
热门标签
热门文章
- 1Android studio的 gradle project sync failed_android studio gradle project sync filed
- 254、记录yolov7 训练、部署ncnn、部署mnn、部署rk3399pro npu、部署openvino、部署oak vpu、部署TensorRT_yolov7-rk3399pro
- 3Logistic Regression(逻辑回归)基本原理与学习总结_逻辑回归的学习准则
- 4LoRA大模型加速微调和训练算法解读_lora增量微调
- 5【OpenCV】人脸检测和识别_opencv人脸特征提取与检测
- 6转jpg java源程序,将原始数据转换为JPEG格式-JAVA
- 7SIM900A—发送、接收中英文短信_at+csmp
- 82024最新首发,全网最全 Spring Boot 学习宝典(附思维导图)_springboot最新
- 9高并发分布式计算-生产实践
- 10Android应用的闪退(crash)分析_com.android.launcher3/u0a121 (adj 100): crash
当前位置: article > 正文
《推荐系统》基于标签的用户推荐系统
作者:你好赵伟 | 2024-03-20 16:15:57
赞
踩
for tag, wut in user_tags[user].items(): for item, wti in tag_items[tag].ite

打开微信扫一扫,关注微信公众号【数据与算法联盟】
Github:
https://github.com/thinkgamer
1:联系用户兴趣和物品的方式
2:标签系统的典型代表
3:用户如何打标签
4:基于标签的推荐系统
5:算法的改进
6:标签推荐
源代码查看地址:github查看
一:联系用户兴趣和物品的方式
推荐系统的目的是联系用户的兴趣和物品,这种联系方式需要依赖不同的媒介。目前流行的推荐系统基本上是通过三种方式联系用户兴趣和物品。
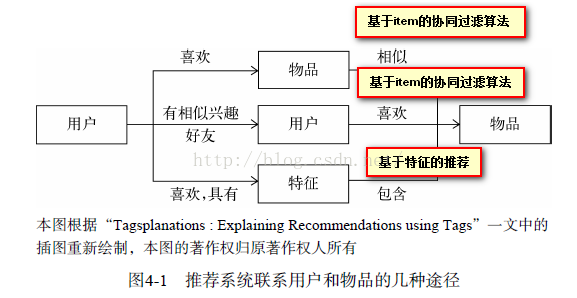
1:利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,即基于item的系统过滤推荐算法(算法分析可参考:点击阅读)
2:利用用户和兴趣用户兴趣相似的其他用户,给用户推荐哪些和他们兴趣爱好相似的其他用户喜欢的物品,即基于User的协同过滤推荐算法(算法分析可参考:点击阅读)
3:通过一些特征联系用户和物品,给用户推荐那些具有用户喜欢的特征的物品,这里的特征有不同的表现形式,比如可以表现为物品的属性集合,也可以表现为隐语义向量,而下面我们要讨论的是一种重要的特征表现形式——标签
二:标签系统的典型代表
pass掉那些国外网站,比如说豆瓣图书(左),网易云音乐(右)
标签系统确实能够帮助用户发现他们喜欢和感兴趣的物品
三:用户如何打标签
在互联网中每个人的行为都是随机的,但其实这些表面的行为隐藏着很多规律,那么我们对用户打的标签进行统计呢,便引入了标签流行度,我们定义的一个标签被一个用户使用在一个物品上,他的流行度就加1,可以如下代码实现:
- #统计标签流行度
- def TagPopularity(records):
- tagfreq = dict()
- for user, item ,tag in records:
- if tag not in tagfreq:
- tagfreq[tag] = 1
- else:
- tagfreq[tag] +=1
- return tagfreq
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/274948
推荐阅读
相关标签

