
- 1FPGA之JESD204B接口——总体概要 实例 下_hmc7044驱动
- 2YOLOv10改进 | Conv篇 |YOLOv10引入SPD-Conv卷积
- 3NLP中的Attention机制_attention机制 nlp
- 42024年,CSDN积分怎么获取_csdn积分在哪里兑换
- 5SAP ABAP开发过程中内表的概念及操作详解之三_table函数
- 6win11设置mysql开机自启_windows11设置服务自启动
- 7ARM开发入门
- 8低代码:美味膳食或垃圾食品?
- 9求职面试中如何做好自我介绍?_面试怎么做自我介绍csdn
- 10【权限提升】Linux Kernel 权限提升漏洞 (CVE-2023-32233)_linux kernel权限提升漏洞
一步步教你搭建Kafka开发环境,轻松上手!_kafka 容器化 java程序容器化
赞
踩
一、安装Java环境
1.1、下载Linux下的安装包
(1)登录官网下载地址https://www.oracle.com/java/technologies/downloads/#java8,找到对应压缩包。
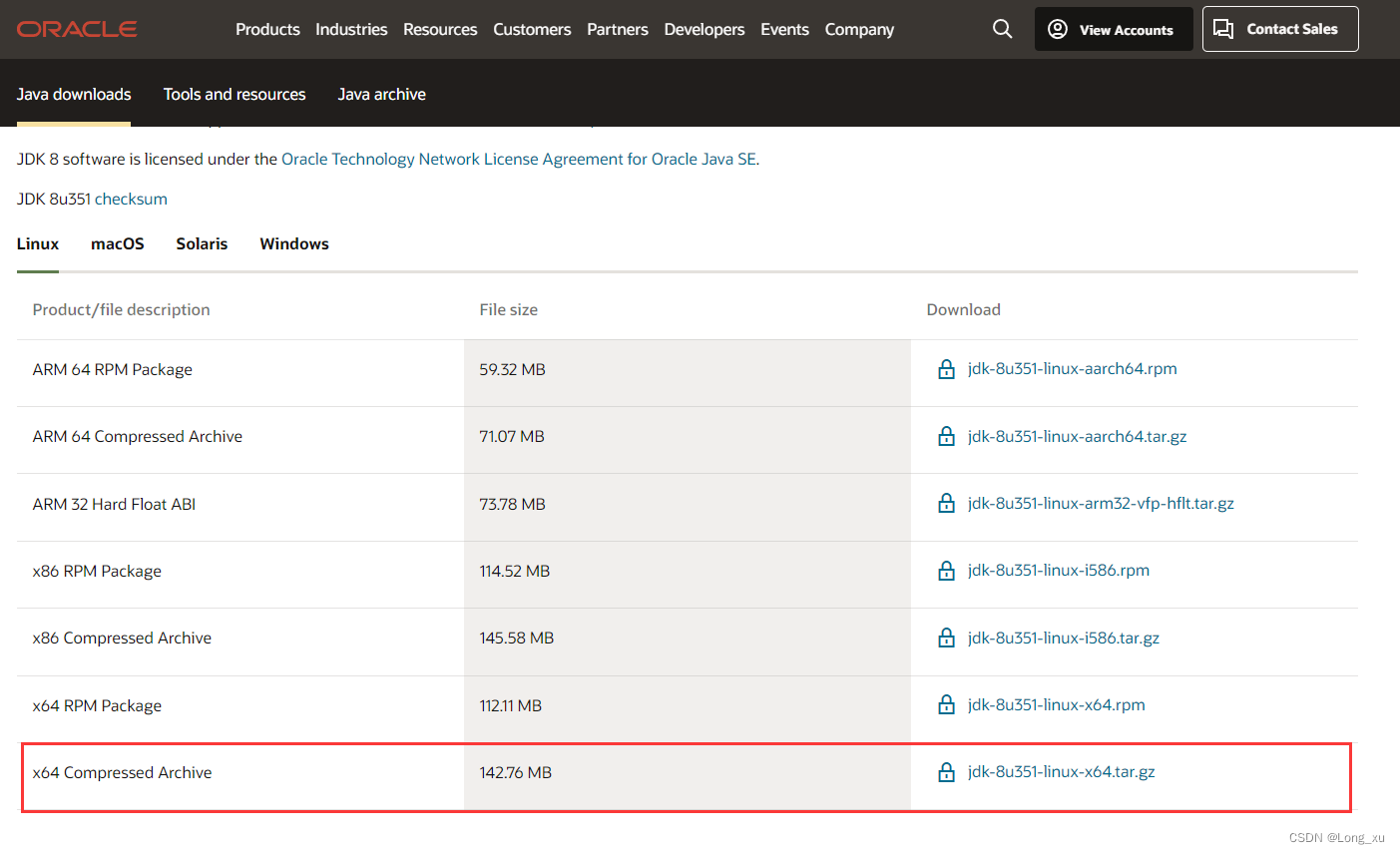
(2)点击下载链接弹出如下窗口,勾选协议,继续点击下载链接。
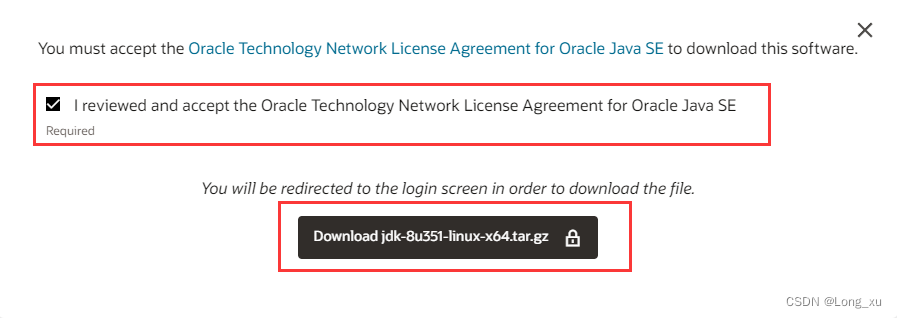
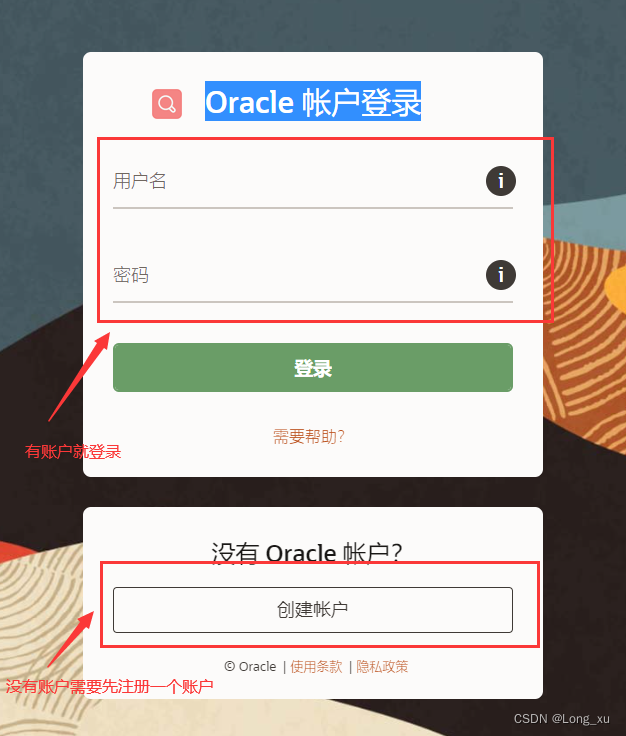
(3)需要登录账户。如果已经有账户则直接登录;没有就需要注册一个账户。登录账户后就可以直接下载了。
1.2、解压缩安装包
tar -zxvf jdk-8u352-linux-x64.tar.gz
- 1
解压后的文件夹为jdk1.8.0_351,进入文件夹和查看文件:
cd jdk1.8.0_351
ls
- 1
- 2
可以看到bin目录:
bin include jmc.txt
legal LICENS README.html
src.zip THIRDPARTYLICENSEREADME.txt COPYRIGHT
javafx-src.zip jre lib
man release THIRDPARTYLICENSEREADME-JAVAFX.txt
- 1
- 2
- 3
- 4
- 5
1.3、解压后的文件移到/usr/lib目录下
(1)将解压后的文件移到/usr/lib目录下:
sudo mkdir /usr/lib/jdk
- 1
(2)将解压的jdk文件移动到新建的/usr/lib/jdk目录下来:
sudo mv jdk1.8.0_351 /usr/lib/jdk/
- 1
- 2
1.4、配置java环境变量
这里是将环境变量配置在etc/profile,即为所有用户配置JDK环境。
(1)使用命令打开/etc/profile文件:
sudo vim /etc/profile
- 1
(2)在末尾添加以下几行:
#set java env
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_351
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
- 1
- 2
- 3
- 4
- 5
(3)执行命令使修改立即生效:
source /etc/profile
- 1
(4)测试安装是否成功:
java -version
- 1
出现版本号说明安装成功。
java version "1.8.0_351"
Java(TM) SE Runtime Environment (build 1.8.0_351-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.351-b10, mixed mode)
- 1
- 2
- 3
- 4
二、 Kafka的安装部署
2.1、下载安装Kafka
(1)下载Kafka。
wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
- 1
(2)解压缩Kafka。下载的kafka是已经编译好的程序,只需要解压即可得到执行程序。
tar -zxvf kafka_2.11-2.0.0.tgz
- 1
(3)进入kafka目录,以及查看对应的文件和目录。
cd kafka_2.11-2.0.0
ls
- 1
- 2
bin:为执行程序
config:为配置文件
libs:为库文件
bin config libs LICENSE NOTICE site-docs
- 1
- 2
2.2、配置和启动zookeeper
Kafka 3.0开始将zookeeper剥离出去了,下载的版本是2.11程序里自带了zookeeper,kafka自带的Zookeeper程序脚本与配置文件名与原生Zookeeper稍有不同。
kafka自带的Zookeeper程序使用bin/zookeeper-server-start.sh,以及bin/zookeeper-server-stop.sh来启动和停止Zookeeper。
# 启动zookeeper:
zookeeper-server-start.sh
# 停止zookeeper:
zookeeper-server-stop.sh
- 1
- 2
- 3
- 4
- 5
kafka依赖于zookeeper来做master选举以及其他数据的维护。
在config目录下,存在一些配置文件:
zookeeper.properties
server.properties
- 1
- 2
因此可以通过下面的脚本来启动zookeeper服务,当然,也可以自己独立搭建zookeeper的集群来实现。这里我们直接使用kafka自带的zookeeper。
cd bin/
# 前台运行:
sh zookeeper-server-start.sh ../config/zookeeper.properties
# 后台运行:
sh zookeeper-server-start.sh -daemon ../config/zookeeper.properties
- 1
- 2
- 3
- 4
- 5
- 6
启动zookeeper,默认端口为:2181,可以通过命令lsof -i:2181 查看zookeeper是否启动成功。
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 128387 fly 96u IPv6 2591167 0t0 TCP *:2181 (LISTEN)
- 1
- 2
- 3
2.3、启动和停止Kafka
(1)修改server.properties(在config目录), 增加zookeeper的配置,这里只是本地的配置,如果是另一台机器运行zookeeper,要配置对应的ip地址。
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(2)启动kafka(kafka安装路径的bin目录下执行),默认启动端口9092。
sh kafka-server-start.sh -daemon ../config/server.properties
- 1
(3)停止kafka(kafka安装路径的bin目录下执行)。
sh kafka-server-stop.sh -daemon ../config/server.properties
- 1
总结
学习在Linux环境下搭建Kafka开发环境的详细步骤。从安装Java环境到配置和启动Kafka服务,每个步骤都得到了清晰的解释和演示。搭建Kafka开发环境是实际应用和开发工作的基础,通过本文能够顺利完成Kafka环境的搭建,为后续的数据流处理和应用开发奠定坚实的基础。


