾检测系统(含UI界面,Python代码,数据集、yolov5)_python火焰目标区域检测
赞
踩


项目介绍
项目中所用到的算法模型和数据集等信息如下:
算法模型:
yolov5
yolov5主要包含以下几种创新:
1. 添加注意力机制(SE、CBAM、CA等)
2. 修改可变形卷积(DySnake-主干c3替换、DySnake-所有c3替换)
3. 后续会增加模型结构创新
数据集:
网上下载的开源数据集
以上是本套代码的算法架构和对目标检测模型的修改说明,这些模型修改可以为您的 毕设、作业等提供创新点和增强模型性能的功能 。
如果要是需要更换其他的检测模型,请私信。
注:本项目提供用到的所有资源,包含 环境安装包、训练代码、测试代码、数据集、视频文件、 界面UI文件等。
项目简介
本文将详细介绍如何使用深度学习中的YOLOv5算法实现对森林火焰烟雾的检测,并利用PyQt5设计了简约的系统UI界面。在界面中,您可以选择自己的视频文件、图片文件进行检测。此外,您还可以更换自己训练的yolov5模型,进行自己数据的检测。
该系统界面优美,检测精度高,功能强大。它具备多目标实时检测,同时可以自由选择感兴趣的检测目标。
本博文提供了完整的Python程序代码和使用教程,适合新入门的朋友参考。您可以在文末的下载链接中获取完整的代码资源文件。以下是本博文的目录:
功能演示
功能:
1. 支持单张图片识别
2. 支持遍历文件夹识别
3. 支持识别视频文件
4. 支持结果导出(xls、csv两种格式)
5. 支持切换检测到的目标
下面视频是对整体功能的演示:
基于深度学习的森林火焰烟雾检测系统
✨一、环境安装
本项目提供所有需要的环境安装包(python、pycharm、cuda、torch等),可以直接按照视频讲解进行安装。具体的安装流程见此视频:视频链接
环境安装视频是以车牌项目为例进行讲解的,但是可以适用于任何项目。
视频快进到 3:18 - 21:17,这段时间讲解的是环境安装,可直接快进到此处观看。
环境安装包可通过百度网盘下载:
链接:https://pan.baidu.com/s/17SZHeVZrpXsi513D-6KmQw?pwd=a0gi
提取码:a0gi
–来自百度网盘超级会员V6的分享
上面这个方法,是比较傻瓜式的安装方式,按照我的视频步骤和提供的安装包安装即可,如果要是想要多学一点东西,可以按照下面的安装方式走一遍,会更加熟悉。
环境安装方法2:
追求快速安装环境的,只看上面即可!!!
下面列出了5个步骤,是完全从0开始安装(可以理解为是一台新电脑,没有任何环境),如果某些步骤已经安装过的可以跳过。下面的安装步骤带有详细的视频讲解和参考博客,一步一步来即可。另外视频中讲解的安装方法是通用的,可用于任何项目。
按照上面的步骤安装完环境后,就可以直接运行程序,看到效果了。
✨二、数据集介绍
数据集是在网上自己下载的别人标注好的,可以直接拿过来使用,这里不做过多的介绍了,而且已经做好了 train、val、test 数据集分类,标注效果如下图:

后来发现 飞桨 上也有1个开源的数据集,可以自己训练一下玩玩,下载链接。
✨三、 yolov5相关介绍
本系统采用了基于深度学习的目标检测算法YOLOv5,该算法是YOLO系列算法的较新版本,相比于YOLOv3和YOLOv4,YOLOv5在检测精度和速度上都有很大的提升。YOLOv5算法的核心思想是将目标检测问题转化为一个回归问题。此外,YOLOv5还引入了一种称为SPP(Spatial Pyramid Pooling)的特征提取方法,这种方法可以在不增加计算量的情况下,有效地提取多尺度特征,提高检测性能。
在YOLOv5中,首先将输入图像通过骨干网络进行特征提取,得到一系列特征图。然后,通过对这些特征图进行处理,将其转化为一组检测框和相应的类别概率分数,即每个检测框所属的物体类别以及该物体的置信度。YOLOv5中的特征提取网络使用CSPNet(Cross Stage Partial Network)结构,它将输入特征图分为两部分,一部分通过一系列卷积层进行处理,另一部分直接进行下采样,最后将这两部分特征图进行融合。这种设计使得网络具有更强的非线性表达能力,可以更好地处理目标检测任务中的复杂背景和多样化物体。
在YOLOv5中,每个检测框由其左上角坐标(x,y)、宽度(w)、高度(h)和置信度(confidence)组成。同时,每个检测框还会预测C个类别的概率得分,即分类得分(ci),每个类别的得分之和等于1。因此,每个检测框最终被表示为一个(C+5)维的向量。在训练阶段,YOLOv5使用交叉熵损失函数来优化模型。损失函数由定位损失、置信度损失和分类损失三部分组成,其中定位损失和置信度损失采用了Focal Loss和IoU Loss等优化方法,能够有效地缓解正负样本不平衡和目标尺寸变化等问题。
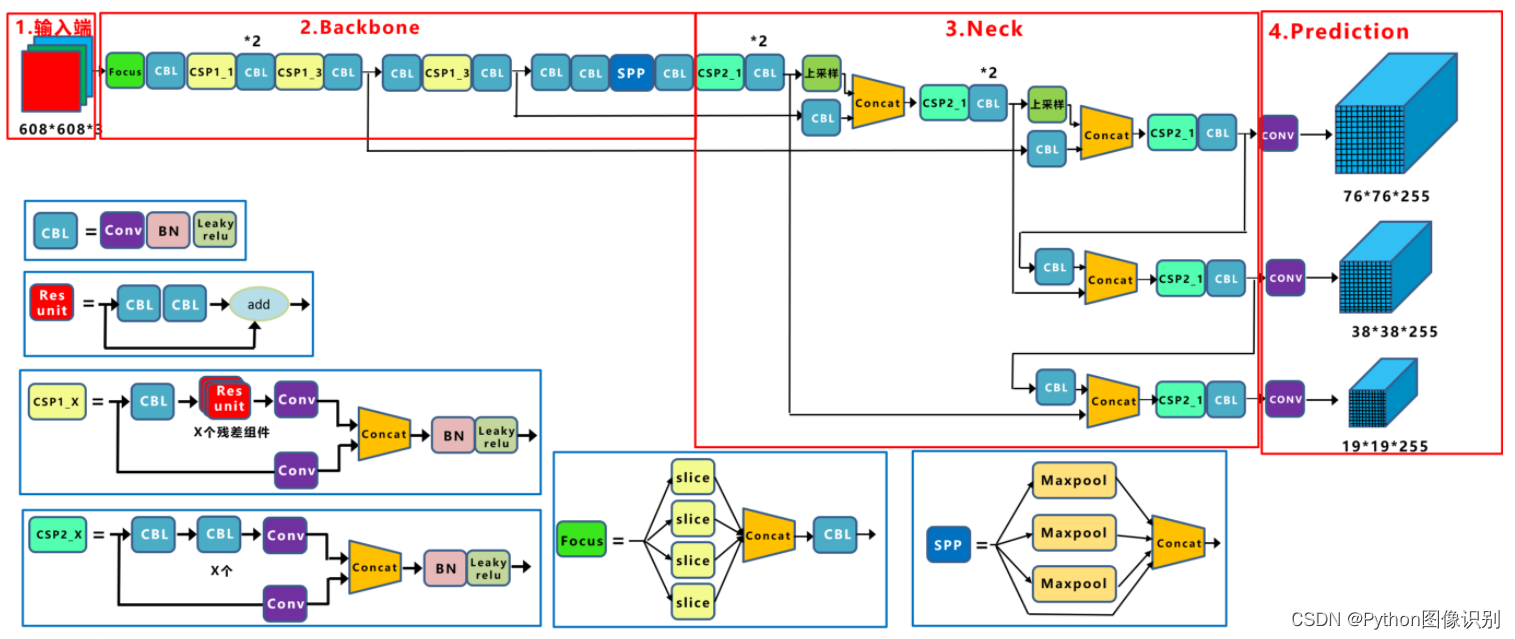
YOLOv5网络结构是由Input、Backbone、Neck、Prediction组成。Yolov5的Input部分是网络的输入端,采用Mosaic数据增强方式,对输入数据随机裁剪,然后进行拼接。Backbone是Yolov5提取特征的网络部分,特征提取能力直接影响整个网络性能。YOLOv5的Backbone相比于之前Yolov4提出了新的Focus结构。Focus结构是将图片进行切片操作,将W(宽)、H(高)信息转移到了通道空间中,使得在没有丢失任何信息的情况下,进行了2倍下采样操作。
✨四、 yolov5训练步骤
个人修改模型结构的代码以及配置的yaml文件都已经封装好了,所以训练步骤极其简单,不需要修改代码,直接通过cmd就可以命令运行,而且命令都已写好,直接复制即可,训练的命令如下图(另外,封装好的代码只需要修改数据集的yaml文件,就可以去训练自己别的数据集,移植非常简单。 ):

封装好的yaml文件和各个模型结构py文件,目前包含CA、CBAM、ECA等注意力机制以及DySnake蛇形卷积,后续会继续增加,如下图所示:
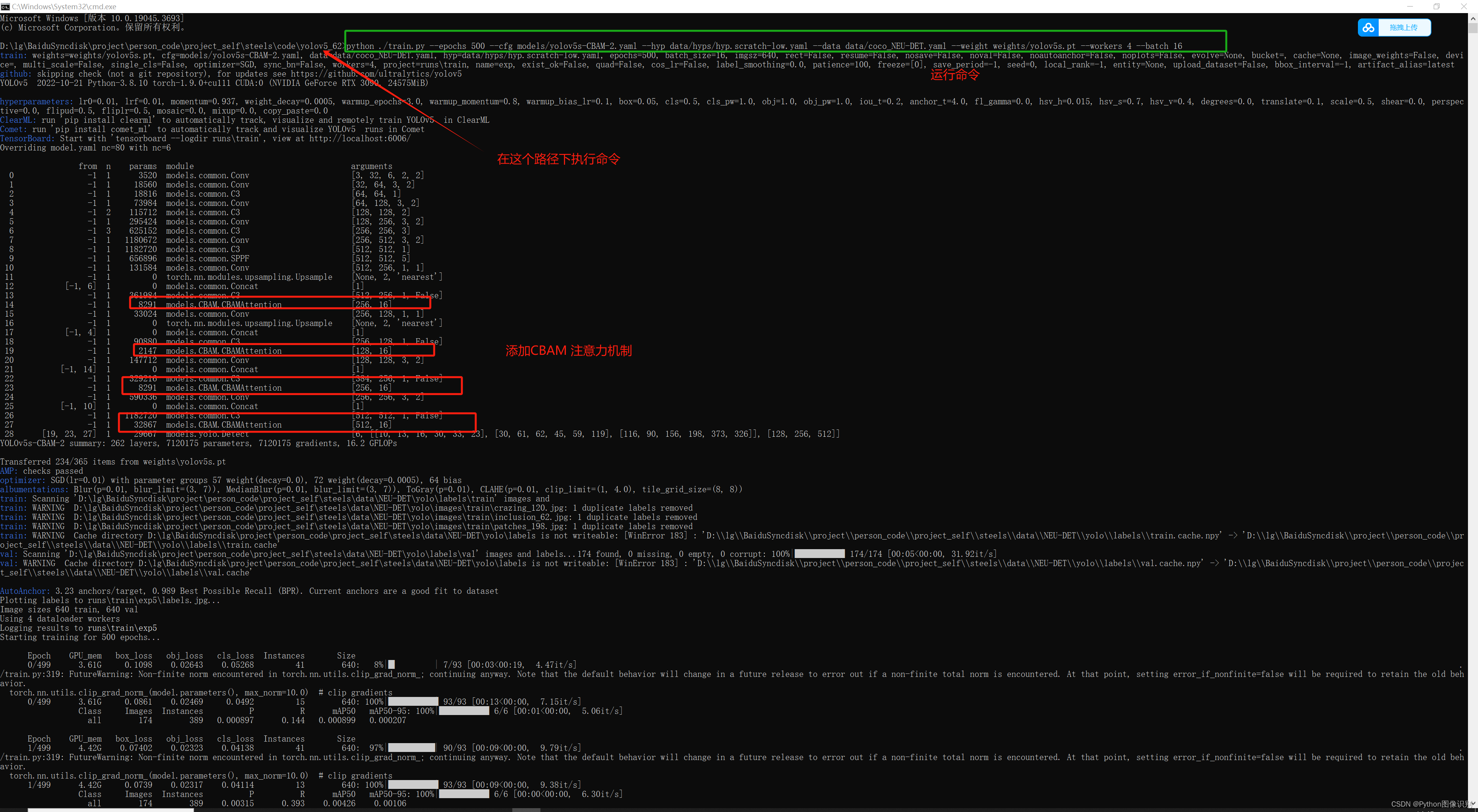
下面这条命令是 训练 添加 CBAM 注意力机制的训练命令,复制下来,直接就可以运行,看到训练效果。
python ./train.py --epochs 500 --cfg models/yolov5s-CBAM-2.yaml --hyp data/hyps/hyp.scratch-low.yaml --data data/coco_fire.yaml --weight weights/yolov5s.pt --workers 4 --batch 16
- 1
执行完上述命令后,即可进行训练,训练过程如下:
下面是对命令中各个参数的详细解释说明:
-
python: 这是Python解释器的命令行执行器,用于执行后续的Python脚本。 -
./train.py: 这是要执行的Python脚本文件的路径和名称,它是用于训练目标检测模型的脚本。 -
--epochs 500: 这是训练的总轮数(epochs),指定为500,表示训练将运行500个轮次。 -
--cfg models/yolov5s-CBAM-2.yaml: 这是YOLOv5模型的配置文件的路径和名称,它指定了模型的结构和参数设置。 -
--hyp data/hyps/hyp.scratch-low.yaml: 这是超参数文件的路径和名称,它包含了训练过程中的各种超参数设置,如学习率、权重衰减等。 -
--data data/coco_fire.yaml: 这是数据集的配置文件的路径和名称,它指定了训练数据集的相关信息,如类别标签、图像路径等。 -
--weight weights/yolov5s.pt: 这是预训练权重文件的路径和名称,用于加载已经训练好的模型权重以便继续训练或进行迁移学习。 -
--workers 4: 这是用于数据加载的工作进程数,指定为4,表示使用4个工作进程来加速数据加载。 -
--batch 16: 这是每个批次的样本数,指定为16,表示每个训练批次将包含16个样本。
通过运行上面这个命令,您将使用YOLOv5模型对目标检测任务进行训练,训练500个轮次,使用指定的配置文件、超参数文件、数据集配置文件和预训练权重。同时,使用4个工作进程来加速数据加载,并且每个训练批次包含16个样本。
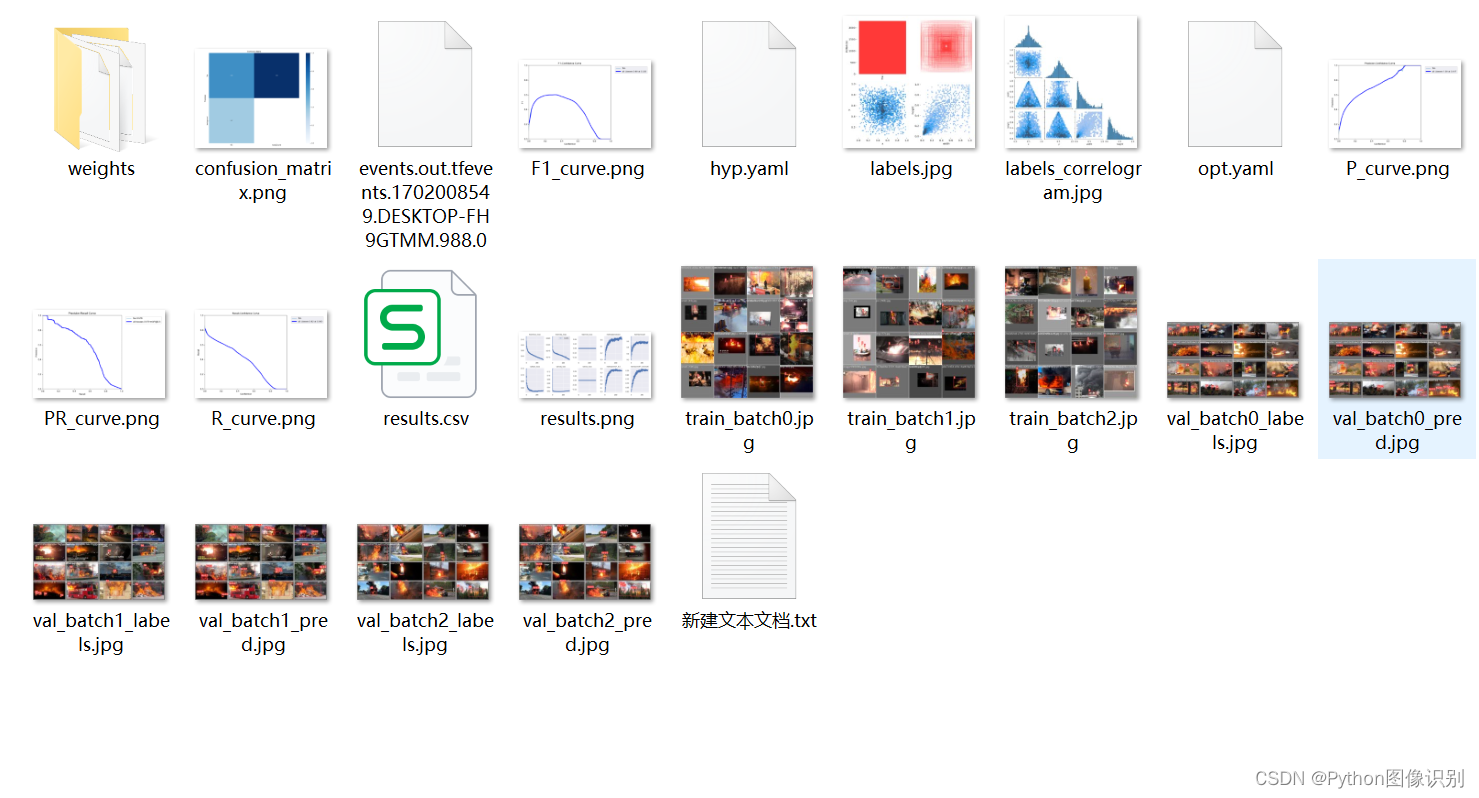
✨五、 训练结果
我们执行完上面的命令后,进行模型训练,训练完成后,会在 run/train 文件夹下出现一系列的文件,如下图所示:
✨六、 yolov5评估步骤
评估步骤同训练步骤一样,执行1行语句即可,注意--weights需要变为自己想要测试的模型路径。
python ./val.py --batch-size 4 --data data/coco_fire.yaml --weights ../weights/YOLOv5s-CA.yaml/weights/best.pt --workers 2
- 1
- 2
评估结果如下:
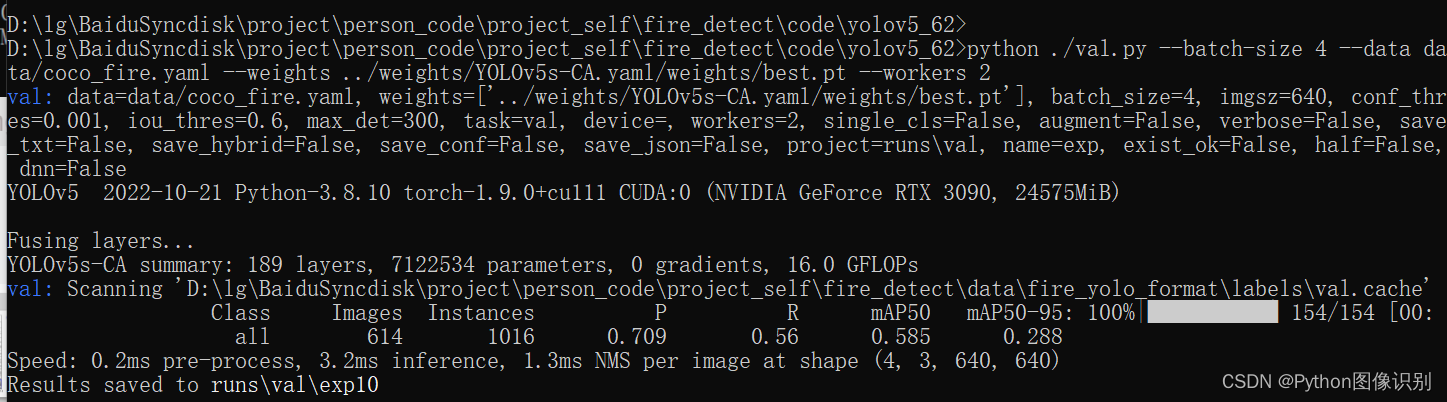
评估结果中包含 以下内容:
❤️下载链接
该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为main.py,提供用到的所有程序。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,为避免出现运行报错,请勿使用其他版本,详见requirements.txt文件;
若您想获得博文中涉及的实现完整全部程序文件(包括训练代码、测试代码、训练数据、测试数据、视频,py、 UI文件等,如下图),这里已打包上传至博主的面包多平台,可通过下方项目讲解链接中的视频简介部分下载,完整文件截图如下:
项目讲解链接:B站

