
- 1spark SQL语法 与 DSL语法_sparksqldsl语法
- 2Java面试常见的面试题(持续更新版)_java面试题
- 3PostgreSQL生成RESTful神器PostgREST_pgsql 数据库表 转 restapi
- 4Spring框架系列之第三章 AOP
- 5jscript经典(待整理)_jscript script var menu = menu 装入数据库
- 6neo4j.exceptions.AuthError_neo4j.exceptions.autherror: {code: neo.clienterror
- 7Springboot与Ajax整合练习?_springboot 2.3.12 整合 ajxs
- 8大学本科生论文需要查aigc吗?哪个平台AI率更高呢!_本科论文查重看aigc吗
- 9使用Otter同步MySQL数据详解_otter使用介绍
- 10一文揭密字节跳动薪资职级,资深测试开发居然能拿......_字节职级
【python】通用的json_diff方法_diff-json
赞
踩
作为职场新人,遇到系统重构的需求时,往往手足无措。我在测试商业推广变更记录需求时,就遇到了类似的问题。在测试这个需求的过程中,我发现接口diff方式很适合这类需求的特点,可以快速对这类需求进行测试,于是,在这个需求中,我采用了接口diff的方式对其进行测试,并且,将diff功能抽取成公共的测试能力,提供给其他人使用。下面,我就具体介绍一下我是如何做的。
1.需求背景:
推广变更记录这个需求的主要目的是在原有的推广变更日志的基础上,增加新的操作记录,同时将旧数据清洗到新的数据库表中。因为旧的接口记录的推广变更记录不全,导致产品以及运营排查推广信息变更效率低下,所以本次需求,一方面是丰富推广变更记录的信息,提升推广变更问题的排查效率,让运营同学可以看到推广信息变动是由商家本人修改还是运营同学代客操作修改或者是系统定时任务修改。另一方面,由于新变更记录的信息相比原来内容有所增加,新增的操作记录需要存储到新的数据库表中,旧数据也需要清洗到新数据库表中,获取变更记录的接口也换成了新接口。所以测试时,一方面要测试新增的操作记录是否正确记录,另一方面,需要关注被清洗的操作记录数据的准确性。
在测试旧数据清洗时,一开始的思路是,对清洗的数据在新旧两张表中进行比较,但这种方式比较繁琐,也不直观。想到新旧两个接口的主要功能是一样的,返回的核心内容是一致的,新接口只是新增了部分字段,因此在测试数据清洗的正确性时,我只需要用新旧接口进行比对,确保新旧两个接口返回的创建记录时间一致、且操作内容一致即可。顺着这个思路,我利用积累的python基础,想到可以做一个实用的diff工具来解决这类问题。
2.工具实现方法:
工具使用python的第三方requests库,用rep=requests.get(url,cookies,params)方法处理http的get方法。工具通过将url、接口需要的参数以及cookie按照格式放到rep=requests.get(url,cookies,params)中,得到新旧两个接口的返回字符串结果。
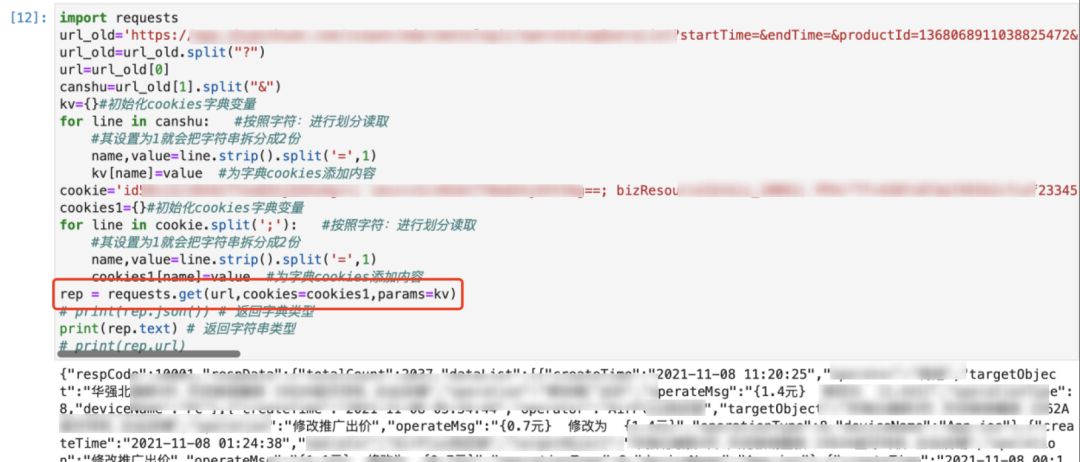
以变更推广出价操作记录为例,推广信息中的核心校验点为推广出价,通过字符串的split方法得到json返回结果中respData的dataList数据,根据两个json返回结果的createTime字段进行匹配,相同变更时间认为匹配成功。匹配成功的数据比较operateMsg和operateChange中的价格变更部分,数字的部分使用正则匹配获取。由于新旧接口的价格单位不同,分别进行按“分”和“元”两种单位的匹配,若都不能匹配成功,则认为匹配失败,清洗数据或变更记录有误。
旧接口返回如下图左侧所示的json数据:

新接口返回如下图右侧所示的json数据:

时间和价格都匹配成功时,打印匹配成功的结果。不能成功匹配时的结果如下,[0.8,1.5]表示旧接口的出价变更为0.8元调整至1.5元,[0.8,1.45]表示新接口的出价变更为0.8元调整至1.45元,价格匹配失败。

3.diff通用能力抽取:
在组内例会进行思路分享时,我发现其他同学也有系统重构、接口迁移等类似的需求。我意识到,这种diff的测试方式可以扩展到不同的业务场景。我的这种处理方式——根据返回的json字符串进行split,并不是通用的方法,当比对接口改变,json数据更改后,不同的匹配字段需要大范围改split部分的代码逻辑。
为了提高工具的适用性,我通过查资料发现json.loads方法可以直接将json数据转化为python字典格式,只需要将待比较的字典key值写进去就可以比较对应的value。产出工具的第一版优化,如下图所示,下图比较的是json的respData commentList字段,如需对比其他字段,只需要将代码中的commentList部分替换成需要对比的字段名即可。
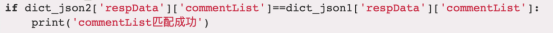
但是第一版工具有两个缺点:
(1)只能根据写好的字段位置进行匹配,一级目录是respData,二级目录为commentlist。若不提供一级目录,只提供要比较的二级目录,json解析时会因找不到逐层目录而出现问题。所以要求使用者使用时要给出逐层目录,不支持只给出最底层目录,如果有多个同名底层目录就就会造成无法比较的问题。
解决方案是:工具增加了一个参数,用来传入比较字段,比较字段需要按照指定格式进行传参才能解析。比较字段的通用适配格式为
{"respData":[{"dealList":"name"},{"List":"price"}]}
对这串数据进行解析匹配两条json的[‘respData’][‘dealList’][‘name’]字段和[‘respData’][‘List’][‘price’]字段。比较字段为
{"respData":[{"dealList":"name"},"List"],"data":["name"]}
时,需要比对的是两条json的[‘reapData’][‘dealList’][‘name’]和[‘respData’][‘List’]以及[‘data’][‘name’]三个字段。字段解析的代码实现方法是使用递归的方法匹配到中括号,如果respData的返回结果是中括号,则认为已经匹配到最底层。遇到类似
{"respData":{"dealList":["name"]}}
这种格式,respData的结果是大括号,则递归匹配,再匹配dealList的结果,匹配到最底层name。
(2)使用“==”匹配数据只能匹配完全相同的json数据,若是json字段内list顺序不对,也会对结果产生影响。
解决方案是:用isinstance方法进行判断是否为list,如果两个json数据的字段返回值均为list型,将第一个list的每个元素取出来看是否在另一个json的list列表中,第二个list做相同操作。此方法可以解决由于list内元素顺序不同,“==”解决不了的情况。
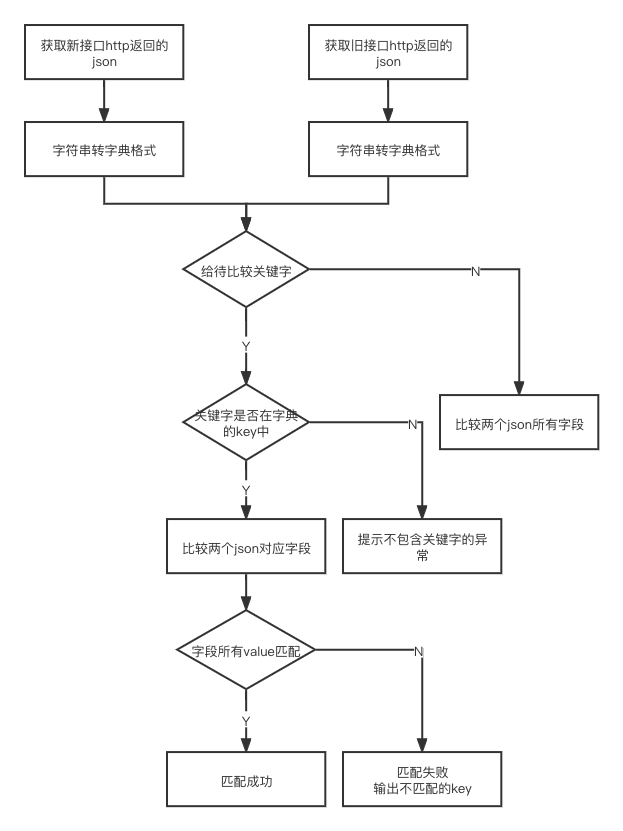
此外,第二版工具支持不输入比较字段参数的情况,如果参数为空,则比较两个json的全部字段是否匹配。具体做法是:对两个json进行解析,使用json.loads解析成字典格式后,先对长度进行判断,使用dict.keys()方法获取所有的key,循环逐层根据长度和内容比较json的所有字段,得到最终的匹配结果,具体流程如下图所示。
为方便其他同学使用比对工具,最后将写好的python代码封装成http接口,提供通用diff的能力。最终的效果如下图所示:
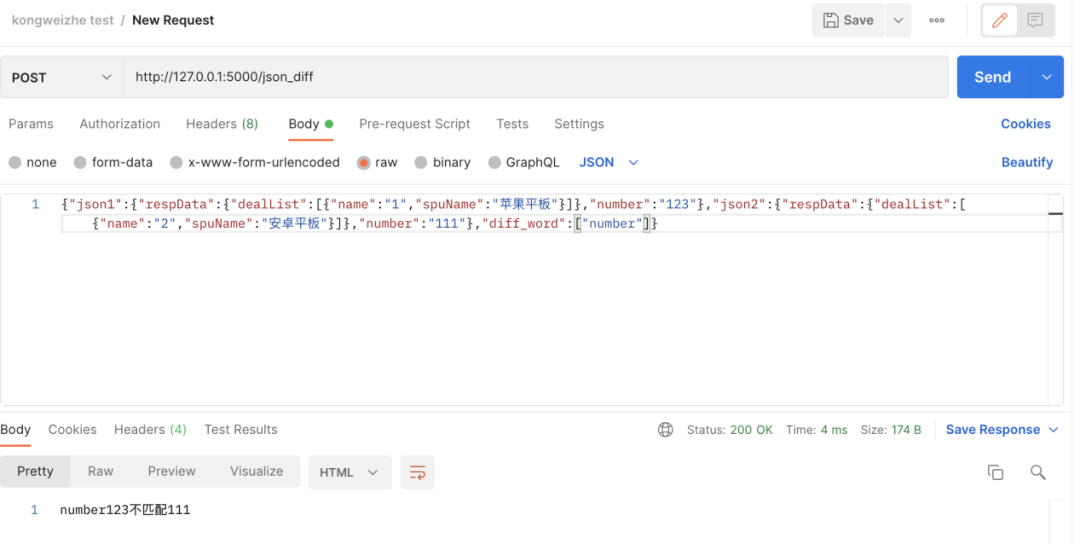
输入一个json,json中包含两个待比较的json数据以及一个diff_word。当diff_word中没给匹配关键词,进行两个json的匹配:
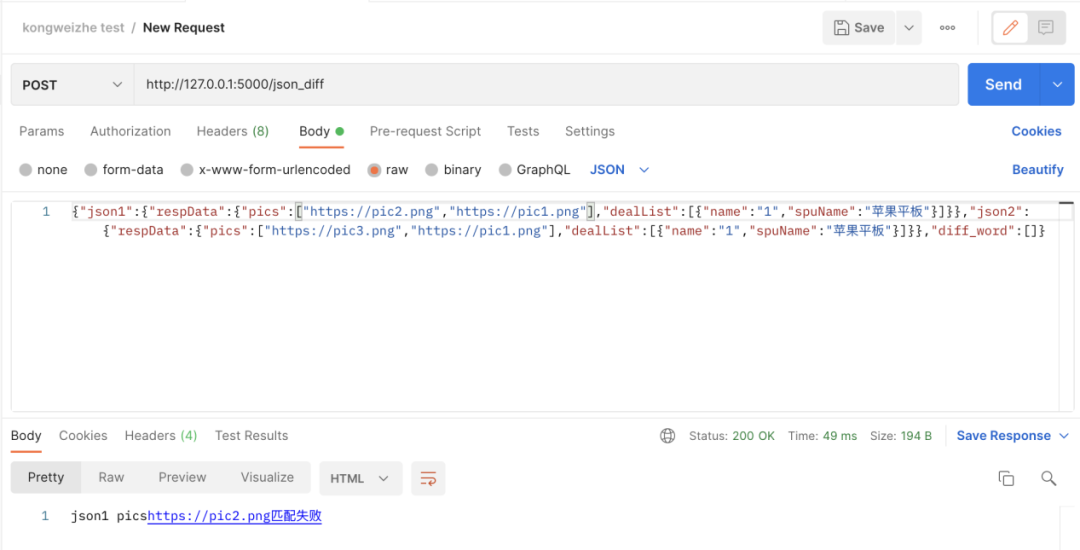
若是diff_word给出关键词number,只匹配对应关键词部分内容,不考虑其余部分内容是否匹配:
4.总结规划:
目前的diff能力已经基本能够满足一般的diff诉求,后续的规划是与我们的接口测试平台结合,在接口平台上提供接口diff的测试能力。要达到这样的结果,对于比较关键词的格式需要慎重考虑,一方面,要考虑到使用者的使用便利性,另外一方面,也需要考虑技术方案的可实现性。
作者:孔维喆
> 转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
> 关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~

